매주 각 스터디 팀원들이 담당 분량을 정리해서 올리고 토론식으로 진행합니다.
스터디 포스팅은 팀원들에의해 이루어지지만 스터디 참여는 사이트 회원 모두가 가능합니다.
진행기간: 2009.07 ~ 2009.10. 종료
3.1 SQL의 실행계획 (3/3)
2009.07.19 06:58
3.1.3. 옵티마이져의 최적화 절차
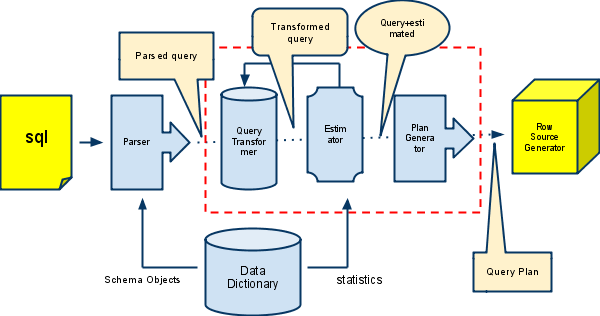
가) 질의 변환기
나) 비용 산정기
다) 실행계획 생성기
3.1.4. 질의의 변환 (Query Transforming)
3.1.4.1. 이행성 규칙 (Transitivity principle)
3.1.4.2. 뷰병합 (View Merging)
3.1.4.3. 사용자 정의 바인드 변수의 엿보기 (Peeking)
3.1.5. 개발자의 역할
- 목표: 사용자가 요구한 결과를 가장 최소의 자원으로 처리할 수 있는 방법을 찾아 내는 것
- 처리과정:
- 사용자가 입력한 SQl을 데이터 딕셔너리를 참조하여 파싱을 수행
- 파싱된 결과와 사용자가 지정한 힌트를 감안하여 최종적인 싱행계획을 생성
- 데이터 딕셔너리의 통계정보를 기반으로 각 조건을 감안하여 실행계획들의 비용(예상 계수)을 계산
- (데이터의 분포도,테이블의 저장 구조와 특성,인덱스의 구조, 파티션 형태, 비교연산자등)
- 산출된 비용을 기반으로 최소의 비용을 가진 실행계획을 선택
- 기본구성: 질의 변환기 (Query Transformer) , 비용산정기 (Estimator) , 실행계획 생성기 (Plan Generator)
parsing:
- 'select * from tab1'
1.* 을 인식하기 위해 딕셔너리에서 테이블의 컬럼정보를 참조하여 sql완성
2.완성된 sql은 쿼리조각(query block)으로 파싱되어 트리구조로 저장
3.옵티마이져 최적화 수행시작
가) 질의 변환기
- 보다 양호한 실행계획을 얻을 수 있도록 적절한 형태로 SQL의 모양을 변환하는 것
- 인라인 뷰나 뷰의 병합
- 뷰쿼리(뷰의정의 쿼리)를 실제 수행하는 쿼리와 병합하여 수행 ( 제한요소 있음)
- 조건절 진입(Predicate Pushing)
- 뷰병합이 안될경우 뷰쿼리 내부에 액세스쿼리의 조건절을 진입시킴
- 서브쿼리의 비내포화(Subquery Unnesting)
- 쿼리 수행중 서브쿼리의 내포관계를 해제하거나 조인형식으로 대체하여 수행
- 실체뷰(Materialized Views)의 질의 재생성
- (MView; 뷰쿼리에 의해 정의되지만 실제로 테이블처럼 물리적인 데이터를 저장)
- 사용자가 수행시킨 쿼리를 옵티마이져가 가장 최적의 물리적 집합을 처리하도록 재생성
- OR조건의 전개
- 여러개의 단워 쿼리로 분기하고 union all로 연결하는 질의 변환
- (체크 조건으로만 사용되는 경우 큰 비효율이 생김, 비용기준에 의해 전개여부 결정)
- 사용자 정의 바인드 변수 엿보기(Peeking)
- 최초에 소행될때 적용되었던 값을 ㅣ용해 실행계획을 수립, 다음 수행부터는 공유하는 방법
나) 비용 산정기
- 선택도(Selectivity)
- 처리할 대상(테이블,뷰집합,중간집합등)에서 해당 조건을 만족하는 로우가 차지하는 비율
코드:
select *
from emp
where deptno=20
and ename like 'SMITH%'
AND JOB='CLERK';
전체 100로우일경우
DEPTNO=20; (10%비율)
ENAME=SMITH 5명 (5%비율)
JOB='CLERK' 40명 (40%)
** INDEX
( DEPTNO+ENAME , JOB +DEPTNO, ENAME)
일경우 어떤 INDEX가 가장 양호한 선택도를 가지는지?
