6. 바인드 변수의 부작용과 해법
2010.06.27 23:06
6.바인드 변수의 부작용과 해법
SQL Parsing
▼ (parsed SQL)
Optimization
▼ (Execution Plan)
Row_Source Generation
▼ (Row-Source)
Execution
바인드 변수 사용 시
- 최초 수행 시 : 최적화를 거친 실행계획을 캐시에 적재
- 실행시점 : 캐시의 실행계획을 그대로 가져와 값을 다르게 바인딩하면서 반복 재사용
※ <point> 바인딩 시점 (최적화 이후인 실행시점)
→ SQL 최적화 시점에 조건절 컬럼의 데이터 분포도(컬럼 히스토그램) 활용을 못함
→ 옵티마이저는 평균 분포를 가정한 실행계획을 생성
→ 컬럼의 데이터 분포가 균일 시 문제가 없음,
그렇지 않을 시 시행 시점에 바인딩 되는 값에 따라 최적이 아닌 실행계획 수행가능
→ 등치(=) 조건이 아닌 부등호나 범위기반 검색 조건 시 고정 된 규칙을 사용하여 더 부정확한 예측의 실행계획 생성 가능
▼ 표에 따라 변경되는 선택도 적용 계산 : 1~4번 선택도 5%, 5~8번
선택도 0.25%
| no | 범 위 조 건 | 선택도 | no | 범 위 조 건 | 선택도 |
1 | 번호 > :
NO | 5% | 5 | 번호 between :NO1 and :NO2 | 0.25% |
2 | 번호 < : NO | 5% | 6 | 번호 > : NO1 and 번호 <= :NO2 | 0.25% |
3 | 번호 >= : NO | 5% | 7 | 번호 >= : NO1 and 번호 <= :NO2 | 0.25% |
4 | 번호 <= : NO | 5% | 8 | 번호 > : NO1 and 번호 < :NO2 | 0.25% |
카디널리티(출력 예상 건수) = 선택도 x 전체 레코드 수
평균 분포를 가정한 옵티마이저 예상
예상 값
바인드 변수를 적용한 테스트 결과
테 스트 결과 화면
옵티마이저 실행계획과 실제 결과의 차이가 발생
사용자의 입력값에 따라 결과가 크게 다를 수 있지만 옵티마이저가 알 수 없음
상수 조건식을 적용한 테스트 결과
테스트 화면
옵 티마이저 실행계획과 실제 결과의 차이가 미미
(1) 바인드 변수 Peeking : Peek(몰래 엿보기) - 바인드 변수의 부작용을 극복하기 위해 9i부터 도입
- SQL 첫 번째 수행 시 하드파싱 될 때 바인드 변수 값을 살짝 훔쳐보고, 그 값에 대한 컬럼 분포를 이용해 실행계획 결정
- 다른 DBMS에서도 같은 기능 제공 (ex. SQL Server 의 'Parameter Sniffing') sniff : 냄새를 맡다, 냄새로 알아채다
문제점 - 아파트 매물 사례로 예시
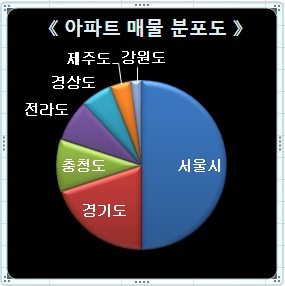 선택도가 높은 데이터(예시의 서울시, 경기도 해당)를 인덱스를 경유해 액세스 시
선택도가 높은 데이터(예시의 서울시, 경기도 해당)를 인덱스를 경유해 액세스 시
성능이 오히려 더 느려짐
select * from 아파트 매물 where 도시 = :CITY;
<상황 1> 쿼리를 처음 수행되는 시점에 바인드 변수의 값이
선택도가 높은 데이터(서울시, 경기도)일 경우
1. 옵티마이저가 Full Scan 실행계획 수립
2. Full Scan 실행계획이 캐시에 적재
3. 캐시에 실행계획이 남아있는 동안 선택도가 낮은 데이터(제주도, 강원도)의
쿼리 수행도 Full Scan 처리
<상황 2> 쿼리를 처음 수행되는 시점에 바인드 변수의 값이 선택도가 낮은 데이터(제주도)일 경우
1. 옵티마이저가 Index Range Scan 실행계획 수립
2. Index Range Scan 실행계획이 캐시에 적재
3. 캐시에 실행계획이 남아있는 동안 선택도가 높은 데이터(서울, 경기도)의 쿼리 수행도 Index Range Scan 처리
☞ 처음 쿼리 수행에 따라 캐시에 적재된 실행계획이 달라 사용자가 느려진 성능으로 불편함 ↑
