1.1. 테이블과 인덱스의 분리형
2010.09.13 08:20
1.1 테이블과 인덱스의 분리형
- 테이블과 인덱스가 별개의 객체로 저장
- 장점 : 저장 시 인덱스 영향 X, 저장 부하 감소
- 단점 : 액세스 시 부담 증가
- 관계형 데이터 베이스의 가장 일반적인 데이터 저장 형식
- 대용량 데이터를 관리에 효과적인 구조
1.1.1 분리형 테이블의 구조
■ 구조
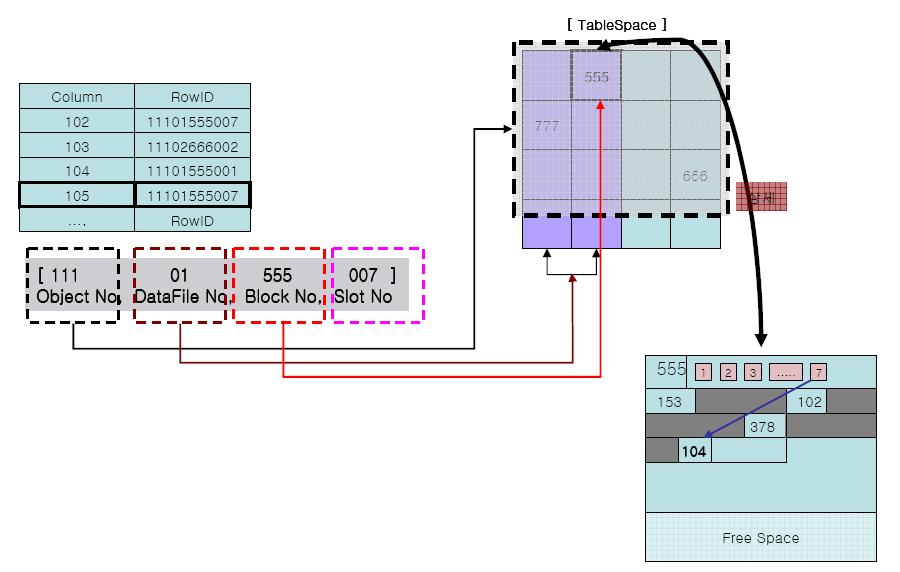
- 테이블 스페이스 : 논리적인 저장 공간 (ex. 부지)
- 세그먼트 : 테이블 스페이스를 용도별 구분 (ex. 건물부지, 운동장부지)
오브젝트가 구성 될 공간
- ROWID
- 형식
{ Object No (6) } { File No (3) } { Block No (6) } { Slot No (3) }
Display : 18byte, 실제크기 : 10byte
AAAAAA (6) : DataObject No = DB Segment 식별정보
000 (3) : Relative file = Tablespace의 Datafile No
AAAAAA (6) : Block No = DataBlock번호
000 (3) : Row Number = Block에서의 Row의 Slot No
- 절대 번호 포함 X
- 테이블에 존재 X, 인덱스에 존재
- 실행결과
SELECT ROWID, ENAME FROM EMP
WHERE ROWNUM <= 5;
ROWID ENAME
------------------------ --------
AAAHW7AABAAAMUiAAA SMITH
AAAHW7AABAAAMUiAAB ALLEN
AAAHW7AABAAAMUiAAC WARD
AAAHW7AABAAAMUiAAD JONES
AAAHW7AABAAAMUiAAE MARTIN
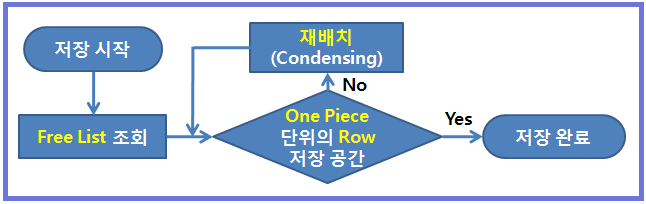
■ Row는 블록 내 One piece로 존재
- Row 길이 변경 시 Row가 연결 된 하나의 조각으로 들어 갈 빈 공간을 찾아 이동
- Row 이동 시 RowID 변경 없음
- Row 이동으로 사용할 수 없는 작은 조각 (Fragmentation) 발생
■ Migration & Chain
Row 길이 증가로 한 블록 내 저장을 못하는 경우 발생
- 이주 (Migration) : 해당 RowID (과거주소)에 현재의 주소를 남겨 둠
- 장점 : RowID 변경 X
- 단점 : 액세스 시 여러 블록 Read
- 체인 (Chain) : 부족한 공간을 다른 블록에 연결해서 저장
※ 이주는 하나의 블록에 실 데이터가 저장, 체인는 두 개 이상의 블록에 실 데이터 저장
1.1.2 클러스터링 팩터
■ 클러스터링 팩터 : 인덱스 Row 순서와 테이블에 저장 된 데이터 Row 위치의 일치성