from emp
where deptno=20
and ename like 'SMITH%'
AND JOB='CLERK';
전체 100로우일경우
DEPTNO=20; (10%비율)
ENAME=SMITH 5명 (5%비율)
JOB='CLERK' 40명 (40%)
** INDEX
( DEPTNO+ENAME , JOB +DEPTNO, ENAME)
일경우 어떤 INDEX가 가장 양호한 선택도를 가지는지?
- 옵티마이져는 보다 정확한 선택도를 파악하기 위해 통계정보 활용
선택도는 0.0 ~ 1.0 사이의 값을 갖도록 생성 (0.0 전혀존해하지않음, 1.0 모두해당)
좋은 선택도를 가진것을 처리 주관으로 결정하면 보다 적은 처리범위를 액세스 한다는 뜻
코드:
SELECT STATEMENT
TABLE ACCESS (BY INDEX ROWID) OF "EMP" (COST=2 CARD=1 BYTES=32)
INDEX (FULL SCAN) OF 'PK_EMP' (UNIQUE) (COST=1 CARD=15)
TABLE ACCESS (BY INDEX ROWID) OF "EMP" (COST=2 CARD=1 BYTES=32)
INDEX (FULL SCAN) OF 'PK_EMP' (UNIQUE) (COST=1 CARD=15)
- 카디널리티 (Cardinality)
- 실행계획상의 CARD
- 판정 대상이 가진 결과 건수 혹은 다음 단계로 들어가는 중간 결과 건수를 의미 (선택도 * 전체 로우수)
- 절대량 (선택도가 10% 라도 100만건, 100건 양이 다름)
- 비용(Cost)
- 실행계획상의 'COST'
- 각 연산을 수행할 때 소요되는 시간비용을 상대적으로 계산한 예측치
- 스키마 객체에 대한 통계정보 + CPU 상황 + 메모리 상황 + 디스크 I/O 비용 고려
- 동일 비용일 경우 (RBO; 로우 캐쉬 의 순서, CBO; 인덱스명의 ASCII값)
- 옵티마이져가 다양한 계산식을 세우고 연산을 수행하더라도 완변하지 않음으로 경우에 따라 힌트,초기화 파라메터들을 복합적으로 사용하여야 함
다) 실행계획 생성기
- 주어진 쿼리를 처리할 수 있는 적용 가능한 실행계획을 선별하고 비교검토를 거쳐 가장 최소의 비용을 가진것을 선택
- 부속 서브쿼리나 병합이 불가능한 뷰들의 실행 계획이 우선 생성( 결과에 따라 메인쿼리가 절대적인 영향을 받기때문)
- 여러개의 처리 단위로 나타나며 가장 하위단부터 최적화를 시작(하위단의 결과를 상위단에서 사용하기위함)
- 논리적으로 적용가능한 실행계획을 주어진 시간에 최선의 선택(상대적)을함
- Adaptive search(적응적 탐색)
- 쿼리 수행 예상시간에 비해 최적화에 소요되는 시간이 일정비율이 넘지 않도록 하는 탐색전략
- 경험적(Heuristic)기법에 의한 초기치 선택(Cutoff)을 하는 전략을 사용
- 탐색도중 최적이라고 판단되는 실행계획을 발견하면 중지
- 시간의 제약이 존재하므로 경험에 의한 힌트 사용도 중요
3.1.4. 질의의 변환 (Query Transforming)
- 상수 - 가능한 수식의 값은 미리 구함
- 1) sales_qty > 1200/12
2) sales_qty > 100
3) sales_qty*12 > 1200
1)과 2)는 동일 but 3은 2와다름(연산자의 좌우이동은 하지않음) - LIKE
- '%' 나 '_'를 사용하지 않을경우 '=' 연산으로 단순화
JOB LIKE 'SALESMAN' ==> JOB = 'SALESMAN'
고정길이 데이터 타입에서는 결과를 다르게 할수있으므로 가변길이 데이타 타입에서만 가능 - IN 연산
- OR 논리 연산자를 사용해 여러개의 '='로 된 같은 기능의 조건절로 확장
- JOB IN ('CLERK','MANAGER') ==> JOB = 'CLERK' OR JOB = 'MANAGER'
- OR 논리 연산자를 사용해 여러개의 '='로 된 같은 기능의 조건절로 확장
- ANY 나 SOME
- '=' 비교연산자와 OR 논리 연산자를 이용해 같은 기능의 조건절로 확장
SALES_QTY> ANY (:IN_QTY1, :IN_QRY2) ==> SALES_QTY > :IN_QTY1 OR SALES_QTY > :IN_QTY2 - 서버쿼리를 사용했을경우 EXISTS연산자를 이용한 서브 쿼리로 변환
1) WHERE 100000 > ANY (SELECT SAL FROM EMP WHERE JOB='CLERK')