→ 해당 쿼리 수행빈도가 낮아 캐시에서 자주 밀려날 경우(LRU 알고리즘) 하루에도 실행계획이 수시로 변경
- Peeking 시 히스토그램의 정보 활용
- 9i 까지는 dbms_stats 패키지의 기본 설정이 히스토그램을 생성하지 않음
- 10g부터 dbms_stats 기본 설정이 히스토그램 생성 여부를 오라클이 판단
∴ 9i에 비해 더 많은 컬럼에 히스토그램이 생성됨 ☞ 바인드 변수 Peeking에 의한 폐해가 더 나타남
- Explain Plan 명령을 통해 실행계획을 확인 시 바인드 값을 제공하지 않기때문에 옵티마이저는 바인드 값을 Peeking 할 수 없음
→ 즉, 평균 분포를 가정한
실행계획으로 그 실행계획의 결과를 가지고 배포한 SQL이 실제 실행시점에서
바인드 변수 Peeking을 발생하여 다른 방식으로 수행 가능
※ 현재 대부분 운영 시스템에서는 바인드 변수 Peeking 기능을 비활성화 시킨 상태에서 운영
alter system set "_optim_peek_user_binds" = FALSE;
(2) 적응적 커서 공유(Adaptive Cursor Sharing) - 바인드 변수 Peeking 부작용 개선을 위해 11g에 추가된 기능
- 입력된 바인드 변수 값의 분포에 따라 다른 실행계획 사용
1. 쿼리 처음 수행 시점 선택도가 높은 '서울시' 입력 ☞ 테이블 Full Scan 실행계획 수립 (1번 커서 생성)
이후 '서울시' 입력의 쿼리가 재실행시 1번 커서 반복 재사용
2. 선택도가 매우 낮은 '제주도'입력 시 컬럼 히스토그램 확인 ☞ 인덱스를 이용하는 새로운 실행계획 생성(2번 커서 생성)
3. '서울시' 와 유사한 선택도의 '경기도' 입력 시 히스토그램 확인 ☞ 1번 커서 사용
4. '제주도' 와 유사한 선택도의 '강원도' 입력 시 히스토그램 확인 ☞ 2번 커서 사용
- 적응적 커서 공유 관련 수행 통계 관찰할 수 있는 뷰
v$sql_cs_statistics
v$sql_cs_histogram
v$sql_cs_selectivity
- 기본적으로 조건절 컬럼에 히스토그램이 생성되어있어야 적응적 커서 공유 작동
→ 현재 입력된 바인드 값을 처리할 커서의 캐싱 유무 확인
→ 캐시에 해당 커서가 없을 시 하드파싱을 통해 새로운 실행계획 생성
→ 새로운 커서가 기존 캐싱된 커서의 실행계획과 같을 시 그 중 하나만 사용, 나머지는 버림 (중복 실행계획 커서 생성 방지)
※ 새로운 기능에 대한 주의
실제 운영 환경에서 직접 사용 시 개선 효과도 있지만 미처 생각지 못한 부작용이 발생 가능
→ 위의 예제를 보면 2번에 해당되는 '제주도' 처음 입력 시 새로운 실행계획(2번 커서)을 바로 만들지 않고
기존의 커서(1번 커서)를 그대로 사용해보고 성능이 나쁘다고 판단될 시 Bind Aware 모드로 전환 되어
새로운 실행계획(2번 커서)을 생성함
→ 스스로 학습하는 옵티마이저(Self-Learning Optimaizer) 개념 도입의 사례
학습을 위해 기존 커서를 사용하여 Full Scan 처리를 기다려야함
(3) 입력 값에 따라
SQL 분리
인덱스 액세스 경로로서 중요하고 조건절 컬럼의 데이터 분포가 균일하지 않은 상황에서
바인드 변수 사용에 따른 부작용을 피하기
위해 바인딩되는 값에 따라 실행계획을 분리
▼ Bad Example
select /* + Full(a) */ *
from 아파트 매물 a
where :CITY in ('서울시', '경기도')
and 도시 = :CITY
union all
select /* +Index(a IDX01) */ *
from 아파트 매물 a
where :CITY not in ('서울시', '경기도')
and 도시 = :CITY
- OLTP 시스템에서 Union all을 이용해 SQL을 지나치게 길게 작성 시 오히려 라이브러리 캐시 효율이 떨어짐
