05 유형과 카테고리: 데이터의 분류
2013.04.16 02:22
Capter 5. (데이터) 유형과 카테고리 ( 데이터의 분류 )
무수히 많은 데이터/컨텐츠 존재
이에 대한 효율적인 관리 필요, 생물학자들로부터 시작.
이들은 오래전부터 이를 위해 분류(Classification) or 택사노미 사용했음
데이터를 모델링 한다는 것은 현실에 있는 무수히 많은 데이터/컨텐츠들을
- 관련 있는 자료들을 분류하고(묶고)
- 분류한 것들 끼리의 관계성을 정의하고
- 각 자료가 어떤한 분류 속성들을 갖는 것을 명확히 하는 것
이런 모델링에는 3가지 발전 패턴이 있음
- 레벨 1 분류 패턴: 유형 모델링에 초점, 작은 범위 적용
- 레벨 2 분류 패턴: 유형 모델링에 초점, 좀 더 큰 범위 - 유연함 필요한 경우 -에 적용
- 레벨 3 분류 패턴: 카테고리 모델링에 초점. 매우 큰 범위의 유연함 필요한 경우에 적용
분류 모델링 패턴을 이해하가 위해 3가지 개념을 이해할 필요 있음
- 유형(type): 어떤 자료가 갖고 있는 특징을 분류한 것
예) 의류유통 주문 유형: 대리점주문, 직영점주문, 소비자전화주문, 인터넷 주문, 해외주문 등...
- 카테고리: 유형을 좀더 포괄적으로 표한 것, 적절한 체계에 따라 분류
예) 인간에 속한 카테고리: 인종, 성별
- 택사노미: 분류 요소들의 집합과 관계를 포함
어원: taxonomy: '분류하다'라는 'tassein'과 '법, 과학' 이라는 'nomos'의 합성 어원은 그리스어임.
원래는 어원 그대로 살아있는 유기체를 분류하는 과학이란 뜻이지만, 지금은 확장된 의미로서
살아있는 것 뿐만 아니라 무생물, 장소, 사건 등 모든 것을 택소노미 스키마(taxonomy schema)
로 분류한 것이다. 택소노미(taxonomy)는 이미 결정된 체계를 가지고 있으며, 관계형 네트워크
구조 보다는 트리형의 위계적 구조로 나타난다. 예를 들면 포탈이나 웹 사이트에서 카테고리
구조나 사이트 맵은 텍소노미로 데이터를 조직한 것이다.
레벨 1 분류 패턴
[ 이란? ]
- 분류 속성을 단순하게 나열하는 방식, 단순하고 쉬운 분류 모델 방식임
- 엔티티의 속성(컬럼, 필드와 같은 의미) 형태로 표시
[ 어떻게 작동하는가? ]
- 각각의 분류를 엔티티의 속성1, 속성2, ... n 로 표현
- 분류 예시 : 그림 5-2 참조
- 제품분류(Product type); Hardware, Accessory, Software ( not null 분류 )
- 제품군: Disk Drivers, Cases, Memory, Desktop, Laptop 등
- 색분류: Blak, Green, 등 ( null 허용 분류 )
- 제품 생산라인1 분류: 개인용, 개인업무용, 상업용, 상업고급용, 정부용, 정부고급용 등
- 제품 생산라인2 분류: 개인용, 상업용, 정부용
- 등 ....
- Product Line1과 Product Line2는 모델링 설계에서 정규화에 위배됨.
제 1 정규화 위배: 반복된 패턴이 없어야한다.
제 3 정규화 위배: 키가 아닌 컬럼에 의존적이면 안된다.
[ ERD ]

[ 언제 사용하는가? ]
- 매우 단순한 모델이 필요할 경우; 수집과 검증을 바로 바로 할 경우
데이터의 유형을 식별하는 방법으로만 사용할 수 있기 때문
- 프로토타입 구현인 경우
- 어떤 분류들이 있는지 전체를 파악할 경우. 예로 Product Line 참조
- 매우 단순한 형태로 비전문가(현업)과 소통이 가능
- 단순한 속성 - 단순 조회 용도 등 -으로 사용하거나 비정규화가 필요한 경우
[ 이 패턴의 약점은? ]
- 중복 테이터를 가지고 있기 때문에 중요하거나 장기간에 걸쳐 구현될 시스템에 적용 불가
- 유연하지 않다
- 동일한 유형이 여러번 반복된 경우 적용 불가.