2) WHERE EXISTS ( SELECT SAL FROM EMP WHERE JOB='CLERK' AND 100000 > SAL)
- '=' 비교연산자와 OR 논리 연산자를 이용해 같은 기능의 조건절로 확장
- ALL
- 괄호내에 여러개의 항목이 저정되는 형태라면 '=' 연산자와 AND논리 연산자를 사용
1) SALES_QTY > ALL (:IN_QTY1, :IN_QTY2)
2) SALES_QTY > :IN_QTY1 AND SALES_QTY > :IN_QTY2 - ALL 뒤에 서브쿼리를 사용했다면 NOT ANY로 변환한후 다시 EXISTS연산자를 이용한 서브쿼리로 변환
1) WHERE 100000 > ALL (SELECT SAL FROM EMP WHERE JOB='CLERK')
2) WHERE NOT (100000 <= ANY (SELECT SAL FROM EMP WHERE JOB='CLERK'))
3) WHERE NOT EXISTS (SELECT SAL FROM EMP WHERE JOB='CLERK' AND 100000 <=SAL)
- 괄호내에 여러개의 항목이 저정되는 형태라면 '=' 연산자와 AND논리 연산자를 사용
- BETWEEN
- '>=' 와 '<=' 비교 연산자를 사용한 조건절로 변환
1) SALES_QTY BETWEEN 100 AND 200
2) SALES_QTY >= 100 AND SALES_QTY <=200
- '>=' 와 '<=' 비교 연산자를 사용한 조건절로 변환
- NOT
- 반대 비교연산을 찾아 대체
1) NOT (SAL < 30000 OR COMM IS NULL)
2) NOT SAL < 30000 AND COMM IS NOT NULL
3) SAL >= 30000 AND COMM IS NOT NULL - 서브쿼리에 사용될경우도 반대 비교연산을 찾아 대체
1) NOT DEPTNO = (SELECT DEPTNO FROM EMP WHERE EMPNO=7689)
2) DEPTNO <> (SELECT DEPTNO FROM EMP WHERE EMPNO=7689)
- 반대 비교연산을 찾아 대체
3.1.4.1. 이행성 규칙 (Transitivity principle)
- 상수의 경우
- comparison_operators: =,!=,^=,<,<>,>,<=,>=
- constant : 연산, sql함수,문자열,바인드 변수,상관관계 변수를 포함하는 상수 수식코드:where column1 comparison_operators constant
and column1=column2 - 옵티마이져는 column2 comparison_operators constant 추론
- CBO 일경우 수행코드:ex) select * from emp e, dept d where e.deptno=20 and e.deptno=d.deptno;
-> d.deptno= 20 을 추론
where column1 comparison_operators column3
and column1 = column2 - 옵티마이져는 column2 comparison_operators column3를 추론하지 않음
- 비교하는 대상이 상수 수식이 아닌 컬럼일 경우 이행이 일어나지 않음
- OR 을 가지는 조건을 UNION ALL을 사용한 복합 문장으로 변한하는 경우
- OR 조건을 분기할때 각각이 인덱스 접근 경로로 이요할수 있을 경우
- (여러개의 인덱스로 분기된 각각을 액세스 하여 결합하는 것이 범위를 줄인다고 판단된경우)
- 'IN-LIST ITERATOR' 이나 'CONCATENATION'이라고 표시
- INDEX를 사용하지 못하여 FULL SCAN하거나 OR조건이 단순 검증일경우 변환을 하지 않음
- 강제적용을 원할경우 'USE_CONCAT' 힌트를 사용코드:SELECT * FROM EMP
WHERE JOB='CLERK'
OR DEPTNO=10;
JOB과 DEPTNO에 각각 INDEX가 존재한다면
SELECT * FROM EMP WHERE JOB='CLERK'
UNION ALL
SELECT * FROM EMP WHERE DEPTNO=10 AND JOB<>'CLERK'; - RBO일경우 각각 INDEX사용가능하므로 무조건 분기
- CBO일경우 전체 테이블 스캔과 분기시의 비용을 비교해 변환여부를 결정
- IN 을 사용한 상수수식 비교도 유사 ( IN은 OR로 변환됨)
- 서브쿼리를 가진 복잡한 문장을 조인 문장으로 변환하는 경우
