1. Nested Loops 조인
2011.03.23 04:50
(1) 기본 메커니즘
|
Begin For outer in (select deptno, empno, rpad(ename, 10) ename from emp) Loop -- outer 루프 For inner in (select dname from dept where deptno = outer.deptno) Loop ? inner 루프 Dbms_ouput.put_line(outer.empno || ‘ : ‘ || outer.ename || ‘ : ‘ || inner.dname); End loop; End loop; End; SELECT /*+ ORDERED USE_NL(d) */ e.EMPNO, e.ENAME, d.DNAME FROM EMP e, DEPT d WHERE d.DEPTNO = e.DEPTNO |
PL/SQL문은 내부적으로 쿼리를 반복 수행하지 않는다는 점만 다르고, 쿼리와 100% 같은 순서로 데이터를 액세스하고,
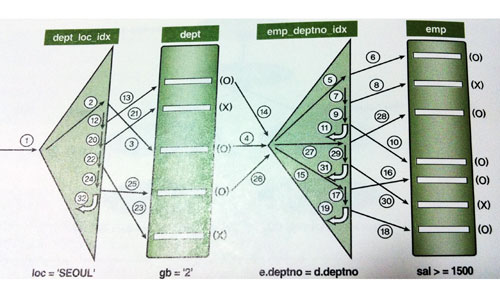
데이터 출력순서도 같다. (2) 힌트를 이용해 NL 조인을 제어하는 방법 SELECT /*+ ORDERED USE_NL(e) */ * -- 두 개의 테이블 조인 FROM DEPT d, EMP e WHERE e.DEPTNO = d.DEPTNO DEPT 테이블을 기준으로 EMP테이블과 조인할 때 NL방식으로 조인. DEPT를 Driving 또는 OUTER TABLE , EMP를 INNER TABLE 이라고 한다. ※ Outer 와 Inner 의 정의 NL조인 소트 머지 조인 해시 조인 실행계획상 위쪽 Outer(=Driving) 테이블 Outer(=First) 테이블 Build Input 실행계획상 아래쪽 Inner(=Driven) 테이블 Inner(=Second) 테이블 Probe Input - NL과 소트 머지 조인 : 위쪽에 있는 테이블을 스캔 하면서 아래쪽 테이블을 탐색하는 메커니즘 해시 조인 : 아래쪽 테이블을 스캔 하면서 위쪽 테이블을 탐색하는 메커니즘 - 해시 조인에서도 Build Input을 Driving 테이블이라고 표현하기도 하지만 소트 머지 조인에서는 그런 표현을 쓰지 않음. SELECT /*+ ORDERED USE_NL(B) USE_NL(C) USE_HASH(D) */ * FROM A,B,C,D WHERE …… 조인 순서 : A -> B -> C -> D B와 조인할 때 그리고 이어서 C와 조인할 때는 NL방식으로 조인, D와 조인할 때는 해시 방식으로 조인하라는 뜻. SELECT /*+ LEADING(C,A,D,B) USE_NL(A) USE_NL(D) USE_HASH(B) */ * FROM A,B,C,D WHERE …… 9i까지는 LEADING 힌트에 인자를 하나만 입력 10g부터는 LEADING 힌트에 2개 이상 인자를 기술할 수 있도록 기능 개선 SELECT /*+ USE_NL(A,B,C,D) */ * FROM A,B,C,D WHERE …… ORDERED나 LEADING를 기술하지 않아 4개 테이블을 NL방식으로 조인 순서는 옵티마이저가 정하도록 한다. (3) NL 조인 수행 과정 분석 SELECT /*+ ORDERED USE_NL(e) */ e.EMPNO, e.ENAME, d.DNAME, e.JOB, e.SAL FROM DEPT d, EMP e WHERE e.DEPTNO = d.DEPTNO …………………… ① AND d.LOC = ‘SEOUL’ …………………… ② AND d.GB = ‘2’ …………………… ③ AND e.SAL >= 1500 …………………… ④ ORDER BY SAL DESC 인덱스 PK_DEPT : DEPT.DEPTNO DEPT_LOC_IDX : DEPT.LOC PK_EMP : EMP.EMPNO EMP_DEPTNO_IDX : EMP.DEPTNO EMP_SAL_IDX : EMP.SAL Execution Plan ---------------------------------------------------------------------------------- 