3._Deterministic_함수_사용_시_주의사항
2012.05.29 03:03
o. Deterministic의 목적
- 함수의 입력 값이 같다면 출력 값도 항상(현재 뿐만 아니라 미래에도) 같음을 선언하는 의미 (10gR2의 신 기능인 캐싱효과 제외)
o. 캐싱효과를 위해 함부로 사용하면 안된다?
- 성능도 중요하지만, 잘못 사용했을때 데이터 일관성을 해칠 수 있다. 이 키워드가 함수의 일관된 결과를 보장해주지는 않는다.
o. 아래 함수를 Deterministic으로 선언하면 어떻게 될까? 함수의 입력값이 같을 때 출력 값이 같을까?
SQL> CREATE OR REPLACE FUNCTION LOOKUP(L_INPUT NUMBER) RETURN VARCHAR2 DETERMINISTIC
AS
L_OUTPUT LOOKUPTABLE.VALUE%TYPE;
BEGIN
SELECT VALUE INTO L_OUTPUT FROM LOOKUPTABLE WHERE KEY=L_INPUT;
RETURN L_OUTPUT;
END;
/
- 위 함수를 Deterministic으로 선언하면 안된다. 동일 입력 값에 대해 동일 출력 값을 보장할 수 없다.
- LookupTable에서 value 값이 갱신될 수 있기 때문이며 Deterministic으로 선언했는데 실제 내용이 그렇지 않을 경우 문제가 발생 할 수 있다.
- LookupTable의 value 컬럼 값이 바뀐다면 위 함수를 사용하는 쿼리들이 시점에 따라 서로 다른 값을 출력하게 되며 쿼리 결과를 Fetch하는 도중에도 다른 갑슬 출력하게 된다.
- 이것은 함수를 사용하는 한, Deterministic과 무관하며 Deterministic을 쓴다면 캐싱 효과는 Fetch Call 내에서만 유효하므로 새로운 Fetch Call 시점에 다시 쿼리하면서 이런 현상이 발생하게 된다.
- 함수를 스칼라 서브쿼리에 덧입히더라도 읽기 일관성을 완전히 보장받을 수는 없다.
- 스칼라 서브쿼리의 캐싱 효과는 Fecth Call을 넘어서 커서가 닫힐 때까지 유효하지만,
첫 번째 호출이 일어나 캐싱될 때까지의 시간차 때문에 완벽한 문장수준 읽기 일관성을 보장하기 어려운 것이다.
o. LookupTable에 아래와 같이 2개 레코드를 입력한다면
lookup함수에 입력 값으로 1을 사용하든 2를 사용하든 YAMAHA 가 출력된다.
SQL> CREATE TABLE LOOKUPTABLE(KEY NUMBER, VALUE VARCHAR2(100) );
SQL> INSERT INTO LOOKUPTABLE(KEY, VALUE) VALUES(1,'YAMAHA');
SQL> INSERT INTO LOOKUPTABLE(KEY, VALUE) VALUES(2,'YAMAHA');
o. big_table
no=1 레코드가 1000개, no=2 레코드가 1000개 존재한다고 가정.
함수 호출이 no값 순서대로 일어나게 no 컬럼이 선두에 위치한 인덱스 사용 -> 캐시에 최초 (1,YAMAHA)가 캐싱
o. lookup 함수를 호출하는 쿼리는 아래와 같다.
SQL> SELECT /*+ INDEX(T T_NO_IDX) */ (SELECT LOOKUP(T.NO) FROM DUAL)
FROM BIG_TABLE T
WHERE T.NO >0;
o. 아직 no=2인 첫 번째 레코드에 도달하지 않은 상태에서 다른 세션에서 아래 쿼리를 수행하면
이 순간부터 lookup 함수의 출력 값은 YAMAHA2로 바뀐다.
SQL> UPDATE LOOKUPTABLE SET VALUE='YAMAHA'; COMMIT;
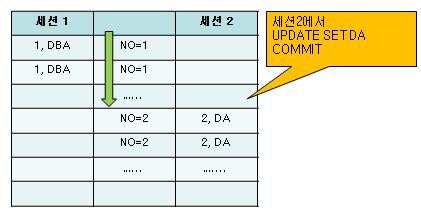
- 이 쿼리가 no=2 인 첫 번째 레코드에 도달하는 순간 lookup 함수가 수행되면서 캐시에는 아래 두 개 엔트리가 저장된다.