- 같은 기능의 조인 문장으로 변환하여 다시 이를 최적화코드:SELECT * FROM EMP
WHERE DEPTNO IN (SELECT DEPTNO FROM DEPT WHERE LOC = 'NEW YORK');
만약 DEPT 테이블의 DEPTNO 컬럼이 기보키나 UNIQUE 인덱스라면
SELECT EMP.* FROM EMP,DEPT
WHERE EMP.DEPTNO=DEPT.DEPTNO
AND DEPT.LOC='NEW YORK'; - 로 변환 (서브쿼리의 연결고리가 메인쿼리 집합을 변형시키지 않음이 보장)
- 현재의 문장을 그대로 최적화코드:SELECT * FROM EMP
WHERE SAL> (SELECT AVG(SAL) FROM EMP WHERE DEPTNO=20); - 조인문으로 변환할수 없음
- 서브쿼리의 결과가 메인쿼리의 컬럼에 제공되어 인덱스로 사용될수 있다면 먼저수행
- 그렇지 안으면 메인쿼리가 실행되면서 서브쿼리를 확인하는 필터형 처리나 각각의 집합을 액세스한후 머지하거나 해쉬조인으로 수행
- 같은 기능의 조인 문장으로 변환하여 다시 이를 최적화
3.1.4.2. 뷰병합 (View Merging)
- 뷰쿼리
- 뷰를 생성할 때 사용한 select 문 (from 절에 괄호로 묶어둔 select)
- 액세스 쿼리
- 뷰를 수행하는 sql (인라인뷰의 바깥에 있는 select)
- 병합방법
- 뷰병합(View Merging): 뷰쿼리를 액세스 쿼리에 병합해 넣는 방식
- 조건절 진입(Predicate pushing)법: 뷰병합을 할수없는 경우 뷰쿼리 내부에 액세스 쿼리의 조건절을 진입시키는 방식
- 병합 (액세스 쿼리 기준)
- 액세스 쿼리를 기준으로 뷰쿼리에 있는 대응인자들을 병합
코드:create view emp_10 (e_no,e_name , job, manager,hire_date,salart, commission,deptno)
AS
select empno,ename,job,mgr,hiredate,sal,comm,deptno
from emp
where deptno=10;
뷰엑세스
select e_no,e_name,salary,hire_date
from emp_10
where salary > 1000000;
액세스 쿼리의 뷰이름을뷰의 원래 테이블인 emp로 변환한후 조건절을 병합
select empno,ename,sal,hiredate
from emp
where deptno=10
and sal> 1000000; - 액세스 쿼리기준의 뷰병합이 불가능한 경우
- 집합연산 ( UNION , UNION ALL, INTERSECT, MINUS)
- CONNECT BY
- ROWNUM 사용
- SELECT-List 의 그룹함수 (AVG,COUNT,MAX,MIN,SUM)
- GROUP BY (단, MERGE 힌트를 사용했거나 관련 파라메터가 ENABLE이면 뷰병합 가능)
- SELECT-List 의 distinct(단, Merge 힌트를 사용했거나 관련 파라메터가 Enable이면 뷰병합 가능)
- 액세스 쿼리를 기준으로 뷰쿼리에 있는 대응인자들을 병합
- 병합(뷰쿼리 기준)
- 액세스쿼리에 있는 조건들을 뷰쿼리에 진입
- 액세스 쿼리에 있는 조건들이 Select문의 조건절 속으로 들어갔음(Pushing)
- 임시직은 부서가 90으로 지정했으므로 90=20으로 상수값을 비교, 실행계획은 상수값을 우선수행하므로 액세스 시도하지 않음
코드:create view emp_union_view (e_no,e_name,job,mgr,hiredate,sal,comm,deptno)
AS
select empno,ename,job,mgr,hiredate,sal,comm,deptno from regulat_emp
Union all
select empno,ename,job,manager,hiredate,salary,comm,90 from temporary_emp;
액세스
select e_no,e_name,mgr,sal
from emp_union_view
where deptno=20;
변환
select empno,ename,mgr,sal
from (select empno,ename,mgr,sal from regular_emp where deptno=20
union all
select empno,ename,manager,salary from temporary_emp where 90=20); - 액세스 쿼리에 있는 조건들이 Select문의 조건절 속으로 들어갔음(Pushing)