0 0 SELECT STATEMENT 1 0 SORT ORDER BY 2 1 NESTED LOOPS 3 2 TABLE ACCESS BY INDEX ROWID DEPT 4 3 INDEX RANGE SCAN DEPT_LOC_IDX 5 4 TABLE ACCESS BY INDEX ROWID EMP 6 5 INDEX RANGE SCAN EMP_DEPTNO_IDX 1. DEPT.LOC = ‘SEOUL’ 을 만족하는 레코드를 찾기 위해 DEPT_LOC_IDX 인덱스를 범위 스캔 2. 인덱스 ROWID로 DEPT테이블 액세스해 DEPT.GB =’2’ 필터조건을 만족하는 레코드를 찾는다. 3. DEPT 테이블에서 읽은 DEPTNO 값을 가지고 조인 조건을 만족하는 EMP 쪽 레코드를 찾기 위해 EMP_DEPTNO_IDX 인덱스를 범위 스캔. 4. 인덱스 ROWID로 EMP테이블 액세스해 SAL >= 1500 필터 조건을 만족하는 레코드를 찾는다. 5. SAL 컬럼 기준 내림차순으로 정렬 후 결과 리턴. 각 단계를 완료하고 나서 다음 단계로 넘어가는게 아니라 한 레코드씩 순차적으로 진행한다. 단, ORDER BY는 작업을 모두 완료 후 전체 집합을 대상으로 정렬. - DEPT_LOC_IDX 인덱스를 스캔하는 양에 따라 전체 일량 좌우 - 부하지점 1. 단일 컬럼 인덱스를 스캔하여 읽고, 그 만큼의 테이블 Random 액세스 발생. 2. EMP_DEPTNO_IDX 인덱스를 탐색하는 부분 (Outer 테이블인 DEPT를 읽고 나서 조인 액세스가 얼만큼 발생하느냐에 따라 결정) 3. EMP_DEPTNO_IDX를 읽고 나서 EMP 테이블을 액세스하는 부분 - OLTP(Online Realtime Transaction Processing) 시스템에서 조인을 튜닝 : 일차적으로 NL조인부터 고려. 1. NL 조인 메커니즘을 따라 각 단계의 수행 일량을 분석해 과도한 Random 액세스가 발생하는 지점 파악. 2. 조인 순서를 변경해 발생량을 줄일 수 있는 경우가 있고, 그렇지 못할 때는 인덱스 컬럼 구성을 변경하거나 다른 인덱스의 사용을 고려. 3. 여러 가지 검토한 결과 NL조인이 효과적이지 못할 땐, 해시조인이나 소트 머지 조인을 검토. (4) NL 조인의 특징 * Random 액세스 위주의 조인 방식 - 인덱스 구성이 완벽해도 대량의 데이터 조인할 때 비효율적 * 조인을 한 레코드씩 순차적으로 진행 - 먼저 액세스되는 테이블의 처리 범위에 의해 전체 일량 결정 * 인덱스 구성 전략이 특히 중요 즉, 특징을 종합하면 NL조인은 소량의 데이터를 주로 처리, 부분범위처리가 가능한 온라인 트랜젝션 환경에 적합한 조인 방식. (5) NL 조인 튜닝 실습
테이블 JOBS,EMPLOYEES 인덱스 PK_JOBS : JOBS.JOB_ID JOBS_MAX_SAL_IX: JOBS.MAX_SALARY PK_EMPLOYEES : EMPLOYEES.EMPLOYEE_ID EMP_JOB_IX : EMPLOYEES.JOB_ID EMP_HIREDATE_IX : EMPLOYEES.HIRE_DATE SELECT /*+ ORDERED USE_NL(e) INDEX(j) INDEX(e) */ j.JOB_TITLE, e.FIRST_NAME, e.LAST_NAME, e.HIRE_DATE, e.SALARY, e.EMAIL,e.PHONE_NUMBER FROM JOBS j, EMPLOYEES e WHERE e.JOB_ID = j.JOB_ID …………………… ① AND j.MAX_SALARY >= 1500 …………………… ② AND j.JOB_TYPE = ‘A’ …………………… ③ AND e.HIRE_DATE >= TO_DATE(‘19960101’, ‘yyyymmdd’) …………………… ④ - 트레이스 결과가 아래 같다면, Row Row Source Operation ---------------------------------------------------------------------------------- 5 NESTED LOOPS 3 TABLE ACCESS BY INDEX ROWID JOBS 278 INDEX RANGE SCAN JOBS_MAX_SAL_IX 5 TABLE ACCESS BY INDEX ROWID EMPLOYEES 8 INDEX RANGE SCAN EMP_JOB_IX 불필요한 테이블 액세스를 많이 한 셈. 액세스 후 필터링되는 비율이 높다면 인덱스에 테이블 필터 조건 컬럼을 추가하는 것을 고려. - JOBS_MAX_SAL_IX 에 JOB_TYPE 컬럼 추가
