10._V$SQL
2012.04.09 11:38
o. 일반적으로 전체 어플리케이션 물량 중 상위 2%에 해당하는 프로그램이 전체 시스템 부하의 70%를 차지한다.
그리고 상위 14%가 전체 부하량의 90%를 차지한다.
그림 1
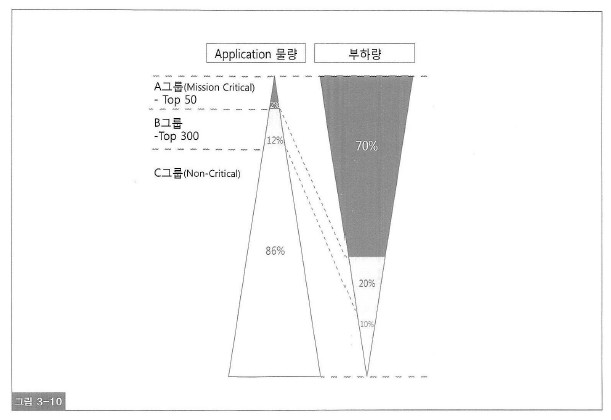
잘 알려진 파레토 최적의 법칙 또는 리처드 코치의 80/20 법칙은 튜닝 대상을 선정하는 데 있어서 동일하게 적용할 수 있다.
주기적으로 사용되는 상위 10% 이내의 프로그램에 대한 튜닝을 통해 성능 고도화를 이룰 수 있다.
v$sql은 집중 튜닝이 필요한 SQL을 선정하고 튜닝 전후 성능 향상도를 비교할 목적으로 자주 사용된다.
o. v$sql은 라이브러리 캐싱되어 있는 각 Child 커서에 대한 수행 통계를 보여준다.
v$sqlarea는 Parent 커서에 대한 수행통계를 나타내며 많은 컬럼이 v$sql을 group by 한 값이다.
v$sql은 쿼리가 수행을 마칠때마다 갱신되며 오래 수행되는 쿼리는 5초마다 갱신된다.
그림 2

v$sql의 수치는 모두 통계값으로 보이는 수치 그대로의 의미보다는 SQL 수행 횟수로 나눈 평균값으로 분석해야 의미가 있다.
그림 3
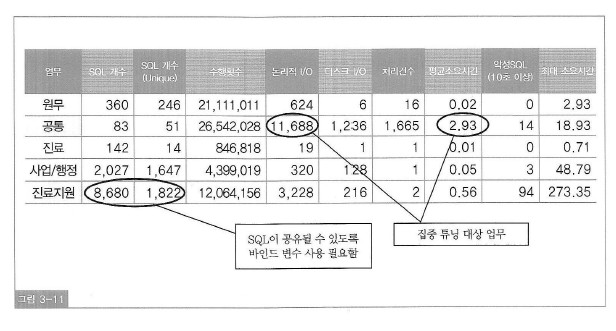
위 그림은 쿼리 수행 결과 예시이다.
세번째 컬럼, SQL개수는 SQL 문자열 중 선행 100개 문자가 같으면 동일 SQL로 간주하고 집계한다.
(같은 SQL인데도 바인드 변수를 사용하지 않으면 Literal 상수 값 별로 오라클이 다른 sql_id를 부여해 SQL개수가
무수히 많은 것으로 집계하는 오류를 보완하기 위함이다.)
진료지원- 라이브러리 캐시에 로드된 총 SQL개수가 8680개인데 유니크하게는 1822개이므로
바인드 변수를 사용하지 않아 각각 하드파싱을 발생시켜 캐시에 로드된 SQL 비중이 매우 높다.
->SQL이 공유될수 있도록 바인드 변수를 사용하는 방식으로 프로그램 수정을 요청해야 한다.
공통-한번 수행할 때의 평균 논리적 IO가 11688개로 매우 높다. 많은 논리적 IO와 마찬가지로 디스크 IO도 많고
쿼리 평균 소요시간도 높게 나타단다. 게다가 SQL개수는 가장 적지만 수행 횟수는 가장 많다.
->가장 먼저 튜닝해야 하는 대상으로 선정해야 한다.
o.v$sql 활용
v$sql_plan을 통해 실행 계획을 확인하고 v$sql_plan_statistics를 통해 row source별 수행 통계를 확인할 수 있다.
또한 v$sql_bind_capture를 통해 정해진 기간에 한번씩 샘플링한 바인드 변수 값을 확인할 수 있다.
AWR에 아래와 같은 정보들을 주기적으로 저장한다.
그림 4

스냅샷 시점에 캐시에 남아있던 커서의 수행 통계만 저장된다. 또한 캐시에 남아 있더라도 Top SQL 만 수집한다.

o. Colored SQL
Top SQL에 포함되지 않더라도 사용자가 명시적으로 지정한 커서의 수행통계가 AWR에 주기적으로 수집되도록 마크하는 기능이다.
지정하는 방법은 아래와 같다.
그림 5

대상 목록은 아래와 같이 확인가능하다.
그림 6
단, 이 기능을 사용하더라도 스냅샷 시점에 캐시에서 밀려나고 없는 SQL 정보까지 저장할 수 는 없다.
대상 목록에서 삭제할때는 아래와 같이 한다.

댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 66 | 부록 | 남송휘 | 2012.06.06 | 2426 |
| 65 | 4장._라이브러리_캐시_최적화_원리 | dasini | 2012.04.09 | 2721 |
| 64 | 3장._오라클_성능_관리 | 남송휘 | 2012.03.26 | 2896 |
| 63 | 2._AutoTrace | 남송휘 | 2012.03.26 | 2920 |
| 62 | 11._End-To-End_성능관리 | 남송휘 | 2012.04.09 | 3032 |
| 61 | 6._페이지_처리의_중요성 | 남송휘 | 2012.05.15 | 3118 |
| 60 | 11._Shared_Pool | 박영창 | 2012.03.19 | 3163 |
| 59 | 6._V$SYSTEM_EVENT | 시와처 | 2012.04.01 | 3311 |
| 58 |
3._데이터베이스_Call이_성능에_미치는_영향
| 시와처 | 2012.05.13 | 3382 |
| 57 | 8._PLSQL_함수_호출_부하_해소_방안 | 남송휘 | 2012.05.21 | 3457 |
| 56 |
4._Prefetch
| 남송휘 | 2012.05.21 | 3596 |
| 55 | 1._SQL과_옵티마이저 | dasini | 2012.04.06 | 3612 |
| 54 | 11._Static_SQL_구현을_위한_기법들 | dasini | 2012.05.07 | 3735 |
| 53 | 4._Array_Processing_활용 | 시와처 | 2012.05.14 | 3769 |
| 52 |
6장._IO_효율화_원리
| 정찬호 | 2012.05.22 | 3807 |
| 51 |
1._블록_단위_IO
| 정찬호 | 2012.05.22 | 3925 |
| 50 |
3._Single_Block_vs._Multiblock_IO
| 정찬호 | 2012.05.23 | 3960 |
| 49 |
1._Library_Cache_Lock_Pin
| 남송휘 | 2012.05.21 | 3964 |
| 48 |
3._Deterministic_함수_사용_시_주의사항
| 정찬호 | 2012.05.29 | 4091 |
| 47 | 8._IO_효율화_원리 | 운영자 | 2012.06.06 | 4121 |