- GROUP BY를 사용한 뷰
코드:CREATE VIEW EMP_GROUP_BY_DEPTNO
AS
SELECT DEPTNO,AVG(SAL) AVG_SAL,MIN(SAL) MIN_SAL,MAX(SAL) MAX_SAL
FROM EMP
GROUP BY DEPTNO;
액세스
SELECT *
FROM EMP_GROUP_BY_DEPTNO
WHERE DEPTNO=10;
변환
SELECT DEPTNO,AVG(SAL) AVG_SAL,MIN(SAL) MIN_SAL,MAX(SAL) MAX_SAL
FROM EMP
WHERE DEPTNO=10
GROUP BY DEPTNO; - 뷰병합관련 파라메터코드:SQL> show parameter view
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
optimizer_secure_view_merging boolean TRUE
이나 complex_view_merging (??) 이 사용가능 상태일경우
group by 나 distinct를 사용했더라도 액세스쿼리의 조건들이 뷰쿼리에 파고들어갈수 있음 - 쿼리가 병합된경우의 실행계획코드:1 SELECT d.loc,v.avg_sal
2 FROM dept d,emp_group_by_deptno v
3 WHERE d.deptno=v.deptno
4* AND d.loc='London'
SQL> /
LOC AVG_SAL
------ ----------
London 3000
Execution Plan
----------------------------------------------------------
Plan hash value: 2006461124
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 76 | 8 (25)| 00:00:01 |
| 1 | HASH GROUP BY | | 2 | 76 | 8 (25)| 00:00:01 |
|* 2 | HASH JOIN | | 2 | 76 | 7 (15)| 00:00:01 |
|* 3 | TABLE ACCESS FULL| DEPT | 1 | 21 | 3 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL| EMP | 4 | 68 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("D"."DEPTNO"="DEPTNO")
3 - filter("D"."LOC"='London')
"
SELECT dept.loc,Avg(sal)
FROM dept,emp
WHERE dept.deptno=emp.deptno
AND dept.loc='London'
GROUP BY dept.ROWID,dept.loc;
" - 병합이 일어나지 않을경우 실행계획 (hint사용)코드:1 SELECT /*+ NO_MERGE(v) */ d.loc,v.avg_sal
2 FROM dept d,emp_group_by_deptno v
3 WHERE d.deptno=v.deptno
4* AND d.loc='London'
SQL> /
LOC AVG_SAL
------ ----------
London 3000
Execution Plan
----------------------------------------------------------
Plan hash value: 4262539133
--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 2 | 52 | 8 (25)| 00:00:01 |
|* 1 | HASH JOIN | | 2 | 52 | 8 (25)| 00:00:01 |
|* 2 | TABLE ACCESS FULL | DEPT | 1 | 9 | 3 (0)| 00:00:01 |
| 3 | VIEW | EMP_GROUP_BY_DEPTNO | 4 | 68 | 4 (25)| 00:00:01 |
| 4 | HASH GROUP BY | | 4 | 68 | 4 (25)| 00:00:01 |
| 5 | TABLE ACCESS FULL| EMP | 4 | 68 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("D"."DEPTNO"="V"."DEPTNO")
