3_장_요약
2011.10.13 08:25
1절 관계형 데이터베이스 개요
1) 개요
정의 : 특정 기업이나 조직 또는 개인이 필요에 의해(ex: 부가가치가 발생하는) 데이터를 일정한 형태로 저장해 놓은 것.
2) SQL(Structured Query Language)
ü 데이터정의(DDL)
ü 데이터조작(DML)
ü 데이터제어(DCL)
TABLE은 어느 특정한 주제와 목적으로 만들어지는 일종의 집합이다.
데이터를 저장하는 객체(Object)로서 관계형 데이터베이스의 기본 단위
데이블과 데이블이 어떤 의미의 연관성이나 관계를 가지며 이와 같은 관계의 의미를 직관적으로 표현하는 수단이다.
ERD의 구성 요소는 엔터티(Entity), 관계(Relationship), 속성(Attribute) 3가지
2절 DDL(DATA DEFINITION LANGUAGE)
1) 데이터유형
- 숫자타입
- 문자열타입
- 컬럼이 가지고 있는 데이터유형(Character(s), varchar(s), numeric, datatime)
2) CREATE TABLE
가. 테이블과 칼럼 정의 : 후보키중에 하나를 선정하여 기본키 칼럼으로 지정
나. CREATE TABLE 구문
CREATE TABLE
CREATE TABLE 테이블이름 (
칼럼명1 DATATYPE DEFAULT 형식,
칼럼명2 DATATYPE DEFAULT 형식,
칼럼명3 DATATYPE DEFAULT 형식
) ;
다. 제약조건(CONSTRAINT)
데이터의 무결성을 유지하기 위한 데이터베이스의 보편적인 방법
- PRIMARY KEY(기본키)
- UNIQUE KEY(고유키)
- NOT NULL
- CHECK
- FOREIGN KEY(외래키)
라. 생성된 테이블 구조 확인
DESCRIBE PLAYER;
마. SELECT 문장을 통한 테이블 생성 사례
l SELECT 문장을 활용해서 테이블을 생성할 수 있는 방법(CTAS: Create Table ~ As Select ~)
3) ALTER TABLE
가. ADD COLUMN
나. DROP COLUMN
다. MODIFY COLUMN
RENAME COLUMN
라. DROP CONSTRAINT
마. ADD CONSTRAINT
4) RENAME TABLE
<< ORACLE >>
RENAME 변경전 테이블명 TO 변경후 테이블명;
<<SQL SERVER>>
sp_rename 변경전 테이블명, 변경후 테이블명;
5) DROP TABLE
DROP TABLE 테이블명 CASCADE CONSTRAINT;
6) TRUNCATE TABLE
TRUNCATE TABLE PLAYER;
3절 DML(DATA_MANIPULATION_LANGUAGE)
- DML이란?
l 자료들을 입력, 수정, 삭제, 조회하는 명령어
- DML 종류
l INSERT
l UPDATE
l DELETE
l SELECT
4절 TCL(TRANSACTION CONTROL LANGUAGE)
- 트랜잭션이란?
- 데이터베이스의 논리적 연산단위
- 밀접히 관련되어 분리될 수 없는 한 개 이상의 데이터베이스 조작을 의미한다.
- 하나의 트랜잭션에는 하나 이상의 SQL 문장이 포함된다.
- 트랜잭션은 분할할 수 없는 최소의 단위이다.
- 따라서, 전부 적용하거나 전부 취소
- 즉, 트랜잭션은 ALL OR NOTHING
- 트랜잭션을 컨트롤하는 TCL (TRANSACTION CONTROL LANGUAGE)
- 커밋(COMMIT) : 올바르게 반영된 데이터를 데이터베이스에 반영시키는 것
- 롤백(ROLLBACK) : 트랜잭션 시작 이전의 상태로 되돌리는 것
- 저장점(SAVEPOINT)
- SAVEPINT(저장점)이란?
- 저장점을 정의하면 롤백할때 전체 롤백이 아닌 일부만 롤백할 수 있다.
- 복수의 저장점을 정의할 수 있다.
- 동일 이름으로 저장점을 저장시 나중에 정의한 저장점이 유효하다.