< ① > Row Row Source Operation ---------------------------------------------------------------------------------- 5 NESTED LOOPS 3 TABLE ACCESS BY INDEX ROWID JOBS 3 INDEX RANGE SCAN JOBS_MAX_SAL_IX 5 TABLE ACCESS BY INDEX ROWID EMPLOYEES 8 INDEX RANGE SCAN EMP_JOB_IX 비효율적인 액세스가 없어 보이나 테이블 액세스하기 전 인덱스 스캔 단계에서의 일량을 확인하지 못했으므로 튜닝이 끝났다고 볼 수 없다. 7 버전에서는 ROW 부분에 각 단계의 처리한 건수를 보여주었으나 8i 부터 9i 에서 출력 건수를 보여주는 방식으로 바뀌어 각 단계의 처리 일량을 따로 분석해야 했다. 그래서 9iR2 부터는 각 처리 단계별 논리적인 블록 요청 횟수(cr)와 디스크에서 읽은 블록 수(pr), 디스크에 쓴 블록 수(pw) 등을 표시했다. < ② > Row Row Source Operation ---------------------------------------------------------------------------------- 5 NESTED LOOPS (cr=1015 pr=255 pw=0) 3 TABLE ACCESS BY INDEX ROWID JOBS (cr=1003 pr=254 pw=0) 3 INDEX RANGE SCAN JOBS_MAX_SAL_IX (cr=1000 pr=254 pw=0) 5 TABLE ACCESS BY INDEX ROWID EMPLOYEES (cr=12 pr=1 pw=0) 8 INDEX RANGE SCAN EMP_JOB_IX (cr=8 pr=0 pw=0) JOBS_MAX_SAL_IX 인덱스로부터 3건을 리턴하기 위해 인덱스 블록을 1000개 읽음. ==> 튜닝 : JOBS_MAX_SAL_IX 컬럼 순서를 조정해 JOB_TYPE + MAX_SALARY 순으로 구성 (다른 쿼리에 미치는 영향도 분석이 선행). Row Row Source Operation ---------------------------------------------------------------------------------- 5 NESTED LOOPS (cr=2732 pr=386 pw=0) 1278 TABLE ACCESS BY INDEX ROWID JOBS (cr=166 pr=2 pw=0) 1278 INDEX RANGE SCAN JOBS_MAX_SAL_IX (cr=4 pr=0 pw=0) 5 TABLE ACCESS BY INDEX ROWID EMPLOYEES (cr=2566 pr=384 pw=0) 8 INDEX RANGE SCAN EMP_JOB_IX (cr=2558 pr=383 pw=0) 스캔한 블록이 4개뿐, 필터링되는 레코드도 전혀 없는 것으로 보아 JOBS 테이블을 읽는 부분에서 비효율은 없다. 문제는 JOBS 테이블을 읽고 EMPLOYEES 테이블과의 조인 시도 횟수 ==> 튜닝 : 조인 순서를 바꾸는 것 고려한다. 만약 HIRE_DATE 조건절에 부합하는 레코드가 별로 없다면 튜닝에 성공 가능성이 높다. 