2 - filter("D"."LOC"='London') - IN을 사용한 서브쿼리에서의 뷰병합
- 조건절없이 사용했을 경우라도 병합 발생
코드:SQL> select emp.ename, emp.sal
2 from emp,dept
3 where (emp.deptno,emp.sal) in (select deptno,avg_sal from emp_group_by_deptno)
4 and emp.deptno=dept.deptno
5 and dept.loc='London';
ENAME SAL
---------- ----------
baoo 3000
bao2 3000
Execution Plan
----------------------------------------------------------
Plan hash value: 696572920
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 33 | 11 (19)| 00:00:01 |
|* 1 | FILTER | | | | | |
|* 2 | HASH JOIN | | 2 | 66 | 7 (15)| 00:00:01 |
|* 3 | TABLE ACCESS FULL | DEPT | 1 | 9 | 3 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL | EMP | 4 | 96 | 3 (0)| 00:00:01 |
|* 5 | FILTER | | | | | |
| 6 | HASH GROUP BY | | 4 | 68 | 4 (25)| 00:00:01 |
| 7 | TABLE ACCESS FULL| EMP | 4 | 68 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter( EXISTS (SELECT /*+ */ 0 FROM DURIDBA."EMP" "EMP" GROUP
BY "DEPTNO" HAVING "DEPTNO"=:B1 AND AVG("SAL")=:B2))
2 - access("EMP"."DEPTNO"="DEPT"."DEPTNO")
3 - filter("DEPT"."LOC"='London')
5 - filter("DEPTNO"=:B1 AND AVG("SAL")=:B2) - 인라인 뷰
- 뷰병합 적용
코드:1 SELECT /*+ MERGE(v) */ e1.ename,e1.sal,v.avg_salary
2 from emp e1, (select deptno,avg(sal) avg_salary from emp e2 group by deptno) v
3 where e1.deptno=v.deptno
4* and e1.sal>v.avg_salary
SQL> /
선택된 레코드가 없습니다.
Execution Plan
----------------------------------------------------------
Plan hash value: 2435006919
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8 | 424 | 8 (25)| 00:00:01 |
|* 1 | FILTER | | | | | |
| 2 | HASH GROUP BY | | 8 | 424 | 8 (25)| 00:00:01 |
|* 3 | HASH JOIN | | 8 | 424 | 7 (15)| 00:00:01 |
| 4 | TABLE ACCESS FULL| EMP | 4 | 144 | 3 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL| EMP | 4 | 68 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("E1"."SAL">SUM("SAL")/COUNT("SAL"))
3 - access("E1"."DEPTNO"="DEPTNO") - 뷰병합 하지않은 경우
- 'NO_MERGE' 힌트
- 실행계획상 병합하지 않은 경우가 유리
코드:1 SELECT /*+ NO_MERGE(v) */ e1.ename,e1.sal,v.avg_salary
2 from emp e1, (select deptno,avg(sal) avg_salary from emp e2 group by deptno) v
3 where e1.deptno=v.deptno
4* and e1.sal>v.avg_salary
SQL> /
선택된 레코드가 없습니다.
