1.3. 클러스터링 테이블
2010.09.09 11:54
1.3 클러스터링 테이블
● 클러스터링 도입 사례
문제점 : 데이터베이스의 수행속도의 문제를 해결
해결책 : 다수의 인덱스 지정, 집계용 테이블의 추가, 컬럼의 중복화
결과 : 해결도 가능하지만 또다른 문제를 야기 시키기도 한다.
1.3.1 클러스터링 테이블의 개념
● 클러스터
- 테이블이나 인덱스처럼 저장공간을 가지는 오브젝트(Object)
- 정해진 컬럼값을 기준으로 동일한 값을 가진 하나 이상의 테이블 로우를 같은 장소에 저장하는 물리적 기법
- 대량의 범위를 효율적으로 액세스하기 위해 사용
● 클러스터와 테이블의 상관관계(종속성)
- 각각이 독립적인 오브젝트이지만 클러스터로 생성된 오브젝트 내에 테이블이 생성
- 따라서 테이블이 없는 클러스터는 데이터 입력 불가
- 고로 클러스터를 생성 후 테이블을 생성한다.
● 클러스터 종류
- 인덱스 클러스터 : 클러스터 인덱스를 경유하여 클러스터를 찾는다.
- 해쉬 클러스터 : 해쉬 함수를 이용하여 클러스터를 찾는다.
● 클러스터에 데이터를 저장하기 위해서는 테이블 생성은 물론 클러스터 인덱스도 생성해야 한다
● 클러스터링 효과
- 하나 이상의 테이블에서 같은 값을 가진 로우들을 모아 조인이 될 로우들을 옆에 두어 조인을 위한 운송 단가를 줄일 수 있다.
- 하나의 테이블에 동일한 컬럼값을 가진 로우들을 모아두어 대량의 범위처리 액세스 운송 단가를 줄일 수 있다.
- 클러스터링 팩트 향상(액세스하고자 하는 데이터들을 얼마나 모왔는지를 말한다)
1.3.2 단일테이블 클러스터링
● 내용 정리
- 지정된 클러스터에 하나의 테이블만 생성시키는 것을 말한다.
- 넓은 범위의 데이터를 동시에 액세스하고자 할 때 주로 사용 => 인덱스의 취약점 해결
- 인덱스와 뚜렷한 역할분담이 가능
- 검색을 제외한 모든 경우에는 추가적인 부하 발생
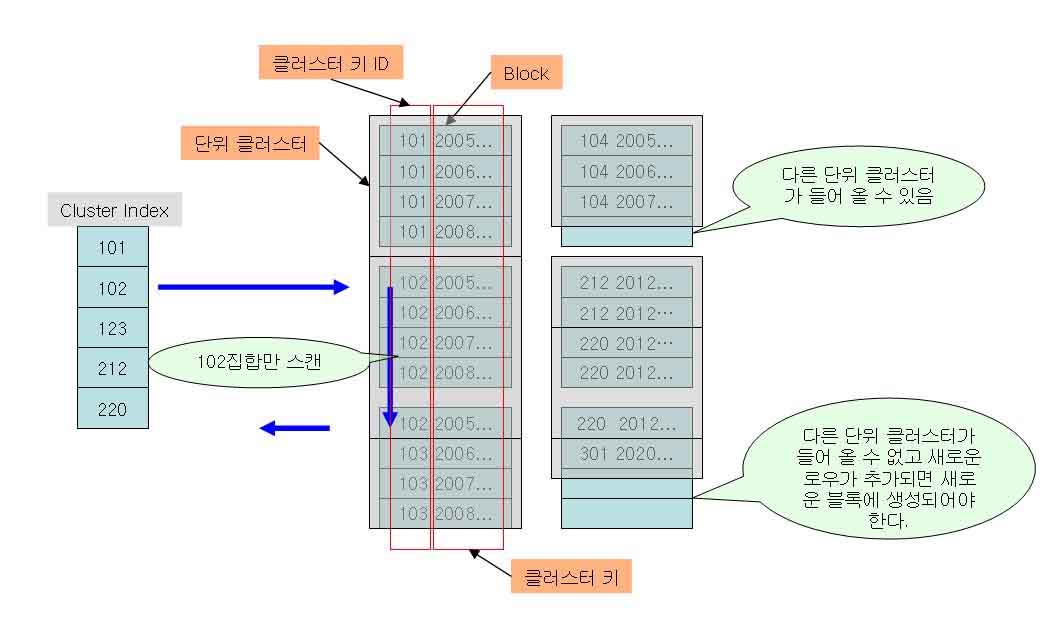
● 단일테이블 클러스터링 구조
- 클러스터 인덱스는 클러스터키 컬럼값마다 단 하나씩만 존재 - 클러스터링 테이블의 각 로우 헤더에 클러스터키 ID를 가짐 - 각각의 블록에 단위 클러스터 개수는 클러스터 크기에 따라 다름(위 예제는 2개) - 클러스터키 값은 단 한 번만 저장
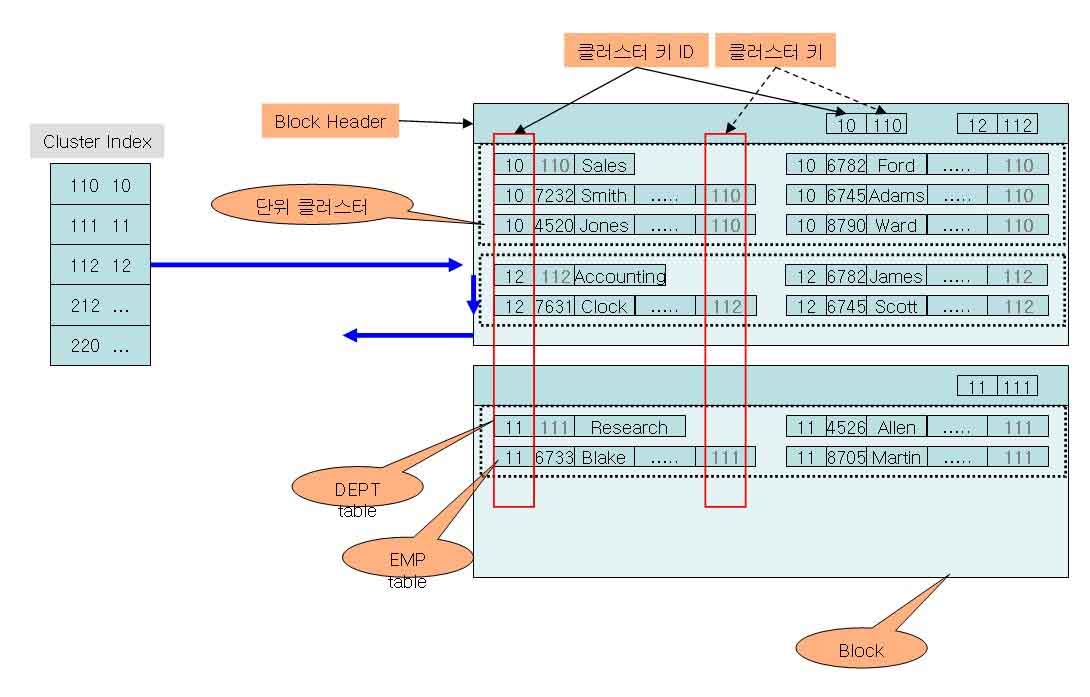