하지만, 반대 결과가 나타날 수 있다. ---------------------------------------------------------------------------------------------------------------------- 다음은 NL조인과 관련된 3가지 확장 메커니즘 설명 ---------------------------------------------------------------------------------------------------------------------- (6) 테이블 Prefetch - Prefetch : 디스크 I/O를 수행하려면 비용이 많이 들기 때문에 한 번 I/O Call 이 필요한 시점에, 곧이어 읽을 가능성이 큰 블록들을 캐시에 미리 적재해 두는 기능. - 9i부터 해당 테이블 액세스 단계에 Prefetch 기능이 적용되었음을 표현하기 위해, 인덱스 rowid에 의한 Inner 테이블 액세스가 NESTED LOOPS 위쪽에 표시되곤 한다. SELECT * FROM DEPT d, EMP e WHERE e.DEPTNO = d.DEPTNO Execution Plan ---------------------------------------------------------------------------------- 0 0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=4 Card=14 Bytes=868) 1 0 TABLE ACCESS (BY INDEX ROWID) OF ‘EMP’ (TABLE) (Cost=1 Card=4 Bytes=128) 2 1 NESTED LOOPS (Cost=4 Card=14 Bytes=868) 3 2 TABLE ACCESS (FULL) OF ‘DEPT’ (TABLE) (Cost=3 Card=4 Bytes=120) 4 3 INDEX (RANGE SCAN) OF ‘EMP_DEPTNO_IDX’ (INDEX) (Cost=0 Card=5) (_table_lookup_prefetch_size를 0으로 설정하면 전통적인 방식의 NL조인 실행계획으로 되돌아간다.) - NL조인에서 항상 새 포맷의 실행계획이 나타나는 것은 아니다. 기본적으로 Outer 쪽 인덱스를 Unique Scan 할 때는 작동하지 않는다. - 새 포맷의 테이블 Prefetch 실행계획이 나타나는 경우 1. Inner 쪽 Non-Unique 인덱스를 Range Scan 할 때는 항상 나타난다. 2. Inner 쪽 Unique 인덱스를 Non-Unique 조건(모든 인덱스 구성 컬럼이 ‘=’ 조건이 아닐 때)으로 Range Scan 할 때도 항상 나타난다. 3. Inner 쪽 Unique 인덱스를 Unique 조건(모든 인덱스 구성 컬럼이 ‘=’ 조건)으로 액세스할 때도 나타날 수 있다. 이때 인덱스는 Range Scan 으로 액세스한다. 테이블 Prefetch 실행계획이 안 나타날 때는 Unique Scan으로 액세스한다. ▶ 세 번째 경우로 테이블 Prefetch가 작동하는 경우 (흔치 않음) SELECT /*+ ORDERED USE_NL(b) CARDINALITY(a 110) */ MAX(a.최종보고일자), AVG(b.주권주식주), COUNT(*) FROM 지분보고내역 a, 지분보고 b WHERE b.회사코드 = a.회사코드 AND b.보고서구분코드 = a.보고서구분코드 AND b.최초보고일자 = a.최초보고일자 AND b.보고서id = a.보고서id AND b.보고일련번호 = a.보고일련번호 AND a.회사코드 BETWEEN ‘000010’ AND ‘00011’ Row Row Source Operation ---------------------------------------------------------------------------------- 1 SORT AGGREGATE (cr=1282 pr=0 pw=0) 332 NESTED LOOPS(cr=1282 pr=0 pw=0) 332 TABLE ACCESS BY INDEX ROWID (cr=284 pr=0 pw=0) 332 INDEX RANGE SCAN 지분보고내역_PK (cr=5 pr=384 pw=0) 332 TABLE ACCESS BY