1. 옵티마이저
2011.04.17 23:49
1. 옵티마이저
(1) 옵티마이저란?
- 정의 : 사용자가 요청한 SQL을 가장 효율적이고 빠르게 수행할 수 있는 최적(최저비용)의 처리경로를 선택해주는 DBMS의 핵심 엔진
- 역할 : 구조화된 질의언어(SQL)로 사용자가 원하는 결과집할을 정의하면 이를 얻는데 필요한 처리절차(Procedure)는 DBMS에 내장된 옵티마이저가 자동으로 생성

- 종류
- 규칙기반 옵티마이저 ( RBO : Rule-Based Optimizer )
- 비용기반 옵티마이저 ( CBO : Cost-Based Optimizer )
- 역사가 오래된 오라클의 경우는 RBO에서 출발하여 10g 부터 RBO 지원을 중단하고 CBO 사용
(2) 규칙기반 옵티마이저 ( = RBO = 휴리스틱 옵티마이저 ) : 미리 정해놓은 우선순위에 따라 액세스 경로를 평가하고 실행계획 선택
- RBO 사용 규칙 (액세스 경로별 우선순위) : 인덱스 구조, 연산자, 조건절 형태가 순위를 결정하는 주요인
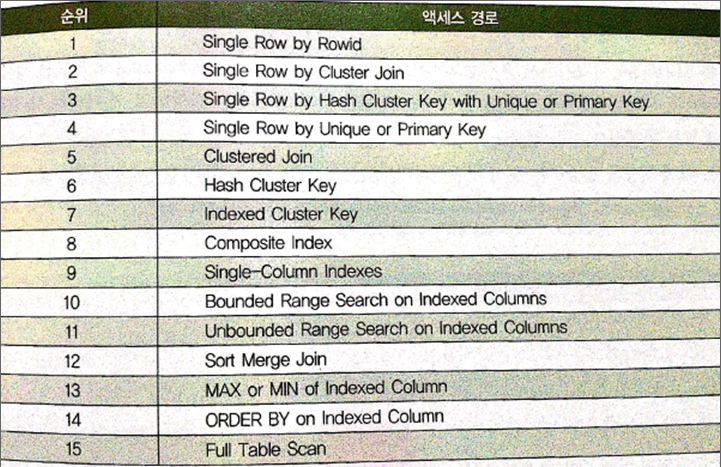
- OLTP 환경의 중소형 데이터베이스 시스템이면 RBO 규칙이 어느 정도 보편 타당성을 갖음
- 데이터량, 값의 수(number of distinct value), 컬럼 값 분포, 인덱스 높이, 클러스터링 팩터 같은 데이터 특성을 고려하지 않음
ex.1) 조건절 컬럼에 인덱스가 있을 시 무조건 인덱스를 사용, 항상 인덱스를 신뢰하며 Full Table Scan과의 손익 구분 X
☞ 인덱스를 경유하면서, 엑세스 데이터량이 일정 수준 이상이면 오히려 Full Table Scan이 유리
ex.2) "select /*+ rule */ * from emp order by empno" 실행 시, empno 컬럼에 인덱스가 있다면
인덱스를 이용하여 sort order by 연산을 대체함
∵ 부분범위 처리가 불가능한 상황이면 Full Table Scan 후 정렬하는 방법이 나은 데도 RBO 우선순위로는
인덱스 컬럼에 의한 Order by (14위)가 Full Table Scan (15위) 보다 높기 때문
- 예측 가능하고 일관성 있는 실행계획을 수립하며, 사용자가 원하는 처리경로로 유도하기 쉬움
- CBO는 같은 SQL 이더라도 데이터 특성에 따라 실행계획이 달라짐
(3) 비용기반 옵티마이저
- 비용(cost) : 쿼리를 수행하는데 소요되는 일량 또는 시간
- I/O 요청(call) 횟수만으로 비용 평가 → CPU 연산비용까지 감안, 수행 일량을 상대적 시간 개념으로 환산하여 비용 평가
- 미리 구한 테이블과 인덱스에 대한 여러 통계정보를 기초로 각 오퍼레이션 단계별 예상비용을 산정하여 합산한 총비용이 가장 낮은 실행계획 선택
- 비용 산정시 사용되는 오브젝트 통계항목
: 레코드 개수, 블록 개수, 평균 행 길이, 컬럼 값의 수, 컬럼 값 분포, 인덱스 높이, 클러스터링 팩터
+ 하드웨어적 특성을 반영한 시스템 통계정보(CPU 속도, 디스크 I/O 속도 등)
- 옵티마이저의 최적화 수행단계
1. 사용자가 던진 쿼리수행을 위해, 후보군이 될만한 실행계획을 찾음
2. 데이터 딕셔너리에 미리 수집해 놓은 오브젝트 통계 및 시스템 통계 및 시스템 통계정보를 이용해 각 실행계획의 예상비용 산정
3. 각 실행계획의 비용을 비교해서 최저비용을 갖는 하나 선택
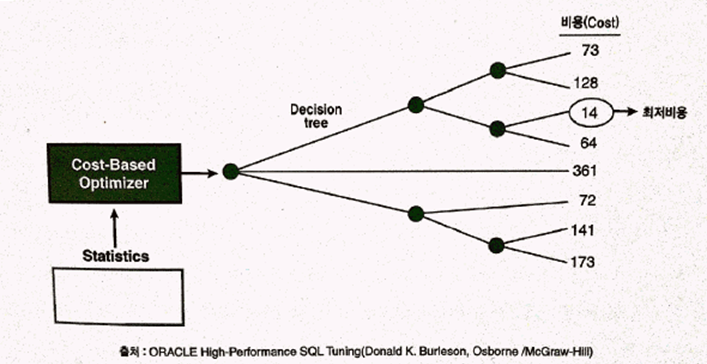
- 동적 샘플링 (Dynamic Sampling)
테이블과 인덱스에 대한 통계정보가 없거나 오래되어 신뢰할수 없을때 수행할수 있음
optimizer_dynamic_sampling 파라미터로 동적 샘플링 레벨 조정
기본 레벨 : 9i ☞ 1 → 10g ☞ 2 (통계정보 없는 테이블 발견시 무조건 동적 샘플링 수행)
0 : 수행 X, 1 : 다음 조건 만족시 수행