● 클러스터 스캔 방식 - 클러스터링 테이블의 각 로우 헤더에 클러스터키 ID 를 가지고 있으므로 같은 ID를 가진 로우들을 스캔 - 클러스터키 ID를 기준으로 스캔 하므로, 한번 검색시 여러건의 로우를 액세스 - 클러스터 컬럼의 조건이 ‘BETWEEN, LIKE’ 등을 사용했다면 클러스터 인덱스의 처리범위가 끝날 때가지 반복 - 클러스터키 ID로 클러스터 인덱스를 생성하여 데이터 스캔 1.3.3. 다중테이블 클러스터링 ● 개념 정리 - 단위 클러스터에 두 개 이상의 테이블을 함께 저장하는 것 - 같은 클러스터키 컬럼값을 가진 로우가 동일한 장소에 저장 ? 테이블 조인속도 향상 ● 다중테이블 클러스터링 구조 - 하나의 블록에 두 개의 단위 클러스터 입주 - 각 로우에 클러스터키 ID 저장, 블록헤더에 클러스터키 정보 저장 ? 단위 클러스터에 클러스터키 값 불필요 - 지역적 투명성 : 두개의 테이블을 클러스터에 저장하여도 각 테이블의 독립성은 영향받지 않는다. 1.3.4 클러스터링 테이블의 비용 - 클러스터링은 데이터 액세스에 효과적이지만 그에 상응하는 부하라는 비용이 발생한다 - 해결할 수 없는 부분이 있꺼나 투자대비 효과가 기대되는 경우 도입 - 인덱스로 우선 해결하고 클러스터링 검토 ● 쿨러스터링으로 인한 부하 클러스터링은 검색의 효율을 높여 줄 뿐이며, 입력-수정-삭제 시는 추가적인 부하가 발생한다. 가) 입력(INSERT) 시의 부하 - 정해진 위치에 저장되어야 하므로 일반 테이블보다 추가적인 부하가 발생 (클러스터키 값에 의한 저장위치가 달라져 프리리스트 요구 횟수가 증가하기 때문) 나) 수정(UPDATE) 시의 부하 - 수정으로 인한 부하는 미미하나 클러스터 체인이 발생하여 클러스터 팩터가 나빠진다. - 클러스터키 컬럼이 아닐 때의 수정은 일반 테이블과 동일 - 클러스터키 수정이 빈번할 경우 컬럼을 지정하는 것은 좋지 않다. 다) 삭제(DELETE) 시의 부하 - 클러스터링 테이블의 로우 삭제시 부하 발생 안함. - 클러스터링 테이블 자체를 삭제(DROP)시 ? 내부적으로 ‘DELETE’ 수행 ? 부하 발생 1.3.5 해쉬(Hash) 클러스터링 - 인덱서를 대신하는 개념으로 볼 수 있음 - 물리적인 인데스를 가지지 않고 해쉬값을 이용하여 데이터를 액세스 - 활용범위가 특정한 경우에 한정