INDEX ROWID 지분보고 (cr=998 pr=383 pw=0) 332 INDEX UNIQUE SCAN 지분보고_PK (cr=666 pr=383 pw=0) - CARDINALITY 힌트를 사용해서 드라이빙 집합의 카디널리티를 조금씩 증가 시켜며 테스트했을 때 110까지는 전통적인 방식대로 NL조인 아래쪽에 위치, 111로 지정하는 순간 아래와 같이 실행 계획이 바뀐다. (PK인덱스를 Range Scan 하면서 테이블을 NL조인 위쪽에서 엑세스 하는 것 확인) SELECT /*+ ORDERED USE_NL(b) CARDINALITY(a 111) */ …… Row Row Source Operation ---------------------------------------------------------------------------------- 1 SORT AGGREGATE (cr=1231 pr=0 pw=0) 332 TABLE ACCESS BY INDEX ROWID 지분보고 (cr=1231 pr=0 pw=0) 665 NESTED LOOPS(cr=952 pr=2 pw=0) 332 TABLE ACCESS BY INDEX ROWID (cr=284 pr=0 pw=0) 332 INDEX RANGE SCAN 지분보고내역_PK (cr=5 pr=0 pw=0) 332 INDEX UNIQUE SCAN 지분보고_PK (cr=668 pr=0 pw=0) ※ 여러 테스트를 통해서, Inner 쪽 테이블을 Unique 조건으로 액세스할 때 테이블 Prefetch 실행계획이 나타나는 것을 볼 수 있었지만, 저자도 정확한 규칙을 찾지 못함. (7) 배치 I/O (공식적으로 알려진 바가 없음) - 11g 에서 시작된 메커니즘 - Outer 테이블로부터 액세스되는 Inner 쪽 테이블 블록에 대한 디스크 I/O Call 횟수를 줄이기 위해 테이블 Prefetch에 이어 추가로 도입된 메커니즘. - Inner 쪽 인덱스만으로 조인을 한 후, 테이블과의 조인은 나중에 일괄 처리하는 메커니즘인 것으로 추정. - nlj_batching 힌트 사용. (테이블 Prefetch 방식으로 전환 : no_nlj_batching, nlj_prefetch 힌트 사용) - 테이블 액세스를 나중에 하지만 부분범위처리는 작동. (인덱스와의 조인을 모두 완료하고 나서 테이블을 액세스하는 것이 아니라 일정량씩 나누어 처리) ▶ 배치 I/0 방식을 표현한 실행계획 Execution Plan ---------------------------------------------------------------------------------- 0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=16 Card=14 Bytes=2K) 1 0 NESTED LOOPS 2 1 NESTED LOOPS (Cost=16 Card=14 Bytes=2K) 3 2 TABLE ACCESS (FULL) OF ‘EMP’ (TABLE) (Cost=2 Card=14 Bytes=1K) 4 2 INDEX (UNIQUE SCAN) OF ‘PK_DEPT’ (INDEX(UNIQUE)) (Cost=0 Card=1) 5 1 TABLE ACCESS (BY INDEX ROWID) OF ‘DEPT’ (TABLE) (Cost=1 Card=1 Bytes=30) 아래 설명은 오라클의 공식적인 내용이 아니라, 저자의 경험적 사실들을 설명하려고 세운 가설. 1. 드라이빙 테이블에서 일정량의 레코드를 읽어 Inner 쪽 인덱스와 조인하면서 중간 결과집합을 만든다. 2. 중간 결과집합이 일정량 쌓이면 Inner 쪽 테이블 레코드를 액세스. 이때 테이블 블록을 버퍼 캐시에서 찾으면 바로 최종 결과집합에 담고, 못 찾으면 중간 집합에 남겨 둔다. 3. 2번 과정에서 남겨진 중간 집합에 대한 Inner 쪽 테이블 블록을 디스크로부터 읽는다. 이때 Multiple Single Block I/O 방식을 사용. 4. 버퍼 캐시에 올라오면 테이블 레코드를 읽어 최종 결과 집합에 담는다. 5. 