Execution Plan
----------------------------------------------------------
Plan hash value: 269884559
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 41 | 8 (25)| 00:00:01 |
|* 1 | HASH JOIN | | 1 | 41 | 8 (25)| 00:00:01 |
| 2 | VIEW | | 4 | 68 | 4 (25)| 00:00:01 |
| 3 | HASH GROUP BY | | 4 | 68 | 4 (25)| 00:00:01 |
| 4 | TABLE ACCESS FULL| EMP | 4 | 68 | 3 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | EMP | 4 | 96 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("E1"."DEPTNO"="V"."DEPTNO")
filter("E1"."SAL">"V"."AVG_SALARY")
3.1.4.3. 사용자 정의 바인드 변수의 엿보기 (Peeking)
- 바인드 변수 사용
- 바인드 변수를 사용한 쿼리는 먼저 파싱과 최적화가 끝난후 바인딩이 이루어짐
(최적화가 이루어지는 시점에 변수로 제공되는 컬럼은 바인딩 값에 대한 통계정보를 사용할수 없음) - 바인드변수를 분포도가 균일하지 못한 컬럼(Highly skewed column)에 사용하면 최악의 실행계획이 생성될수 있음
- 바인드 변수를 사용한 쿼리는 먼저 파싱과 최적화가 끝난후 바인딩이 이루어짐
- Peeking
- 바인드 변수를 사용한 쿼리가 처음 실행될때 옵티마이져가 지정한 변수값을 사용하여 상수값을 사용할때와 같이 선택도를 확인하여 최적화를 수행하고 실행계획을 생성한후 공유 SQL 영역에 등록하여 향후 쿼리를 다시 사용시 사용
- 기존의 분포도관련 문제를 조금이라도 해결
('성별' 컬럼에 'M' 이 99%,'F'가 1%일 경우 'M'이 첫번째일 경우 전체테이블 스켄,'F'일때는 인덱스 스킨이 선택될수있음) - _OPTIM_PEEK_USER_BIND 파라메터 값에 따라 정해짐
인용:
참고
BVP 를 사용할 경우 Explain Plan 명령문을 통해서 확인한 실행 계획(Execution Plan)이 실제 운영 환경에서는 적용되지 않을 수 있다. Explain Plan 명령문에서는 BVP가 적용되지 않기 때문에 BVP가 적용된 런타임의 실행 계획과는 다른 실행 계획을 보고할 가능성이 있다.
만일 테스트 환경에서 성공적으로 수행된 SQL 문장이 런타임에 느린 성공을 보인다면 일차적으로 BVP에 의한 사이드 이펙트가 아닌지 검증해보아야 한다. 런타임의 실행 계획은 V$SQL_PLAN 뷰를 통해 확인 가능하다.
출처: http://wiki.ex-em.com/index.php/OPTIM_PEEK_USER_BINDS
BVP 를 사용할 경우 Explain Plan 명령문을 통해서 확인한 실행 계획(Execution Plan)이 실제 운영 환경에서는 적용되지 않을 수 있다. Explain Plan 명령문에서는 BVP가 적용되지 않기 때문에 BVP가 적용된 런타임의 실행 계획과는 다른 실행 계획을 보고할 가능성이 있다.
만일 테스트 환경에서 성공적으로 수행된 SQL 문장이 런타임에 느린 성공을 보인다면 일차적으로 BVP에 의한 사이드 이펙트가 아닌지 검증해보아야 한다. 런타임의 실행 계획은 V$SQL_PLAN 뷰를 통해 확인 가능하다.
출처: http://wiki.ex-em.com/index.php/OPTIM_PEEK_USER_BINDS
3.1.5. 개발자의 역할
인용:
SQL은 집합의 개념과 비절차형 처리를 근간으로 하고 있다.
우리의 목적은 원하는 시간을 잘 감안해서 SQL로 관계형데이터베이스를 이용하여 보다 많은 데이터를 절차형처리보다 빠른시간에 수행하도록하는것이다.
하지만 옵티마이져에 무지한 상태에서 어슬픈 방법으로 복잡한 SQL을 작성해서는 안된다.
옵티마이져를 이해하지 못한 사람이 함부로 복잡한 SQL을 사용하는것은 바람직하지 못하다.
우리의 목적은 원하는 시간을 잘 감안해서 SQL로 관계형데이터베이스를 이용하여 보다 많은 데이터를 절차형처리보다 빠른시간에 수행하도록하는것이다.
하지만 옵티마이져에 무지한 상태에서 어슬픈 방법으로 복잡한 SQL을 작성해서는 안된다.
옵티마이져를 이해하지 못한 사람이 함부로 복잡한 SQL을 사용하는것은 바람직하지 못하다.
- 작성자: tofriend(남송휘)
- 작성일: 2009년 07월 19일
- 참고문헌 : 새로쓴 대용량데이터 베이스 1 - 이화식 , 기타 문서