9. 비트맵 인덱스
2011.03.06 07:57
☞ "새로쓴 대용량 DB 1" 의 비트맵 인덱스 자료 바로가기
☞ "새로쓴 대용량 DB 1" 의 비트맵 실행계획 자료 바로가기
☞ "CBO 오라클 원리" 의 비트맵 인덱스 자료 바로가기
- B*Tree 인덱스
- 테이블 레코드를 가리키는 RowID 목록, 키 값 함께 저장 ☞ 즉, 레코드 수 만큼의 RowID, 키 값 저장
- RowID는 중복 값이 없지만, 키 값은 중복 가능
- 비트맵 인덱스
- 키 값에 중복이 없음
- 키 값별 하나의 비트맵 레코드
- 비트맵 상, 각 Bit가 하나의 테이블 레코드와 매핑 ☞ Bit가 1이면 상응하는 테이블 레코드가 해당 키 값 포함
1. 비트맵 인덱스 기본 구조
- 상품 테이블 구성 : 10개의 레코드, 색상의 값은 BLUE, GREEN, RED 3 종류
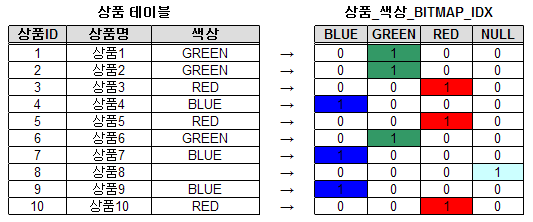
- 비트맵 인덱스 내부 구조(블록 덤프의 정보)
row#0( 8001) flag: ------, lock: 0, len=35
col 0; len 2; (4): 42 4c 55 45 ☞ 키 값 : BLUE
col 1; len 6; (6): 01 00 9f 4c 00 00 ☞ 시작 ROWID
col 2; len 6; (6): 01 01 a4 03 01 47 ☞ 종료 ROWID
col 3; len 15; (15): 00 c1 ae bb fa 02 c1 a1 10 c1 94 19 c2 dc 07 ☞ 비트맵
마지막 컬럼(col 3)은 시작 ROWID ~ 종료 ROWID 구간에 속한 테이블 레코드와 매핑되는 비트맵
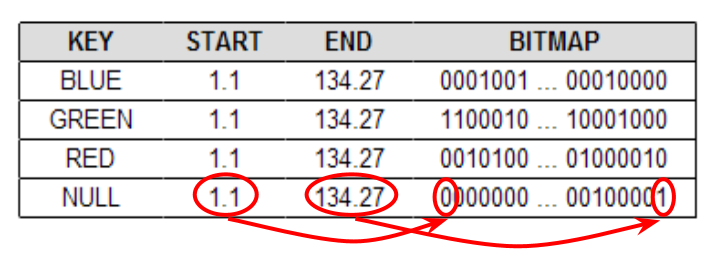
☞ 첫 번째와 마지막 Bit 의 ROWID 만 갖고 있다가 테이블 액세스가 필요 시
각 Bit가 첫 번째 Bit로부터 떨어져 있는 상대적 거리를 이용해 ROWID 환산
- 비트맵 위치와 ROWID 매핑
Q. 데이터 블록은 한 익스텐트 내에서 연속 상태로 저장. but, 익스텐트는 서로 인접하지 않음.
심지어 다른 데이터 파일에 저장 됨. 어떻게 시작 ROWID와의 상대적 거리로 정확한 레코드 위치를 파악하나?
A. 오라클이 한 블록에 저장할 수 있는 최대 레코드 개수를 제한 활용
- 예제 상황
- 상품 테이블의 총 블록 수 : 20 개
- 각 10개의 블록을 소유한 익스텐트 : 2 개
- 한 테이블 블록의 최대 레코드 개수 : 730 개
- 색상 컬럼에 비트맵 인덱스 생성
4개의 키 값(BLUE, GREEN, RED, NULL)에 각 14,600 (=730 X 20)개 Bit 할당 (초기값 0) 후 각 비트 설정