∵ 1. 결합 sql 수만큼 옵티마이저가 최적화 작업
2. Shared Pool 공간 차지
3. 파싱 시 긴 sql 문 Syntax 체크, Semantic 체크 과정
반복
→ Parse 단계에서 CPU 과소비 (교재의 예 Parse 단계가 전체 시간의 78% 소비)
- 분기된 SQL이 조건에 의해 제외되어 실행되지 않는 것이 아니라 I/O만 발생되지 않을 뿐 실제 실행 작업을 함, 네트워크를 통한
메시지 전송량도 증가
☞ 배치 프로그램 DDS 시스템일 시 상관없지만 OLTP 시스템에서는 Union all
보다 아래처럼 애플리케이션 단에서 조건에 따라 SQL 분기
▼ Good Example
IF :CITY in ('서울시', '경기도') THEN
select /* + Full(a) */ *
from 아파트 매물 a
where 도시 = :CITY;
ELSE
select /* +Index(a IDX01) */ *
from 아파트 매물 a
where 도시 = :CITY;
END IF;
(4) 예외적으로, Litreal 상수값 사용
- 입력값에 따라 SQL를 분리하는 방법이 모두 적용될 수 없음
- 조건절 컬럼의 값 종류(Distinct
Value)가 소수 일 시 바인드 변수보다 Litreal 상수가 나을 수 있음
∵ 하드파싱 부하 미미,
옵티마이저가 더 나의 선택을 할 가능성이 있음, 범위 검색 시 최적화 측면에서 유리함
- 예외적으로
Litreal 상수값을 적용해야지, 단순히 바인드 변수 정의가 번거롭다해서 모두 Litreal 상수 값 사용하는것도 고려
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 47 |
2. 트랜잭션 수준 읽기 일관성
| 휘휘 | 2010.06.06 | 20627 |
| 46 | 3. 비관적 vs. 낙관적 동시성 제어 | 휘휘 | 2010.06.06 | 8636 |
| 45 | 4. 동시성 구현 사례 | 토시리 | 2010.06.06 | 11344 |
| 44 |
5. 오라클 Lock
| 휘휘 | 2010.06.06 | 26935 |
| 43 |
7. Response Time Analysis 방법론과 OWI
| balto | 2010.06.13 | 8510 |
| 42 | 8. Statspack / AWR | balto | 2010.06.13 | 13177 |
| 41 | 9. ASH(Active Session History) | 실천하자 | 2010.06.13 | 16139 |
| 40 | 11. End-To-End 성능관리 | 휘휘 | 2010.06.13 | 8525 |
| 39 |
12. 데이터베이스 성능 고도화 정석 해법
| 휘휘 | 2010.06.13 | 7516 |
| 38 |
5. V$SYSSTAT
[1] | 토시리 | 2010.06.13 | 10186 |
| 37 | 10. V$SQL | 실천하자 | 2010.06.13 | 13024 |
| 36 | 6. V$SYSTEM_EVENT | 토시리 | 2010.06.14 | 6909 |
| 35 |
3. 라이브러리 캐시 구조
| balto | 2010.06.27 | 10191 |
| 34 |
4. 커서 공유
| balto | 2010.06.27 | 9573 |
| 33 |
1. SQL과 옵티마이저
| 휘휘 | 2010.06.27 | 7593 |
| 32 |
2. SQL 처리과정
| 휘휘 | 2010.06.27 | 21983 |
| 31 | 4장. 라이브러리 캐시 최적화 원리 | 휘휘 | 2010.06.27 | 7310 |
| 30 | 5. 바인드 변수의 중요성 | 실천하자 | 2010.06.27 | 12055 |
| » |
6. 바인드 변수의 부작용과 해법
| 실천하자 | 2010.06.27 | 15268 |
| 28 |
7. 세션 커서 캐싱
| 토시리 | 2010.06.29 | 10911 |