모든 레코드를 처리하거나 사용자가 Fetch Call 을 중단할 때까지 1~4번 과정을 반복한다. ▶ 주목할 점 배치 I/0 방식을 사용할 때, Inner 쪽 테이블 블록이 모두 버퍼 캐시에서 찾아지지 않으면 즉, 실제 배치 I/0가 작동한다면 데이터 정렬 순서가 달라질 수 있다. 모두 버퍼 캐시에서 찾을 때는 이전 메커니즘과 똑 같은 정렬 순서를 보인다. 테이블 Prefetch 방식이나 전통적인 방식으로 NL 조인할 때는 디스크 I/O가 발생하든 안 하든 데이터 정렬 순서가 항상 일정하다. (8) 버퍼 Pinning 효과 - Prefetch와 배치 I/O 기능이 도입된 시점과 맞물려 버퍼 Pinning 기능에 변화가 생기다 보니 9i와 11g 에서 나타난 NL조인 실행계획 변화를 버퍼 Pinning 효과로 설명하는데 직접적인 연관성 없다. 8i에서 나타난 버퍼 Pinning 효과 - 테이블 블록에 대한 버퍼 Pinning 기능이 작동하기 시작 (단, 하나의 버퍼 블록만 Pinning) - 이 기능은 NL조인에서 Non-Unique 조건으로 Inner 쪽 테이블을 액세스할 때도 똑같은 작용. (따라서, Inner쪽 인덱스를 통해 액세스되는 테이블 블록이 계속 같은 블록을 가리키면 논리 I/O가 추가로 발생하지 않는다.) - 하나의 Outer레코드에 대한 Inner쪽과 조인을 마치고 다른 레코드를 읽기 위해 Outer 쪽으로 돌아오는 순간 Pin을 해제 9i에서 나타난 버퍼 Pinning 효과 - 8i와 같이 테이블 블록 버퍼에 대한 Pinning 작동 - Inner 쪽 인덱스 루트 블록에 대한 버퍼 Pinning 효과가 나타나기 시작 (단, 두 번째 액세스되는 순간 Pinning) - 9i부터는 Inner 쪽이 Non-Unique인덱스일 때는 테이블 액세스가 항상 NL조인 위쪽으로 올라가므로 항상 버퍼 Pinnig 효과가 나타나는 셈(이때 실행계획 변화를 버퍼 Pinning과 연관시켜 해석하는 오류 범하기 쉽다.) 반면, Inner쪽 Unique 인덱스를 Unique 조건으로 액세스할때는 테이블 액세스가 NL조인 위쪽으로 잘 올라가지 않고, 이때는 Unique 액세스이므로 Inner쪽에서 한 건만 읽고 바로 Outer 테이블 쪽으로 돌아가서 버퍼 Pinning 효과가 나타날 수 없다. 10g에서 나타난 버퍼 Pinning 효과 - Inner 쪽 인덱스 루트 블록과 테이블 블록을 Pinning 하는 기능 + 하나의 Outer 레코드에 대한 Inner 쪽과의 조인을 마치고 Outer 쪽으로 돌아오더라도 테이블 블록에 대한 Pinning 상태를 유지하는 기능 추가 DEPT 테이블 4건 T_EMP 테이블 140만건 SELECT /*+ ORDERED USE_NL(d) */ COUNT(e.ENAME), COUNT(d.DNAME) FROM T_EMP e, DEPT d WHERE d.DEPTNO = e.DEPTNO Row Row Source Operation ---------------------------------------------------------------------------------- 1 SORT AGGREGATE (cr=1409213 pr=0 pw=0) 1400000 NESTED LOOPS(cr=1409213 pr=0 pw=0) 1400000 TABLE ACCESS BY FULL T_EMP (cr=9211 pr=0 pw=0) 1400000 TABLE ACCESS BY INDEX ROWID DEPT (cr=1400002 pr=0 pw=0) 1400000 INDEX UNIQUE SCAN DEPT_PK (cr=2 pr=0 pw=0) - 인덱스 루트 블록을 버퍼 Pinning 확인 가능 (10g까지는 루트 블록만 Pinning 대상이지만, dept 테이블이 4건짜리 작은 테이블이므로 인덱스 루프 블록이 곧 리프 블록이라서 두 블록 이외에 추가적인 i/o발생하지 않음) - Inner 쪽을 액세스할 때마다 한 건씩만 읽고 Outer쪽으로 돌아가므로 테이블 블록은 Pinning 