통계정보가 수집되지 않은 테이블이 적어도 하나 이상 있어야 함
그 테이블이 다른 테이블과 조인되거나 서브쿼리 또는 Non-mergeable View에 포함
그 테이블에 인덱스가 하나도 없음
그 테이블에 할당된 블록수 가 32개(샘플링을 위한 표본 블록수의 기본값) 보다 많음
레벨 설정은 10까지 가능, 레벨이 높을수록 적극적으로 샘플링을 하며 표본 블록개수 증가
동적 샘플링에 의한 통계정보는 데이터 딕셔너리에 영구저장되지 않음
하드 파싱할때마다 동적 샘플링을 위한 Recurisive SQL 추가 수행으로 성능 저하
☞ DB관리자 통계정보 관리 필요
동적 샘플링 시, SQL 트레이스에 Recurisive SQL 발견
SELECT /* OPT_DYN_SAMP */ … FROM …
- CBO 기준의 SQL 처리 절차 요약도
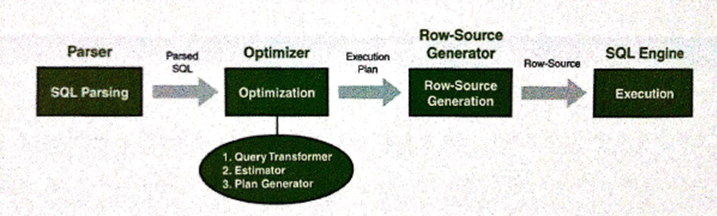
- SQL 파서(Parser) : 사용자가 실행한 SQL을 가장 먼저 받아서 처리하는 엔진
- Row-Source Generation : 최적화 과정을 거친 실행계획을 실행가능한 코드 또는 프로시저 형태로 포멧팅
- Query Transformer : SQL을 최적화하기 쉬운 형태를 변환을 시도 (변환 전후 결과가 동일함이 보장될 시)
- Estimator : 쿼리 오퍼레이션 각단계의 선택도(Selectivity), 카디널리티 (Cardinality), 비용(Cost) 계산
실행계획 전체에 대한 총 비용을 계산
I/O, CPU, 메모리 사용량 예측 (데이터베이스 오브젝트 통계정보, 시스템 성능 통계정보 이용)
- Plan Generator : 쿼리 수행 시, 후보군이 될 만한 실행계획 생성
- 스스로 학습하는 옵티마이저 (Self-Learning Optimizer)
v$sql, v$sql_plan_statistics,v$sql_plan_statistics_all,v$sql_workarea 등
sql별 저장된 런타임 수행 통계 등으로 앞으로 옵티마이저의 발전 방향 예상
스스로 학습하는 옵티마이저'를 9i, 10g에서 선보이는 듯하였으며 11g부터 본격화 하는듯
대표적 예, 적응적 커서 공유 (Adaptive Cursor Sharing) 기법, 동적 실시간 최적화 (Dynamic Runtime Optimizations)개념
(4) 옵티마이저 모드
RULE, ALL_ROWS, FIRST_ROWS, FIRST_ROWS_N, CHOOSE
- 시스템, 세션, 쿼리 레벨에서 변경 가능
alter system set optimizer_mode = all_rows; -- 시스템 레벨변경
alter session set optimizer_mode = all_rows; -- 세션 레벨 변경
select /*+ all_rows */ * from t where … ; -- 쿼리 레벨 변경
- RULE
☞ RBO 모드 선택 시, 사용
- ALL_ROWS
☞ 쿼리 최종 결과 집합을 끝까지 Fetch 전제로 시스템 리소스를 가장 적게 사용하는 실행계획 선택
- DML 문장 : 모두 All_rows 모드
- Select 문장 : union, minus 등 집합 연산자나 for Update절 사용 시 All_rows 모드
- PL/SQL : 힌트 사용, RBO 모드를 제외하면 항상 All_rows 모드
- FIRST_ROWS
☞ 전체 결과집합 중 일부 로우만 Fetch하다가 멈추는 것을 전제로, 가장 빠른 응답 속도를 낼 수 있는 실행계획 선택
(단, 끝까지 Fetch 시, 더 많은 리소스 사용으로 전체 수행속도가 느려질 수 있음)
비용과 규칙을 혼합한 형태의 옵티마이저 모드 (∵ 통계정보를 활용하여 RBO 규칙 적용)
- FIRST_ROWS_N
☞ 처음 n개 로우만 Fetch 하는 것을 전제로, 가장 빠른 응답 속도를 낼 수 있는 실행계획 선택