- 비트맵 인덱스 스캔으로 레코드 찾는 과정 (9,500번째 Bit가 1로 설정 된 레코드)
- floor(9500 / 730) = 13 ☞ 14번째 블록
- mod(9500, 730) = 10 ☞ 10번째 레코드
- 해당 레코드의 비트 값 설정하는 과정 (14번째 블록 10번째 레코드)
- 730 X 13 + 10 = 9,500
비트맵 인덱스는 키 값별로 하나의 레코드 생성 ☞ 저장할 키 값의 수 또는 로우 수가 아주 많을 시 한 블록에 담지 못 함
- 키 값의 수가 많을 때
- 키 값이 아주 많아 두 개 이상 블록이 필요시, B*Tree 인덱스 구조를 사용 → 값이 많을 수록 인덱스 높이 증가
- 아래의 그림 같은 구조 일 경우, B*Tree 인덱스보다 더 많은 공간을 차지할 수 있기에 비트맵 인덱스로 부적합
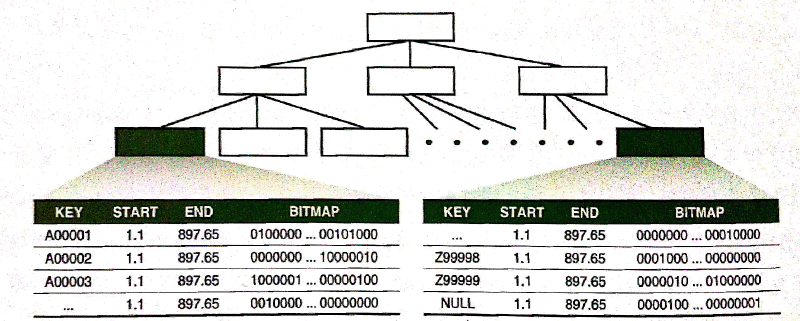
- 키 값별로 로우 수가 많을 때
- 테이블 로우 수가 많아 두 개 이상 블록이 필요 시
- 값 하나에 대한 비트맵을 저장하기 위해 2 + 1/2 블록만큼 공간 필요 시 아래의 그림 같은 구조로 저장
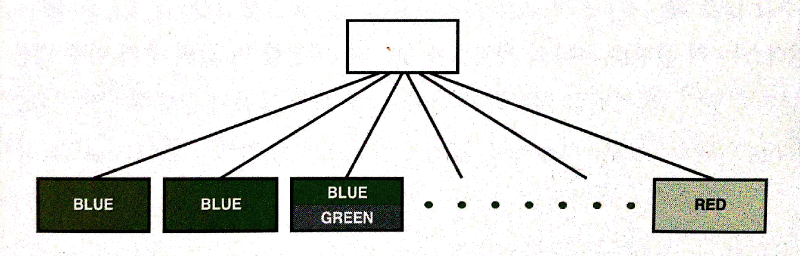
☞ 실제 테스트 시, 한 블록에 적어도 2개 비트맵 레코드가 담기도록 잘라서 저장
즉, 위 그림의 왼쪽 리프 블록 'BLUE' 에 대한 두 개의 비트맵 레코드 저장
- 비트맵 압축
- 비트맵을 압축하지 않았을 때 : 예제에서 본 것 처럼 모든 비트맵의 시작 ROWID 와 종료 ROWID 를 같게 표현
- 실제로는 여러가지 압축 알고리즘 사용으로 서로 다른 ROWID 범위를 갖음
- 위의 예처럼 키 값이 아주 많거나, 키 값별 로우 수가 많을 경우 등
1. 완전히 0으로 채워진 비트맵 블록이 생길 때 해당 블록 제거2. 비트맵 뒤쪽에 0 이 반복 될 때 해당 블록 제거3. 앞, 뒤, 중간 어디든 같은 비트맵 문자열이 반복 때 Checksum Bit 사용으로 압축
의 방법 으로 압축 알고리즘 사용
☞ 각 비트맵이 가리키는 ROWID 구간이 서로 달라지지만 시작 ROWID 와 종료 ROWID만 알고 있을 시
비트와 매핑되는 ROWID를 계산 하거나 다른 비트맵과 Bitwise 연산하는데 전혀 문제 없음
※ 참고 Checksum 이란?
2진수 자료에서 각 자리수의 배타적 논리합을 구한 것을 ‘검사합’(체크섬, checksum)이라 부른다.
이 값은 자료 내에 1이 홀수 개 있는지, 짝수 개 있는지로 결정할 수 있다.
∴ 2진수 자료에 검사합을 덧붙인 부호를 생각하여 확인.