효과 나타나지 않음 위와 결과는 같으면서 Unique 인덱스를 Range Scan 하도록, SELECT /*+ ORDERED USE_NL(d) */ COUNT(e.ENAME), COUNT(d.DNAME) FROM T_EMP e, DEPT d WHERE d.DEPTNO BETWEEN e.DEPTNO AND e.DEPTNO + 1 Row Row Source Operation ---------------------------------------------------------------------------------- 1 SORT AGGREGATE (cr=9214 pr=0 pw=0) 1400000 TABLE ACCESS BY INDEX ROWID DEPT (cr=9214 pr=0 pw=0) 2800001 NESTED LOOPS(cr=9213 pr=0 pw=0) 1400000 TABLE ACCESS FULL T_EMP (cr=9211 pr=0 pw=0) 1400000 INDEX RANGE SCAN DEPT_PK (cr=2 pr=0 pw=0) - Unique 인덱스지만 RANGE SCAN 방식으로 액세스 하였고, 테이블 액세스가 NL조인 위쪽에 위치. 따라서, 140만개 레코드를 모두 처리하는 동안 버퍼 Pinning 상태가 유지됨으로 블록 I/O는 단 1회 발생. - 인덱스 루트 블록도 여전히 Pinning한 상태로 액세스 11g 에서 나타난 버퍼 Pinning 효과 - User Rowid로 테이블 액세스할 때도 버퍼 Pinning 효과 나타난다. - NL조인에서 Inner 쪽 루트 아래 인덱스 블록들도 Pinning하기 시작 (배치I/O 기능이 나타남과 동시에 이 기능이 추가되다 보니 NL조인 실행계획 변화가 인덱스 블록에 대한 버퍼 Pinning과 관련이 없다고 오해하기 쉬움) 배치 I/O방식으로 NL조인 SELECT /*+ ORDERED USE_NL_WITH_INDEX(d) NLJ_BATCHING(d) */ COUNT(e.ENAME), COUNT(d.DNAME) FROM T_EMP e, T_DEPT d WHERE d.NO = e.NO AND d.DEPTNO = e.DEPTNO Row Row Source Operation ---------------------------------------------------------------------------------- 1 SORT AGGREGATE (cr=14167 pr=0 pw=0) 14000 NESTED LOOPS(cr=14167 pr=0 pw=0) 14000 NESTED LOOPS(cr=167 pr=0 pw=0) 14000 TABLE ACCESS FULL T_EMP (cr=95 pr=0 pw=0) 14000 INDEX UNIQUE SCAN T_DEPT_PK (cr=72 pr=0 pw=0) 14000 TABLE ACCESS BY INDEX ROWID T_DEPT(cr=14000 pr=0 pw=0) - Inner쪽 14000번 액세스하는 동안 T_DEPT_PK 인덱스에 대한 블록 I/O는 72번만 발생 (버퍼 Pinning 작동) 테이블 Prefetch 방식으로 액세스 SELECT /*+ ORDERED USE_NL_WITH_INDEX(d) NLJ_PREFETCH(d) */ COUNT(e.ENAME), COUNT(d.DNAME) FROM T_EMP e, T_DEPT d WHERE d.NO = e.NO AND d.DEPTNO = e.DEPTNO Row Row Source Operation ---------------------------------------------------------------------------------- 1 SORT AGGREGATE (cr=14167 pr=0 pw=0) 14000 TABLE ACCESS BY INDEX ROWID T_DEPT (cr=14167 pr=0 pw=0) 28001 NESTED LOOPS(cr=167 pr=0 pw=0) 14000 TABLE ACCESS FULL T_EMP (cr=95 pr=0 pw=0) 14000 INDEX UNIQUE SCAN T_DEPT_PK (cr=72 pr=0 pw=0) - 테이블 Prefetch 방식으로 액세스하더라도 인덱스 블록에 대한 버퍼 Pinning 효과 나타난다. 11g에서 실행계획 변화가 인덱스 블록에 대한 버퍼 Pinning과 관련이 없음을 알 수 있다. 