- 분류와 관련된 데이터를 관리 할 수 없음
한 분류(Commercial Use)의 시작일, 종료일, 설명 등
- 분류에 대한 비즈니스 룰을 관리할 수 없음
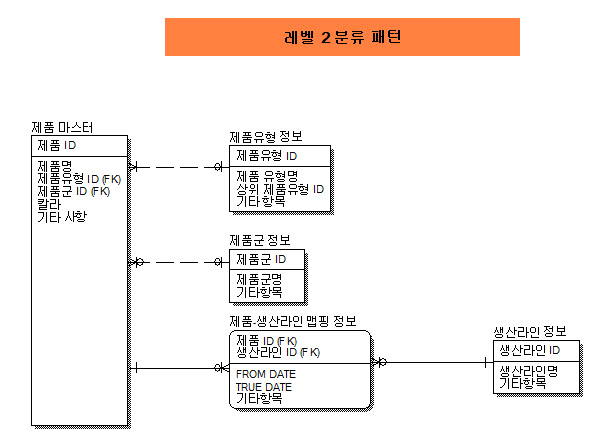
레벨 2 분류 패턴
[ 이란? ]
분류 속성을 엔티티로 표현. 독립적으로 다룰 수 있게 됨
[ 이 패턴이 필요한 이유 ]
분류대상 엔티티와는 독립적으로 유형을 관리 (생성, 삭제, 수정)할 수 있게 됨 -유연성 확보-
[ 어떻게 작동하는가? ] 그림 5-4 참조
- 유형을 엔티티(인스턴스:테이블)로 구성하고 관계를 설정
- case 1. Product Type
1차 분류 - 서브분류: 예제로 Euro-Electronics의 상품 분류 설명한다.
- case 2. Product Family
단순 참조 분류 ; null 허용
Product Family: Disk Drivers, Carrying Cases .... 등, null.
- case 3. Product Line
제귀참조 분류 : Product Line1, 2, ... n인 경우
N:N 설계 방식으로 처리
[ ERD ]
[ 언제 사용하는가? ]
- 현재 일반적인 모델링 방법으로 사용 가능함
- 정규화를 하면서 구체적인 모델링이 필요할 경우
- 분류 데이터를 독립적(엔티티로)으로 관리할 경우
- 각 분류 데이터들이 관계를 갖을 경우
[ 이 패턴의 약점은? ]
- 유연성이 떨어짐
Product Group과 같은 새로운 유형이 나타날 경우 테이블을 변경해야함.
Product 와 Product Type의 릴레이션쉽의 성격이 변경된 경우 등.
즉. 변화, 변경이 많은 데이터(업무) 환경에서는 적합하지 않음
- 데이터 분석에 한계성을 갖음
즉. 제품을 분류하는 모든 분류에 대해 분석하고자 할 경우 (대분류, 중분류, 소분류 각각에 대해)
- 유형을 관리하는 표준화된 방법이 없음
- 많은 방식으로 분류되면 (엔티티의 개수가 많아지면) 관리 어려움이 있음
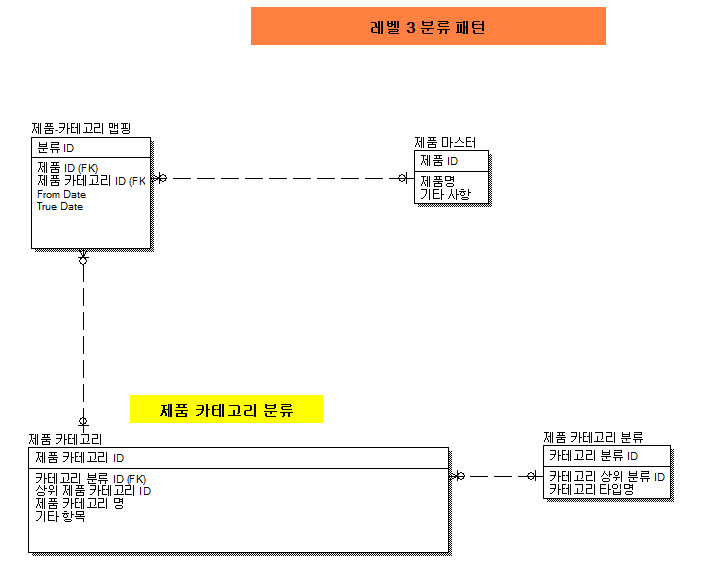
레벨 3 분류 패턴
[ 이란? ]
- 모든 분류 유형을 하나의 엔티티(테이블) 구성하는 것
[ 이 패턴이 필요한 이유 ]
기업의 비즈니스 관리 방식의 변경, 관점의 변경에 따른 분류 방식의 변경 요구됨
=> 새로운 엔티티, 릴레이션쉽을 추가하지 않고 변경할 수 있는 방법 필요
[ 어떻게 작동하는가? ] 그림 5-9 참조
-. 여러 개의 카테고리를 묶을 카테고리 분류 엔티티 구성
-. 개별 카테고리를 관리할 개별 카테고리 엔티티 구성
-. 각 제품별로 개별 카테고리를 연결한 제품-카테고리 릴레이션쉽 엔티티 구성
[ 카테고리 분류 엔티티 ]
카테고리 분류 엔티티: 카테고리의 종류(목록)를 관리함
Product Type(A), Product Family(B), Product Line(C), Product Group(D)
향후 발생할 것 까지 모두 관리함
개별 카테고리 엔티티: 개별 유형을 관리함
상위 유형과 하위 유형 모두를 하나의 엔티티에서 관리함.
