2.1. B-tree 인덱스
2010.10.04 20:55
2.1. B-Tree 인덱스
2.1.1. B-Tree인덱스
- 관계형데이터베이스의 기본적인 인덱스, Key값이 많을경우 사용에 이점이 된다.
- 특징: 테이블의 로우가 어떤 위치에 있든 동일한 처리방법과 속도로 접근할 수 있다
- 나무구조(Tree)처럼 가지에 해당하는 브랜치 블럭과 잎사귀에 해당하는 리프 블럭이 있다.
- 리프블록 < 브랜치블록 < root블록
- unique Scan일 경우 바로 테이블을 엑세스 하고 멈추지만,
- 범위 스캔일 경우 root블록->브랜치블록->리프블록 으로 스캔한다.
Range Scan일 경우
-
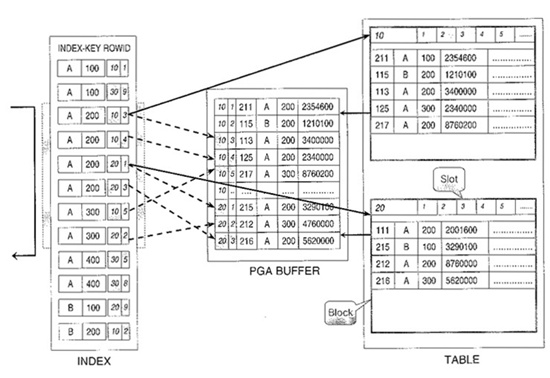
인덱스는 구성컬럼과 ROWID로 정렬되어 있다. ROWID에는 로우가 저장된 블록의 주소, 로우의 슬롯번호가 기록되어 있다.
- 처리할 범위의 첫번째 인덱스로우를 브랜체블록을 통해 리프블록을 액세스한 다음 거기의 ROWID로 블록을 찾는다.
SGA부터 찾아보고 없으면 디스크에 액세스해서 복사본을 SGA에 복사한다 - 새롭게 액세스한 데이터블록정보를 PGA로 가져와서 해당 SQL의 처리버퍼에 넣는다 (일명 원 버퍼)
- 인덱스블록을 액세스한 내용을 PGA버퍼에서 찾아 다른 조건까지 검증하여 성공한 로우만 운반단위로 보낸다 만약 클러스터링 팩터가 좋다면 여러건의 인덱스 스캔을 하나의 버퍼에서 처리할 수 있다.
- PGA버퍼에서 찾을 수 없다면 다시 다른 블록을 SGA에 액세스하여 새로운 블럭을 담고 위의 처리를 반복수행한다.
- 리프블록에서 액세스한 로우가 처리범위를 넘으면 처리를 종료한다.
2.1.2. B-Tree 인덱스의 조작
1. 인덱스 생성(Creation)
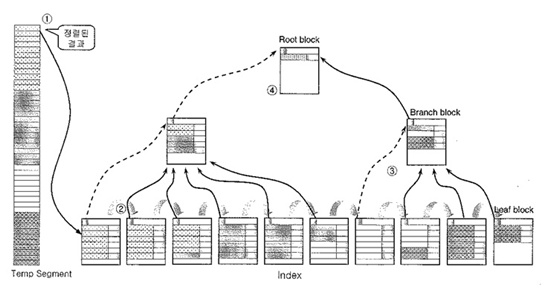
다음과 같은 방법으로 인덱스가 저장되기 때문에 인덱스 블럭에 많은 로우를 담게 될 경우
1) 리프블럭 감소
2) 브랜치 블럭의 깊이 감소가 일어날 수 있다.
그러므로 인덱스 컬럼 수 ↓, 큰 블럭 사이즈 지정, PCTFREE 최소 로 정의한다.