드라이빙 테이블이 무순위로 정렬되도록 (배치 I/0포맷) CREATE TABLE T_EMP AS SELECT * FROM SCOTT.EMP, (SELECT ROWNUM NO FROM DUAL CONNECT BY LEVEL <= 1000) ORDER BY DBMS_RANDOM.VALUE; SELECT /*+ ORDERED USE_NL_WITH_INDEX(d) NLJ_BATCHING(d) */ COUNT(e.ENAME), COUNT(d.DNAME) FROM T_EMP e, T_DEPT d WHERE d.NO = e.NO AND d.DEPTNO = e.DEPTNO Row Row Source Operation ---------------------------------------------------------------------------------- 1 SORT AGGREGATE (cr=28098 pr=0 pw=0) 14000 NESTED LOOPS(cr=28098 pr=0 pw=0) 14000 NESTED LOOPS(cr=14098 pr=0 pw=0) 14000 TABLE ACCESS FULL T_EMP (cr=94 pr=0 pw=0) 14000 INDEX UNIQUE SCAN T_DEPT_PK (cr=14004 pr=0 pw=0) 14000 TABLE ACCESS BY INDEX ROWID T_DEPT(cr=14000 pr=0 pw=0)
- 인덱스 블록도 버퍼 Pinning 효과가 나타나려면 같은 값으로 반복 액세스 해야 함. - 테이블 Prefetch 포맷을 사용해도 마찬가지
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 60 | 진행기록 | 운영자 | 2011.08.23 | 3318 |
| 59 | 1. 기본 개념 | 멋진넘 | 2011.06.28 | 13396 |
| 58 | 1. 테이블 파티셔닝 | suspace | 2011.06.21 | 6812 |
| 57 | 7장. 병렬 처리 | 운영자 | 2011.06.15 | 4610 |
| 56 | 6장. 파티셔닝 | 운영자 | 2011.06.15 | 3171 |
| 55 | 5장. 소트 튜닝 | 운영자 | 2011.06.15 | 3287 |
| 54 | 4장. 쿼리 변환 | 운영자 | 2011.06.15 | 3122 |
| 53 | 3장. 옵티마이저 원리 | 운영자 | 2011.06.15 | 3151 |
| 52 |
1. 소트 수행 원리
| 휘휘 | 2011.06.12 | 5732 |
| 51 | 1. 쿼리 변환이란? | 실천하자 | 2011.05.02 | 4927 |
| 50 |
1. 옵티마이저
| 실천하자 | 2011.04.18 | 11211 |
| » |
1. Nested Loops 조인
| suspace | 2011.03.23 | 7191 |
| 48 | 2장. 조인 원리와 활용 | 운영자 | 2011.03.23 | 3314 |
| 47 |
1. 인덱스 구조
[1] | 실천하자 | 2011.02.16 | 14190 |
| 46 | 1장. 인덱스 원리와 활용 | 운영자 | 2011.06.15 | 5607 |
| 45 |
온라인 OT 및 스터디 툴 사용 방법
| 휘휘 | 2011.02.16 | 3331 |
| 44 |
Front Page
| 운영자 | 2011.02.16 | 149419 |
| 43 | 2. 인덱스 기본 원리 | 실천하자 | 2011.02.21 | 3369 |
| 42 |
2. 소트 머지 조인
| 실천하자 | 2011.03.22 | 5801 |
| 41 | 2. 옵티마이저 행동에 영향을 미치는 요소 | 휘휘 | 2011.04.18 | 5094 |