3. 데이터 모델 측면에서의 검토
2011.06.13 14:20
3.데이터 모델 측면에서의 검토
?불합리한 데이터 모델이 SORT 유발하는 경우가 많은데, GROUP BY, UNION, DISTINCT 같은
연산자가 많을 경우 모델을 잘 정규화되지 않았거나, 모델 이상으로 발생한 데이터 중복을
제거하려는 과정에서 SORT를 유발함
CASE 1
아래의 테이블 관계는 1:M 관계인 과금과 수납 테이블인데 컨버젼(데이타이행)시 발생한 예외 Case 때문에
M:M 관계가 되어 1쪽 집합을 항상 GROUP BY를 하게 되고 이로 인해 성능이 나빠지는 경우이다.
1)1:M 정상관계 ERD

2)M:M 비정상관계 ERD
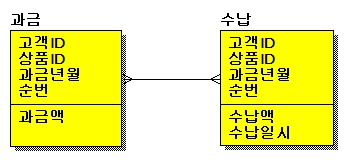
1:M으로 설계되어야 할 모델이 M:M으로 설계됨으로 인해서 한쪽(1쪽) 집합을 GROUPING해야 하는 불합리함이 존재함
3)M:M을 극복하기 위한 SQL
SELECT A.상품ID
, A.과금액
, B.수납액
, B.수납일시
FROM (
SELECT 고객ID
, 상품ID
, 과금연월
, SUM(과금액) 과금액
FROM 과금
WHERE 과금연월 = :과금연월
AND 고객ID = :고객ID
GROUP BY
, 고객ID
, 상품ID
과금연월
) A -- 1쪽 집합을 1:M의 관계를 만들기 위해 강제적으로 GROUP BY 처리함
, 수납 B
WHERE A.고객ID = B.고객ID (+)
AND A.상품ID = B.상품ID (+)
AND A.과금연월 = B.과금연월(+)
ORDER BY
A.상품ID
, B.순번;
▶위와 같은 불합리를 처리하기 위해 DATA MODELING 설계시 과금과 수납관계에서
구분코드(일반, 예외)에 따라 1:M의 서브타입으로 분리 및 설계 가능함
교재에서 처럼 Barker 표기법이 아닌 IE 표기법에선 모델에서 표기하긴 어려움
(개인적인 모델링 기법이 부족하기에...B팀으로 Skip... ^^;;;)
CASE 2
①PK외에 관리할 속성이 없거나, [가입상품]처럼 소수일 때, 테이블 개수를 줄이기 위해
자식 테이블과 통합하는 경우 발생되는 소트 부하 예제
②데이터 누락 및 정합성에도 문제가 없지만, 만약 고객별 가입상품 레벨의 데이터를
조회가 빈번할 경우 [고객별상품라인] 테이블이 이미 하위레벨(상태코드)로 내려왔기 때문에
가입일시만을 가져오기 위해서는 반드시 GROUP BY를 사용해야 하므로 성능에 안좋음
③반 정규화를 할 때 반드시 어플리케이션 레벨까지 고려를 해야 함
1)정규화가 잘된 ERD
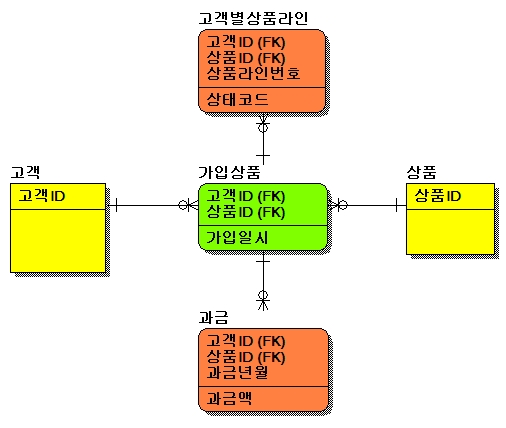
▶해당 SQL
SELECT 과금.고객ID
, 과금.상품ID
, 과금.과금액
, 가입상품.가입일시
FROM 과금
, 가입상품
WHERE 과금.고객ID (+) = 가입상품.고객ID
AND 과금.상품ID (+) = 가입상품.상품ID
AND 과금.과금연월(+) = :YYYYMM;
2)반정규화 된 ERD

▶해당 SQL
SELECT 과금.고객ID
, 과금.상품ID
, 과금.과금액
, 가입상품.가입일시
FROM 과금
, (
SELECT 고객ID
, 상품ID
, MIN(가입일시) 가입일시
FROM 고객별상품라인
GROUP BY
고객ID
, 상품ID
) 가입상품
WHERE 과금.고객ID (+) = 가입상품.고객ID
AND 과금.상품ID (+) = 가입상품.상품ID
AND 과금.과금연월(+) = :YYYYMM;
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 40 | 2. 서브쿼리 Unnesting | darkbeom | 2011.05.15 | 20209 |
| 39 | 2. 소트를 발생시키는 오퍼레이션 | 휘휘 | 2011.06.12 | 3826 |
| 38 | 2. 파티션 Pruning | 실천하자 | 2011.06.21 | 26468 |
| 37 |
3. 병렬 조인
| 실천하자 | 2011.06.28 | 7508 |
| 36 |
3. 다양한 인덱스 스캔 방식
| 멋진넘 | 2011.02.18 | 34220 |
| 35 |
3. 해시 조인
| darkbeom | 2011.03.20 | 21946 |
| 34 | 3. 옵티마이저의 한계 | 멋진넘 | 2011.04.19 | 8143 |
| 33 | 3. 뷰 Merging | 실천하자 | 2011.05.15 | 23847 |
| » |
3. 데이터 모델 측면에서의 검토
| 멋진넘 | 2011.06.13 | 6219 |
| 31 | 3. 인덱스 파티셔닝 | darkbeom | 2011.06.19 | 54558 |
| 30 |
4. 테이블 Random 액세스 부하
[1] | darkbeom | 2011.02.23 | 15102 |
| 29 | 4. 조인 순서의 중요성 | 운영자 | 2011.03.27 | 14732 |
| 28 | 4. 통계정보 Ⅰ | darkbeom | 2011.04.25 | 18542 |
| 27 | 4. 조건절 Pushing | 실천하자 | 2011.05.31 | 7390 |
| 26 |
4. 소트가 발생하지 않도록 SQL 작성
| 멋진넘 | 2011.06.12 | 8229 |
| 25 | 5. 테이블 Random 액세스 최소화 튜닝 | suspace | 2011.02.24 | 7326 |
| 24 | 6. 스칼라 서브쿼리를 이용한 조인 [1] | 휘휘 | 2011.03.28 | 6976 |
| 23 | 5. Outer 조인 | 실천하자 | 2011.03.29 | 5422 |
| 22 | 5. 카디널리티 | suspace | 2011.04.26 | 6227 |
| 21 | 5. 조건절 이행 | 휘휘 | 2011.05.29 | 5804 |