11. Static SQL 구현을 위한 기법들
2010.07.05 08:09
11. Static SQL 구현을 위한 기법들
Dynamic SQL 자주 사용하게 되는 이유 앞에서 소개,
두 번째로 많이 나온 사례로 조건절에 IN-List 항목이 가변적으로 변할 때
Dynamic SQL → Static SQL 변경 기법
■ 교재에서 소개하는 사례는 Dynamic SQL로 작성하더라도 생성 될 최대 SQL 개수가 그리 많지 않기 때문에
라이브러리 캐시에 큰 부하를 주지 않음
☞ Dynamic SQL 사용하는 순간 조건절 비교 값까지 습관적으로 Litrear 상수 값을 사용하도록 개발하는 문제 발생!!
Dynamic SQL → Static SQL 로 작성하는 습관과 능력 필요
(1) IN-List 항목이 가변적이지만 최대 경우 수가 적은 경우

LP회원을 선택하는 그림 4-15 팝업 창에서 사용자가 선택한 LP회원 목록을 선택하고자 할 때,
Static 방식으로 SQL을 작성 시 아래 7개 SQL을 미리 작성해 두어야 함.
select * from LP회원 where 회원번호 in (01')
select * from LP회원 where 회원번호 in (01', '02')
select * from LP회원 where 회원번호 in (01', '03')
select * from LP회원 where 회원번호 in (01', '02', '03')
select * from LP회원 where 회원번호 in (02')
select * from LP회원 where 회원번호 in (02', '03')
select * from LP회원 where 회원번호 in (03')
- SQL을 경우의 수만큼 미리 작성
→ 선택 가능한 회원수가 4개로 늘어나면 15개, 5개면 31개의 SQL이 필요.
- SQL 을 미리 작성해 두고 경우에 따라 그 중 하나를 선택하도록 프로그래밍하는 것은 귀찮음
→ Dynamic SQL을 사용하는 손쉬운 방법 선택
※ 이를 Static SQL로 구현하기 위한 해법은 허무하게도 아래와 같이 간단함
- 상황에 따라 Decode문을 사용해야 할 때도 발생.
(그림 4-15에서 4개의 체크박스에 각각 내부적으로 'all', '01', '02', '03' 값이 부여돼 있다고 가정하고 작성)
select * from LP회원
where 회원번호 in ( decode(:a, 'all', '01', :b)
, decode(:a, 'all', '02', :c)
, decode(:a, 'all', '03', :d) )
(2) IN-List 항목이 가변적이고 최대 경우 수가 아주 많은 경우

- (그림 4-16) IN-List 항목 앞 사례와 동일, 가능한 경우 수가 너무 많음
→ Static SQL로 일일이 작성해 두는 것은 불가능
→ 바인드 변수
사용도 쉽지 않음
∵ 실행 시 바인드 변수에 값을 입력하는 코딩을 그만큼 많이 해야함.
- (그림 4-16) 화면에 보이는 항목 개수가 이미 60여개
→ 일반적으로 SQL 조건절의 좌변에는 비교할 상수 또는 변수, 우변은 컬럼 위치
select * from 수시공시내역
where 공시일자 = :일자
and :inlist like '%' || 분류코드 || '%'
- 조건절을 위와 같이 작성
- 사용자가 선택한 분류코드를 ',' 등 구분자로 연결
- String형 변수에 담아서 바인딩 후 실행 ☞ :inlist := '01,03,08,14,17,24,33,46,48,53'
※ 참고
문자열 처리 시 오라클 내부 알고리즘상 like 연산자보다 instr 함수가 더 빠르게 처리
▼ Like 연산자 대신 Instr 함수 사용
select * from 수시공시내역
where 공시일자 = :일자
and INSTR(:inlist, 분류코드) > 0
1. IN-List를 사용할 때
select * from 수시공시내역
where 공시일자 = :일자
and 분류코드 in ( ... )
2. like 또는 instr 함수를 사용할 때
select * from 수시공시내역
where 공시일자 = :일자
and INSTR(:inlist, 분류코드) > 0
- 1번 IN-List를 사용 ☞ 인덱스 구성 '분류코드 + 공시일자' 일 시 유리
- 2번 SQL문은 사용 ☞ 이 인덱스를 사용하지 못하거나 Index Full Scan
- 인덱스 구성 '공시일자 + 분류코드' 일 때 시 상황에 따라 다름