2. 비트맵 인덱스 활용
- 성별처럼 ( "M" or "F" , "남" or "여" 등 ) Distinct Value 수가 적을 때 저장효율 ↑ (B*Tree 인덱스 대비 훨씬 적은 용량 차지)
※ Distinct Value 수가 아주 많은 컬럼이면 오히려 B*Tree 인덱스보다 많은 공간 차지
- 주로 다양한 분석관점(Dimension)을 가진 팩트성 테이블이 대표적 예
- Random 액세스 발생 시 B*Tree 와 같기 때문에 비트맵 인덱스 검색 시 큰 성능 차이 없음
(단, 스캔할 인덱스 블록이 줄어는 이점은 있음)
- 하나의 비트맵 인덱스 단독보다는 여러 비트맵 인덱스를 동시에 사용할 수 있는 특징으로
- 대용량 데이터 검색 시 성능 향상에 큰 효과
∵ Bitwise 연산을 통한 Bitwise AND, Bitwise OR, Bitwise Not 연산 가능
- 예시
select * from 상품
where (크기 = 'SMALL' OR 크기 is null
and 색상 = 'GREEN'

- 장점
- 비트맵 인덱스 이용 시, null 값에 대한 검색도 가능
- 여러 인덱스를 동시에 활용할 수 있는 장점으로 다양한 조건절이 사용되는 임의 질의가 많은 환경(ad-hoc query)에 적합
- 단점
- lock에 의한 DML 부하가 큼 ∵ 레코드 하나 변경 시 해당 비트맵 범위에 속한 모든 레코드 lock 상태
- ☞ OLTP 환경에 비트맵 인덱스를 쓰기에 부적합
※ 비트맵 인덱스는 읽기 위주의 대용량 DW (특히, OLAP) 환경에 아주 적합
3. RECORDS_PER_BLOCK
- 오라클은 한 블록에 저장할 수 있는 최대 레코드 개수를 제한
∴ 비트맵 위치와 rowid 매핑 가능
- 예시
- 오라클이 정한 블록당 최대 레코드 개수를 730으로 가정 시, 키 값마다 { 블록 수 x 730 } 만큼의 비트 할당
- but, 실제 블록 저장되는 평균적 레코드 개수는 여기에 한참 미치지 않기 때문에 비트맵 인덱스에 낭비되는 공간 ↑
☞ 블록에 저장될 수 있는 최대 레코드 개수 지정
- 블록에 당 레코드 개수 지정 명령
alter table t minimize records_per_block;
오라클은 t 테이블을 스캔함으로써 블록당 최대 레코드 개수를 조사하고
t 테이블에는 블록당 최대 7개의 레코드만 저장 됨
※ 참고 - 블록당 레코드 수 조회
select min(count(*)), max(count(*)), avg(count(*)) from t
group by dbms_rowid.rowid_block_number(rowid);
위의 minimize records_per_block 명령을 수행 후, 비트맵 인덱스 생성 시,
블록당 최대 7개 레코드가 담기는 것을 기준으로 키 값마다 { 블록 수 x 7 } 만큼 비트 할당
- 생각만큼 큰폭으로 줄지 않은 이유(7과 730은 100배 이상 차이)
☞ "오라클이 처음에 정한 블록당 최대 크기" 를 기준으로 비트 할 당 시내부적으로 사용한 압축 알고리즘으로 크기가 많이 줄어든 상태
블록당 레코드 개수가 정상치보다 낮은 상태에서 minimize records_per_block 명령을 수행하지 말아야 함
∵ 추가 데이터 입력 시 블록마다 공간이 많이 생기고, 비트맵 인덱스가 줄어드는 것 이상으로 테이블 크기가 커지는 결과 발생
- 오라클 고도화 원리와 해법 2 (bysql.net 2011년 1차 스터디)
- 작성자: 위충환 (실천하자)
- 최초작성일: 2011년 03월 05 일
- 본문서는 bysql.net 스터디 결과입니다 .본 문서를 인용하실때는 출처를 밝혀주세요. http://www.bysql.net
- 문서의 잘못된 점이나 질문사항은 본 문서에 댓글로 남겨주세요. ^^
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 20 | 5. 인덱스를 이용한 소트 연산 대체 | 멋진넘 | 2011.06.13 | 3356 |
| 19 | 6. IOT, 클러스터 테이블 활용 | 휘휘 | 2011.02.26 | 2751 |
| 18 | 6. 히스토그램 | 실천하자 | 2011.04.25 | 10917 |
| 17 | 6. 조인 제거 | 멋진넘 | 2011.05.30 | 4595 |
| 16 |
6. Sort Area를 적게 사용하도록 SQL 작성
| 실천하자 | 2011.06.14 | 8857 |
| 15 | 7. 인덱스 스캔 효율 [1] | 휘휘 | 2011.03.09 | 16887 |
| 14 | 7. 비용 | 휘휘 | 2011.05.03 | 6167 |
| 13 | 7. OR-Expansion | 멋진넘 | 2011.05.31 | 8718 |
| 12 | 7. Sort Area 크기 조정 | 실천하자 | 2011.06.14 | 15066 |
| 11 | 8. 인덱스 설계 | 멋진넘 | 2011.03.07 | 8345 |
| 10 | 7. 조인을 내포한 DML 튜닝 | 실천하자 | 2011.04.04 | 7171 |
| 9 | 8. 통계정보 Ⅱ [1] | 멋진넘 | 2011.04.30 | 31071 |
| 8 | 8. 공통 표현식 제거 | darkbeom | 2011.06.07 | 5220 |
| » |
9. 비트맵 인덱스
| 실천하자 | 2011.03.06 | 12341 |
| 6 |
8. 고급 조인 테크닉-1
[1] | darkbeom | 2011.04.04 | 13265 |
| 5 | 9. Outer 조인을 Inner 조인으로 변환 | darkbeom | 2011.06.07 | 7834 |
| 4 |
8. 고급 조인 테크닉-2
| suspace | 2011.04.05 | 7017 |
| 3 | 10. 실체화 뷰 쿼리로 재작성 | suspace | 2011.06.07 | 5531 |
| 2 | 11. 집합 연산을 조인으로 변환 | suspace | 2011.06.08 | 5994 |
| 1 | 12. 기타 쿼리 변환 [3] | 실천하자 | 2011.06.03 | 6646 |