{(1,YAMAHA),(2,YAMAHA2)}
- 이제 Query Execution Cache는 일관성 없는 상태가 된다. 쿼리 시작 시점을 기준으로 한다면 아래와 같아야 한다.
{(1,YAMAHA),(2,YAMAHA)}
- 만약 쿼리가 진행 중인 Current 시점을 기준으로 한다면 아래와 같아야 한다.
{(1,YAMAHA2),(2,YAMAHA2)}
- 그런데 실제 캐시에는 어느쪽도 아닌 일관성 없는 값을 가지게 된다. 이러한 일관성 없는 읽기는 사용자 정의 함수를 쓰는 한
완전히 피할 수 없는 현상이며 아래 Join문을 써야 해결된다.
SQL> SELECT L.VALUE
FROM BIG_TABLE T, LOOKUPTABLE L
WHERE L.KEY(+)=T.NO;
SQL> SELECT (SELECT VALUE FROM LOOKUPTABLE WHERE KEY=T.NO)
FROM BIG_TABLE T;
o. 스칼라 서브쿼리는 조인의 또 다른 형태일 뿐이므로 메인 쿼리가 시작되는 시점을 기준으로 블록을 읽기 때문에 읽기 일관성을 보장한다.
o. Deterministic과 FBI(Function-Based Index)의 관계
- FBI는 인덱스가 처음 만들어지거나 엔트리가 추가되는 시점의 함수 출력 값을 저장해두는 원리
- Deterministic으로 선언하지 않은 함수에 대해서는 FBI생성을 거부한다.(강제성)
결론: 캐싱 효과를 얻으려고 함부로 Deterministic으로 선언하는 것은 위험하다.
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 66 | 부록 | 남송휘 | 2012.06.05 | 2708 |
| 65 | 8._IO_효율화_원리 | 운영자 | 2012.06.05 | 4426 |
| » |
3._Deterministic_함수_사용_시_주의사항
| 정찬호 | 2012.05.29 | 4351 |
| 63 | 2._Cursor_Sharing | 운영자 | 2012.05.28 | 6276 |
| 62 | 7._Result_캐시 | 운영자 | 2012.05.27 | 4426 |
| 61 |
3._Single_Block_vs._Multiblock_IO
| 정찬호 | 2012.05.22 | 4229 |
| 60 |
2._Memory_vs._Disk_IO
| 정찬호 | 2012.05.22 | 4446 |
| 59 |
1._블록_단위_IO
| 정찬호 | 2012.05.22 | 4211 |
| 58 |
6장._IO_효율화_원리
| 정찬호 | 2012.05.22 | 4085 |
| 57 |
1._Library_Cache_Lock_Pin
| 남송휘 | 2012.05.21 | 4290 |
| 56 |
6._RAC_캐시_퓨전
| 남송휘 | 2012.05.21 | 17797 |
| 55 | 5._Direct_Path_IO | 남송휘 | 2012.05.21 | 7932 |
| 54 |
4._Prefetch
| 남송휘 | 2012.05.21 | 3889 |
| 53 | 8._PLSQL_함수_호출_부하_해소_방안 | 남송휘 | 2012.05.21 | 3773 |
| 52 | 5._Fetch_Call_최소화 [1] | 박영창 | 2012.05.15 | 6065 |
| 51 |
7._PLSQL_함수의_특징과_성능_부하
| 남송휘 | 2012.05.14 | 6935 |
| 50 | 6._페이지_처리의_중요성 | 남송휘 | 2012.05.14 | 3379 |
| 49 | 4._Array_Processing_활용 | 시와처 | 2012.05.13 | 4043 |
| 48 |
3._데이터베이스_Call이_성능에_미치는_영향
| 시와처 | 2012.05.13 | 3645 |
| 47 |
10._Dynamic_SQL_사용_기준
| 남송휘 | 2012.05.07 | 4556 |