상위유형 속성: Hardware(A-01), Software(A-02), Accessory(A-03)
하위유형 속성: A-01:Processor, Storage Deive, ... 02:Gaming software, ... 03:Case ...,
B- Disk Drivers, Laptop Com 등
기타 속성 : from Date, True Date 등
[ 데이터별 카테고리 엔티티 ]
데이터(Product ID)와 카테고리 릴레이션쉽(Category ID)을 관리한다.
- 이전 패턴과 차이점
- 데이터모델 변경 없이 새로운 카테고리 유형을 쉽게 추가, 변경, 삭제할 수 있음
- 카테고리의 계층이나 집합을 추가 가능
- 예) Profit and Loss Reporting Categories
카테고리 분류: Product Family 계약과 Product Line 계열을 분리함
[ ERD ]
[ 언제 사용하는가? ]
- 변경이 많은 업무에 유연한 데이터모델을 설계할 경우
- 엔티티 분류에 다양한 방법을 요구할 경우
- 다양한 카테고리 유형을 관리할 공통 모델을 설계할 경우
- 강력한 분석능력을 제공하기 위해 카테고리를 결할할 경우
[ 이 패턴의 약점은? ]
- 이해하기가 어렵다
- 카테고리간의 다양한 릴레이션쉽을 구현할 수 없다.
- 하나의 자식이 하나의 부모 카테고리만 취할 수 있기 때문에 다양한 유형의 계층과 집합의 표현이
제한된다.
- 유형이 작거나 개수가 고정적이면 이 패턴이 필요 없다.
- 특정 유형의 릴레이션쉽을 관리 할 수 없다.
데이터시물레이션: 패턴 3 데이터 설계.xlsx
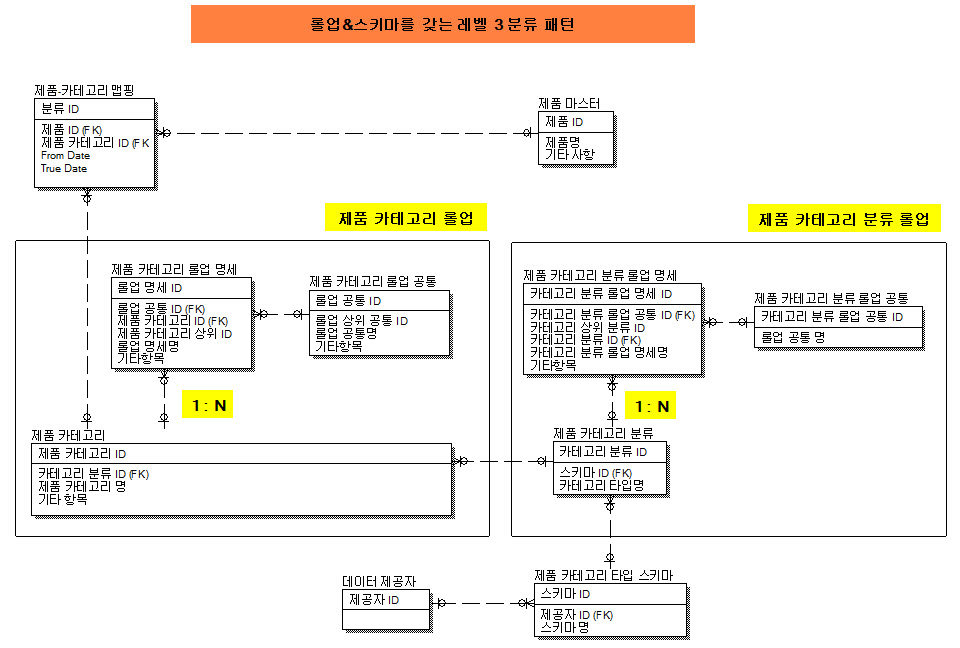
롤업 및 스키마를 갖는 레벨 3 분류 패턴
[ 이란? ]
- 현실은 상위 분류와 하위 분류가 다대다(N:N) 형태 릴레이션쉽을 갖는 경우가 많음.