→ 선택 항목 개수가 소수일 때는 1번 유리
→ 다수일 때는 2번이 유리할 수 있음
3. 소수 항목만 조회, 복합인덱스가 '분류코드 + 공시일자' 일 시 효율적 액세스 방법
<방법 1> - 작은 테이블 Full Scan으로 NL 조인 방식으로 분류코드 값을 해당 테이블 조회
select /*+ ordered use_nl(B) */ B.*
from ( select 분류코드
from 수시공시분류
where INSTR(:inlist, 분류코드) > 0 ) A
, 수시공시내역 B
where B.분류코드 = A.분류코드
<방법 2> - 사용자가 선택한 분류코드를 String형 변수에 담아 바인딩
:inlist := '01030814172433464853'
select /*+ ordered use_nl(B) */ B.*
from ( select substr(:inlist, (rownum-1)*2+1, 2))
from 수시공시분류
where rownum <= length(:inlist) / 2) A
, 수시공시내역 B
where B.분류코드 = A.분류코드
<방법 3> - 방법2 와 동일 한 방식으로 dual 테이블을 이용한 동적 생성
select /*+ ordered use_nl(B) */ B.*
from (select substr(:inlist, (level-1)*2+1, 2)
from dual
connect by level <= length(:inlist) / 2) A
, 수시공시내역 B
where B.분류코드 = A.분류코드
(3) 체크 조건 적용이 가변적인 경우
select 회원번호, SUM(체결건수), SUM(체결수량), SUM(거래대금)
from 일별거래실적 e
where 거래일자 = :trd_dd
and 시장구분 = '유가'
and exists (
select 'x'
from 종목
where 종목코드 = e.종목코드
and 코스피종목편입여부 = 'Y'
)
group by 회원번호
- 주식종목에 대한 회원사(증권사)별 거래실적 집계 쿼리
- Exists 서브 쿼리 : 코스피에 편입된 종목만을 대상으로 거래실적 집계할때만 동적으로 추가
- ▼ Static SQL로 구현
select 회원번호, SUM(체결건수), SUM(체결수량), SUM(거래대금)
from 일별거래실적 e
where 거래일자 = :trd_dd
and 시장구분 = '유가'
and exists (
select 'x'
from 종목
where 종목코드 = e.종목코드
and 코스피종목편입여부 = decode(:check_yn, 'Y', 'Y', 코스피종목편입여부)
)
group by 회원번호
☞ 사용자가 코스피 종목 편입 여부와 상관없이 전 종목 집계 시 서브쿼리 수행할 필요 없지만
위 처럼 SQL을 무리하게 통합함으로써 항상 서브쿼리 수행이라는 비효율 발생
■ 교재 결과 1 (최적화 전)
- <전 종목 대상 집계 시>
블록 I/O 8,500 여건 발생 (exists 절을 뺀 쿼리는 600 여건만 발생)
☞ 불필요한 서브 쿼리 수행으로 약 8,000 건의 불필요 I/O 발생
- <사용자가 코스피 편입 종목만으로 집계 시>
약 8,200 여건 발생, Static SQL로 구현 전 큰 차이 없음
select 회원번호, SUM(체결건수), SUM(체결수량), SUM(거래대금)
from 일별거래실적 e
where 거래일자 = :trd_dd
and 시장구분 = '유가'
and exists (
select 'x' from dual where :check_yn = 'N'
union all
select 'x'
from 종목
where 종목코드 = e.종목코드
and 코스피종목편입여부 = 'Y'
and :check_yn = 'Y'
)
group by 회원번호
위 처럼 SQL 구현 시 I/O 효율과 라이브러리 캐시 효율 모두 달성 가능
∵ Exists 서브쿼리는 존재 여부만 체크로 그 안에 Union all 사용 시 하나의 레코드라도 나와도 True 리턴
■ 교재 결과 2 (최적화 후) - 위의 변경된 SQL 적용
- <전 종목 대상 집계 시>
:check_yn = 'N' 으로 입력 시 Union all 의 하단 수행하지 않고 Exists 서브쿼리를 바로 빠져나옴
10g 부터 Dual 테이블이 FAST DUAL 방식으로 수행하여 블록 I/O 미발생
☞ Static SQL 쿼리 변경 전 SQL 결과와 수행이 같음 (블럭 I/O 발생 약 600 여건)