인덱스 블럭의 분할
인덱스 로우는 정렬이 되어 저장 되어야 하는 이유 때문에
이미 생성된 구조에 새로운 로우가 삽입되면 기존의 위치에 파고 들어가는 문제 발생
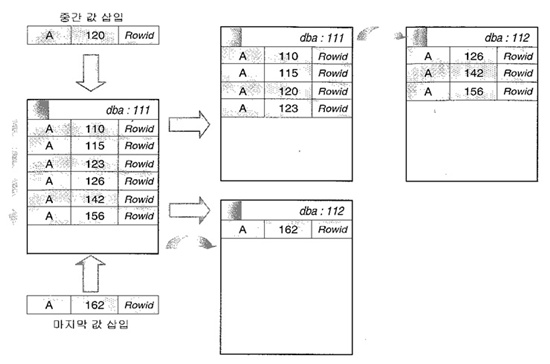 1. 마지막 값 삽입 : PCTFREE에 도달한 블럭일 경우엔 새로운 블럭에 등록2. 중간값 삽입 : PCTFREE가 초과하게 되므로 분할이 발생, 2개의 블럭으로 수정되는데 2/3만 채우면서 양쪽 모두 재편* 분할이 일어난 블럭에 새로운 값이 들어오지 않으면 저장공간 낭비 => 인덱스 재생성이 효율적이다.
1. 마지막 값 삽입 : PCTFREE에 도달한 블럭일 경우엔 새로운 블럭에 등록2. 중간값 삽입 : PCTFREE가 초과하게 되므로 분할이 발생, 2개의 블럭으로 수정되는데 2/3만 채우면서 양쪽 모두 재편* 분할이 일어난 블럭에 새로운 값이 들어오지 않으면 저장공간 낭비 => 인덱스 재생성이 효율적이다.
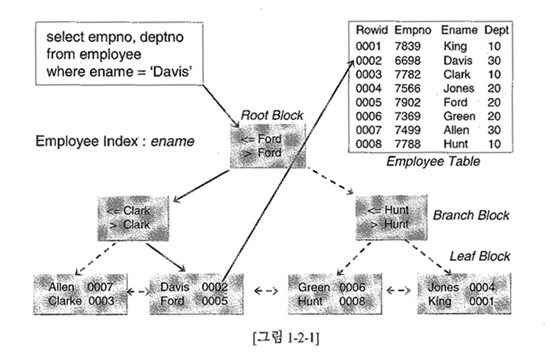
인덱스를 경유한 검색
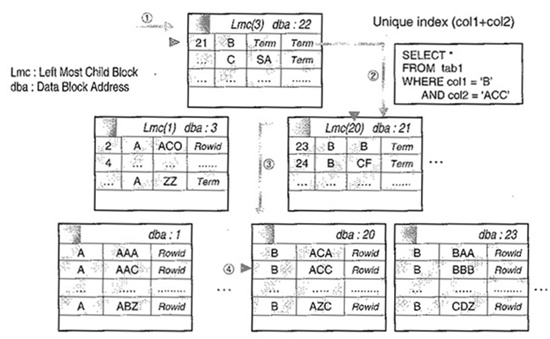
-
루트 블록을 찾는다.
-
주어진 값보다 같거나 최소값을 찾는다.(찾는값 >= 인덱스값)
-. 찾는 값 < 인덱스 값 (Lmc에 있는 dba로 이동)
-. 찾는 값 = 인덱스 값 (해당 dba로 이동)
-. 찾는 값 > 인덱스 값 (검색 후 찾는 값 = 인데스 값이면 해당 dba로 이동 그렇지 않으면, 찾는 값 < 인데스 값을 만족하는 인덱스 최소값) -
리프 블록을 찾을 때까지 ② 의 단계를 반복해서 수행
-
리프 블록에서 주어진 값을 가진 키를 찾아 존재하면 ROWID를 이용해 테이블을 액세스하고, 그렇지 않으면 'No Data found'로 결과 반환 만약, col2의 조건을 'ACC'가 아닌 'AC%'로 바꾸면
-
Col1 = 'B'이면서 Col2 = 'AC'보다 같거나 큰 것에서 스캔을 시작, 'AD' 보다 작으면 테이블을 액세스하고, 그렇지 않으면 종료한다.
* lmc는 브랜치 블럭의 첫 번째 로우의 값보다 적은 값을 갖는 하위의 블럭의 주소정보(dba:data block address)를 말한다.
2.1.3. 리버스 키 인덱스