설정 시, 가능한 n 값 : 1, 10, 100, 1000 4가지
단, 힌트 사용 시 0 이상의 어떤 정수도 가능
alter session set optimizer_mode=first_rows_100;
select /*+ first_rows(n) */ * from t where …;
- CHOOSE
- 엑세스 테이블 중 적어도 하나의 통계정보가 있다면 CBO All_rows 모드 선택, 없을 시 RBO 선택
- 9i 까지 Choos가 기본 설정
- 10g 이후 All_rows 모드가 기본 설정 (∵ RBO 지원이 없어지고, 통계정보가 없을 시 무조건 동적 샘플링 발생)
- 옵티마이저 모드 선택
- 일반적으로 OLTP 환경에서는 first_rows, DW나 배치 프로그램 등에서는 all_rows 옵티마이저 모드를 사용하는 것이라 알려짐
- 웹 애플리케이션 환경에서는 OLTP도 all_rows가 올바른 선택 (∵ 애플리케이션서 수행되는 쿼리 자체가 전체범위처리 요함)
- 애플리케이션 특성을 고려하여 모드를 선택해야 함
- Tip 어떤 모드를 사용할 지 명확하지 않을 경우, all_rows를 기본모드로 선택하고 필요 쿼리 또는 세션레벨에서 first_rows 모드로 전환하는 방법을 권고
- 오라클 고도화 원리와 해법 2 (bysql.net 2011년 1차 스터디)
- 작성자: 위충환 (실천하자)
- 최초작성일: 2011년 04월 17일
- 본문서는 bysql.net 스터디 결과입니다 .본 문서를 인용하실때는 출처를 밝혀주세요. http://www.bysql.net
- 문서의 잘못된 점이나 질문사항은 본 문서에 댓글로 남겨주세요. ^^
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 60 |
Front Page
| 운영자 | 2011.02.15 | 149752 |
| 59 | 3. 인덱스 파티셔닝 | darkbeom | 2011.06.19 | 54502 |
| 58 |
3. 다양한 인덱스 스캔 방식
| 멋진넘 | 2011.02.18 | 34176 |
| 57 | 8. 통계정보 Ⅱ [1] | 멋진넘 | 2011.04.29 | 32789 |
| 56 | 2. 파티션 Pruning | 실천하자 | 2011.06.21 | 26412 |
| 55 | 3. 뷰 Merging | 실천하자 | 2011.05.15 | 23806 |
| 54 |
3. 해시 조인
| darkbeom | 2011.03.20 | 21904 |
| 53 | 2. 서브쿼리 Unnesting | darkbeom | 2011.05.15 | 20162 |
| 52 | 4. 통계정보 Ⅰ | darkbeom | 2011.04.25 | 18494 |
| 51 | 7. 인덱스 스캔 효율 [1] | 휘휘 | 2011.03.08 | 17352 |
| 50 | 7. Sort Area 크기 조정 | 실천하자 | 2011.06.13 | 15540 |
| 49 |
4. 테이블 Random 액세스 부하
[1] | darkbeom | 2011.02.23 | 15053 |
| 48 | 4. 조인 순서의 중요성 | 운영자 | 2011.03.27 | 14681 |
| 47 |
1. 인덱스 구조
[1] | 실천하자 | 2011.02.16 | 14579 |
| 46 | 1. 기본 개념 | 멋진넘 | 2011.06.28 | 13817 |
| 45 |
8. 고급 조인 테크닉-1
[1] | darkbeom | 2011.04.03 | 13629 |
| 44 |
9. 비트맵 인덱스
| 실천하자 | 2011.03.05 | 12685 |
| » |
1. 옵티마이저
| 실천하자 | 2011.04.17 | 11582 |
| 42 | 6. 히스토그램 | 실천하자 | 2011.04.24 | 11319 |
| 41 | 7. OR-Expansion | 멋진넘 | 2011.05.31 | 9916 |