※ 단, 9i 이전 버전에서는 Dual 테이블이 Full Scan 방식으로 헤더를 포함하여 보통 2~4개 정도의 블록 I/O 추가 발생
- <사용자가 코스피 편입 종목만으로 집계 시>
전 SQL과 수행 성능 동일 함
∵ Static SQL 쿼리 변경 전 SQL 에서도 서브쿼리를 수행
(4) Select-list 가 동적으로 바뀌는 경우
▼ 사용자 선택에 따라 화면 출력 항목 변경으로 SQL 동적 구성 상황
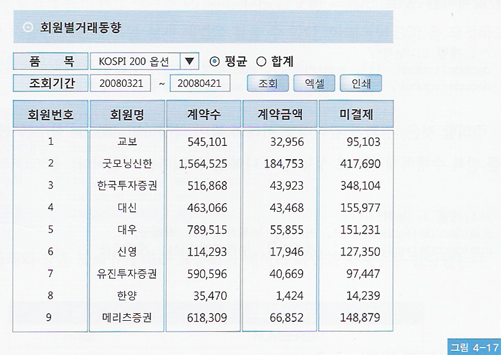
/* 1 : 평균 2: 합계 */
if( pfmStrCmpTrim(INPUT->inData.gubun, "1", 1) == 0){
snprintf(..., " avg(계약수), avg(계약금액), avg(미결제약정금액) ");
} else {
snprintf(..., " sum(계약수), sum(계약금액), sum(미결제약정금액) ");
}
↓ Static SQL로 변경
/* 1 : 평균 2: 합계 */
decode(:gubun, '1', avg(계약수), sum(계약수)),
decode(:gubun, '1', avg(계약금액), sum(계약금액)),
decode(:gubun, '1', avg(미결재약정금액), sum(미결재약정금액)),
☞ Decode 함수 또는 Case 구문 활용
(5) 연산자가 바뀌는 경우
▼ 사용자 선택에 따라 비교 연산자가 그때그때 달라짐
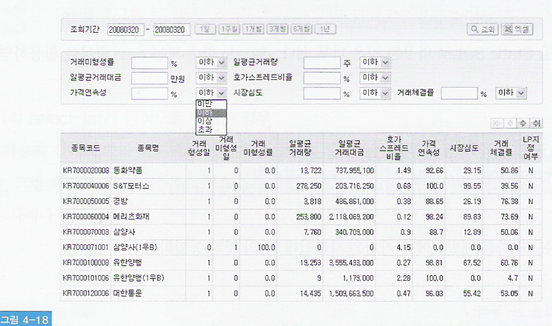
where 거래미형성률 between :min1 and :max1
and 일평균거래량 between :min2 and :max2
and 일평균거래대금 between :min3 and :max3
and 호가스프레드비율 between :min4 and :max4
and 가격연속성 between :min5 and :max5
and 시장심도 between :min6 and :max6
and 거래체결률 between :min7 and :max7
☞ SQL을 위처럼 작성 후 연산자에 따라 바인딩 값 변경
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 67 |
Front Page
| 운영자 | 2010.05.17 | 154865 |
| 66 |
4. Prefetch
| balto | 2010.07.10 | 28434 |
| 65 |
5. 오라클 Lock
| 휘휘 | 2010.06.07 | 26368 |
| 64 |
2. DB 버퍼 캐시
| 휘휘 | 2010.05.24 | 21916 |
| 63 |
3. SQL 트레이스
| balto | 2010.06.06 | 21175 |
| 62 |
1. 기본 아키텍처
[1] | 휘휘 | 2010.05.23 | 19899 |
| 61 |
2. 트랜잭션 수준 읽기 일관성
| 휘휘 | 2010.06.07 | 19568 |
| 60 |
5. Undo
| 토시리 | 2010.05.31 | 18650 |
| 59 |
11. Shared Pool
| 실천하자 | 2010.05.31 | 18511 |
| 58 | 9. Static vs. Dynamic SQL [1] | balto | 2010.07.04 | 18343 |
| 57 |
4. Array Processing 활용
| 휘휘 | 2010.07.05 | 18239 |
| 56 | 1 장. 오라클 아키텍처 | 운영자 | 2010.05.20 | 17842 |
| 55 |
5. Fetch Call 최소화
| 휘휘 | 2010.07.05 | 16839 |
| 54 | 9. ASH(Active Session History) | 실천하자 | 2010.06.14 | 15607 |
| 53 |
2. SQL 처리과정
| 휘휘 | 2010.06.28 | 15340 |
| 52 | 3. 버퍼 Lock [1] | 휘휘 | 2010.05.24 | 15225 |
| 51 |
6. 바인드 변수의 부작용과 해법
| 실천하자 | 2010.06.28 | 14665 |
| 50 | 1. Explain Plan | 실천하자 | 2010.06.06 | 14663 |
| 49 | 8. PL/SQL 함수 호출 부하 해소 방안 | 토시리 | 2010.07.11 | 14023 |
| 48 | 7. Result 캐시 | 휘휘 | 2010.07.19 | 12969 |