5절 WHERE 절
l 조건절에 제한을 두어 원하는 자료만을 조회
SELECT [DISTINCT/ALL] 컬럼명 [ALIAS명]
FROM 테이블명
WHERE 조건식;
l 조건식 구성
- 칼럼(Column)명
- 비교연산자
- 문자, 숫자, 표현식
- 비교 칼럼명(JOIN 사용시)
<< 연산자의 종류 >>
가. 비교연산자
나. SQL연산자
다. 논리연산자
라. 부정비교연산자
마. 부정SQL연산자
바. ROWNUM, TOP
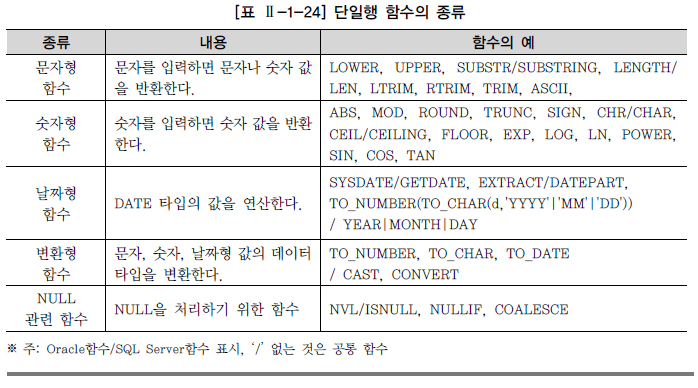
6절 함수(FUNCTION)
l 내장함수(Built-in Function)
l 사용자정의 함수(User-Defined Function)
<<단일행 함수의 종류>>
7절 GROUP BY, HAVING 절
집계함수(Aggregate Function)
- 여러 행들의 그룹이 모여서 그룹당 단 하나의 결과를 돌려주는 함수
- GROUP BY 절은 행들을 소그룹화
- SELECT 절, HAVING 절, ORDER BY 절에 사용
Group by 절
- 작은 그룹으로 분류하여 소그룹에 대한 항목별로 통계 정보를 얻을 때
Having 절
- HAVING 조건절에는 GROUP BY 절에서 정의한 소그룹의 집계 함수를 이용한 조건을 만족하는 내용 출력
CASE 표현을 활용한 월별 데이터 집계
- 모델링의 제1정규화로 인해 반복되는 칼럼의 경우 구분 칼럼을 두고 여러 개의 레코드로 만들어진 집합을, 정해진 칼럼 수만큼 확장해서 집계보고서를 만드는 기법.
집계 함수와 NULL 처리
- 다중행 함수에 NVL함수(NULL 처리)를 사용하면 부하 발생
- CASE 표현 사용시는 ELSE 절을 생략하면 Default 값이 NULL
8절 GROUP BY, HAVING 절
가. ORDER BY 절
- SQL 문장으로 조회된 데이터들을 특정 칼럼을 기준으로 정렬
나. SELECT 문장 실행 순서
|
가. 5. SELECT 칼럼명 ALIAS명 나. 1. FROM 테이블명 다. 2. WHERE 조건식 라. 3. GROUP BY 칼럼(Column)이나 표현식 마. 4. HAVING 그룹조건식 바. 6. ORDER BY 칼럼(Column)이나 표현식; |
1. 발췌 대상 테이블을 참조한다. (FROM)
2. 발췌 대상 데이터가 아닌 것은 제거한다. (WHERE)
3. 행들을 소그룹화 한다. (GROUP BY)
4. 그룹핑된 값의 조건에 맞는 것만을 출력한다. (HAVING)
5. 데이터 값을 출력/계산한다. (SELECT)
6. 데이터를 정렬한다. (ORDER BY)
9절 조인(JOIN)
가. JOIN 개요
- 두 개 이상의 테이블 들을 연결 또는 결합하여 데이터를 출력
- 일반적인 경우 행들은 PRIMARY KEY(PK)나 FOREIGN KEY(FK) 값의 연관에 의해
- PK, FK의 관계가 없어도 논리적인 값들의 연관만으로 JOIN이 성립
나. EQUI JOIN
- 두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하는 경우에 사용
다. NON EQUI JOIN
- 두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하지 않는 경우에 사용
라. 3개 이상 TABLE JOIN
- WHERE 절에 2개 이상의 JOIN 조건이 필요
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 47 | 5 연습문제 | RYUM | 2014.08.07 | 9547 |
| 46 | 5 연습문제 | RYUM | 2014.08.07 | 7519 |
| 45 | 5_장_요약 | balto | 2011.11.16 | 6994 |
| 44 |
SQL 문제
[2] | balto | 2011.11.15 | 26831 |
| 43 | 제3절_조인_수행_원리 | 노랑배 | 2011.11.10 | 6393 |
| 42 | 제1절_옵티마이저와_실행계획 | 실천하자 | 2011.11.08 | 5289 |
| 41 | 제1절 옵티마이저와 실행계획 | 실천하자 | 2011.11.07 | 6006 |
| 40 | 4_연습문제 | monsterRachel | 2011.11.03 | 10850 |
| 39 | 4_장_요약 | suspace | 2011.11.03 | 6437 |
| 38 | 제6절_윈도우_함수(WINDOW_FUNCTION) | suspace | 2011.10.27 | 20546 |
| 37 | 제8절_절차형_SQL | monsterRachel | 2011.10.27 | 8696 |
| 36 |
제7절_DCL(DATA_CONTROL_LANGUAGE)
| DB지기 | 2011.10.26 | 8533 |
| 35 | 제2절_인덱스_기본4 | balto | 2011.10.24 | 7715 |
| 34 | .. | balto | 2011.10.14 | 4847 |
| 33 | 제1절_표준_조인(STANDARD_JOIN) | 노랑배 | 2011.10.13 | 15674 |
| 32 | 3_연습문제 | DB지기 | 2011.10.13 | 7092 |
| » |
3_장_요약
| DB지기 | 2011.10.13 | 6081 |
| 30 | 제3절_계층형_질의와_셀프_조인 [1] | 실천하자 | 2011.10.12 | 11495 |
| 29 | 제2절_집합_연산자(SET_OPERATOR) [1] | 실천하자 | 2011.10.11 | 13878 |
| 28 |
제5절_그룹_함수(GROUP_FUNCTION)
| balto | 2011.10.08 | 11436 |