클러스터링 팩터 ∝ 인덱스 액세스 효율
Index1 에서 조회 되는 Row의 수가 더 많지만 블록 Read 수는 더 작음
∵ Index1에 대해서 클러스터링 팩터가 좋음
☞ 테이블 Row 저장 순서와 자주 사용하는 범위의 액세스와 동일 시 클러스터링 팩터가 좋음
■ 클러스터링 팩터 향상 방법
- 테이블 생성시 저장 컬럼 순서 결정 중요
- 저장 시 비용이 들더라도 클러스터링 팩터 향상 시 효율성 ↑
- 재생성 - 파티션 시 최근 생성 일부분만하여 부담 ↓
- 병렬처리 (이번 절에서는 자세히 다루지 않음)
1.1.3 분리형 테이블의 액세스 영향요소
가) 넓은 범위의 액세스 처리에 대한 대처방안
- 소형 테이블 : 적은 범위의 블록에 분포
- 메모리 내에 존재 가능성 ↑
- 랜덤 액세스 시 부하 부담 ↓
- 중형 테이블
- 가장 중요한 액세스 형태 선정
- 다른 컬럼(들)이 가진 범위에 대한 문제 해결 방법 모색 (앞으로 계속 다룰 내용)
- 대형 테이블
- 단순 저장형 개념으로 사용 시 (ex. Log 정보 등)
- 특정 액세스 형태로 Read, 대량 Scan, 신속한 저장 요구
- 대량의 데이터 증가로 파티션 같은 조치 필요
- 랜덤 액세스가 자주 발생, 액세스 형태가 다양하지 않을 시 (ex. 고객 정보 등)
- 대량의 데이터가 급격히 들어오는 경우 적음
- 범위 처리 발생 적음
- 파티션 적용 시 특정 파티션 액세스 경우도 적음
- 파티션이나 클러스터링 혜택 적음
- 대량의 데이터가 지속적 증가, 다양한 액세스 형태 시 (ex. 매출 정보 등)
- 데이터 관리 및 액세스 부담이 큼
- 지속적 증가 데이터에 대한 관리적 부담 발생 ☞ 파티션 적용
- 최소한 필요한 부분만 액세스 방법 모색
- 전략적 인덱스 구성
- SQL 실행 계획 최적화
- 테이블 구조
나) 클러스터링 팩터 향상 전략
- 자주 액세스하는 것들이 유사한 위치에 모여 있도록 함
- 분리형 구조에에서 특정 형태로 저장되로록 강제 할 수 있는 방법이 없음 ☞ 주기적으로 테이블 재생성
■ 테이블 재생성 효과
- 응집도 향상
- 체인 감소
- 블록 내 데이터 저장율을 향상 시켜 불필요한 I/O 감소
- 인덱스 재생성 필요 (인덱스의 가지깊이 정리 효과 발생)
■ 테이블 재생성 시 고려 사항
- 가장 자주 범위처리를 하는 컬럼(들)로 정렬하여 저장
- 원하는 형태의 컬럼 순으로 정렬 생성 된 인덱스가 있을 시, 해당 인덱스를 경유하여 저장 (없을 시 병렬 처리로 정렬)
- 관련 인덱스(기본키에 대한 제약조건 포함) 모두 제거 or Disable
∵ 테이블 저장 속도 크게 저하, 인덱스에 많은 분할 발생
※ 참고
분리형 테이블 구조, 클러스터링 팩터 이미지 출처 : http://www.gurubee.net/pages/viewpage.action?pageId=1343689&