- 레벨3 분류 패턴에 롤업 및 스키마를 적용한 설계 방식
[ 이 패턴이 필요한 이유 ]
카테고리 간 그리고 카테고리 유형 간의 다대다 재귀 재귀 릴레이션쉽 설계 필요
[ 어떻게 작동하는가? ] 그림 5-13 참조
분류 엔티티에 스키마와 롤업을 적용하여 설계하는 방법 즉 각각의 자식은 여러 부모를 갖을 수 있고 각각의 부모는 여러 자식을 갖을 수 있도록 하는 것
스키마를 적용하거나 롤업을 추가하여 적용할 수 있다.
스키마? 분류 요소들을 특정 설계방식으로 처리해 놓은 것
예) 표준 산업분류 스키마
이런 스키마는 내, 외부에서 제공 될 수 있다. 같은 의미의 스키마가 서로 다른 기관으로부터
제공되기도 한다.
롤업? 분류 엔티티를 다양한 형태(집합)으로 구분지어 놓은 것
[ ERD ]
[ 언제 사용하는가? ]
- 포괄적이고 유연한 분류 모델이 필요한 경우
- 원천 데이터 제공자가 필요하고 Category Type들에 여러 분류가 적용될 경우
- 분류나 유형이 다대다 계층, 집합, 동료간 릴레이션쉽을 표현할 경우
[ 이 패턴의 약점은? ]
- 복잡하고 이해하기가 어렵다
- 과도한 패턴이 될 수 이다.
[ 레벨 1 ~ 레벨 3까지 ERD ]
- ERwin 7.2.5.1918 버전으로 작성되었습니다.
- 데이터 모델 리소스 북 Vol.3 (bysql.net 2013년 1차 스터디)
- 작성자: 정재훈
- 발표일: 2013년 5월 20일
- 본문서는 bysql.net 스터디 결과입니다 .본 문서를 인용하실때는 출처를 밝혀주세요. http://www.bysql.net
- 문서의 잘못된 점이나 질문사항은 본문서에 댓글로 남겨주세요. ^^
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 13 |
01 이 책의 소개
| 남송휘 | 2013.04.16 | 12278 |
| 12 | 02 역할의 설정: 관계자는 어떤 역할을 수행하는가 | 남송휘 | 2013.04.16 | 4770 |
| 11 | 03 역할의 활용: 관계자는 맥락에 어떻게 관련되어 있는가 | 남송휘 | 2013.04.16 | 9586 |
| 10 |
04 계층, 집합, 동료간 릴레이션쉽: 유사 데이터의 조직화
| 운영자 | 2013.04.16 | 14367 |
| » |
05 유형과 카테고리: 데이터의 분류
| 운영자 | 2013.04.16 | 10758 |
| 8 | 06 상태: 데이터의 상태 | 운영자 | 2013.04.16 | 6348 |
| 7 | 07 컨택 메커니즘: 연락 방법 | 운영자 | 2013.04.16 | 2312 |
| 6 | 07 컨택 메커니즘: 연락 방법-1 | 남송휘 | 2013.04.16 | 17585 |
| 5 | 07 컨택 메커니즘: 연락 방법-2 | 천리향1 | 2013.04.16 | 4775 |
| 4 |
08 비즈니스 룰: 비즈니스가 수행되는 규칙
| 시그너스7000 | 2013.04.16 | 18114 |
| 3 |
09 패턴의 활용
| 정재훈 | 2013.04.16 | 21357 |
| 2 | 10 패턴의 사회화 | 케를로스 | 2013.04.16 | 3653 |
| 1 |
Front Page
| 운영자 | 2013.04.16 | 109208 |