4.2. 클러스터링 형태의 결정 기준
2010.11.26 05:52
4.2. 클러스터링 형태의 결정 기준
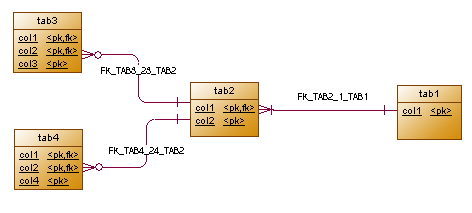
TAB3, TAB4 는 대용량 테이블
TAB3.col3 은 매우 빈번하게 사용 되어 진다.
TAB4.col4 으로 자주 넓은 범위처리를 하고 있다고 가정하면
포괄적인 클러스터링 : TAB3+TAB2+TAB1
부분적인 클러스터링 : TAB1+TAB2
단일테이블 클러스터링 : TAB3.col3, TAB4.col4
이렇게 클러스터링을 할 수 있다.
하지만, 실무에서는 다양한 형태의 테이블들이 존재하므로 업무 상황을 감안해서 결정해야 한다.
1. 클러스터링 형태 판단 기준 ( 1-4-13 그림 기준으로 )
4.2.1. 포괄적인 클러스터링
- 두 테이블 간의 클러스터링이 아니고 그 이상을 결합하는 경우를 지칭한 것.
- tab1 -> tab2 -> tab3 순으로 수식 계열로 내려갈수록 데이타량은 증가한다.
- tab3 경우는 밀도가 매우 높으나 tab2, tab1 으로 갈수록 밀도가 낮아 진다.
- tab1, tab2 만 액세스할 경우 많은 블록을 액세스해야 한다.
- 다수의 테이블을 클러스터링 하는 것은 현재의 사용형태뿐만 아니라 향후에 예상되는 액세스 형태를 감안할 필요가 있음.
- 가능하다면 최소한의 테이블이 클러스터링 되도록 다른 대안을 강구하는 것이 중요하다.
4.2.2. 부분적인 클러스터링( 단일 테이블 클러스터링 )
- 클러스터링을 하더라도 단위 클러스터가 지나치게 커지지 않고
- 저장 밀도도 크게 나쁘게 하지 않으며
- 업무적인 결합도도 양호한 형태로 하는 것.
- tab1 + tab2 만 다중테이블 클러스터링, tab3.col3은 단일테이블 클러스터링을 하는 형태
4.2.3. 단일테이블 클러스터링( 그래서 )
- 현실에서는 다양하게 클러스터링 되는 경우는 매우 드물다.
- 조인의 효율성 향상을 위한 다중 클러스터링은 가능한 피하는 것이 좋다.
- 대량의 범위를 자주 처리하는 테이블만 클러스터링을 한다.
2. 단위 클러스터링 크기 결정
4.2.4. 단위 클러스터링 크기 결정
- 가능하다면 로우의 길이가 길지 않을수록 좋고
- 단위 클러스터의 크기를 지나치게 크지 않도록 하는 것이 바람직함
- 단위 클러스터의 크기는 단지 하나의 블록에 몇 개의 단위 클러스터를 생성하도록 허용할 것인가를 좌우할 뿐.
- 계산 방법
(1) 블록당 유효 저장공간 크기 = (블록 크기 - 블록헤더 크기) * (100-pctfree) / 100(2) 로우의 평균 길이 산정(3) 클러스터키 별 로우 수를 구한다.(4) 단위 클러스터의 크기를 계산하고 결정한다.
- 생성 방법
(1) 클러스터를 생성CREATE CLUSTER sales_cluster (sale_date varchar2(8))STORAGE ( storage_clause.... ) PCTFREE 10 PCTUSED 60 SIZE 2000;(2) 클러스터 인덱스 생성CREATE INDEX sales_cluster_idx ON CLUSTER sales_cluster;(3) 기준 테이블의 명칭을 변경RENAME sales TO sales_copy;(4) 클러스터 내에 테이블 생성.CREATE TABLE sales (...) CLUSTER sales_cluster ( sale_date );(5) 데이터 저장INSERT INTO sales SELECT * FROM sale_copy WHERE sale_date > '20010101';(6) 기존 테이블 삭제DROP TABLE sales_copy;
3. 클러스터를 사용하기 위한 조치
4.2.5. 클러스터 사용을 위한 조치
- 클러스터 키 컬럼을 첫 번째로 하는 결합 인덱스를 생성시키지 말 것
클러스터 키를 사용하지 않고, 결합 인덱스를 사용할 수 있다.
- 클러스터가 반드시 사용되어지기를 원한다면 액세스 경로를 고정시킨다.
힌트 /*+ CLUSTER(sales) */ 을 사용해서 결합 인덱스 사용하더라도 클러스터를 사용하도록 한다.