8. 고급 조인 테크닉-2
2011.04.05 18:58
(8) 선분이력 조인
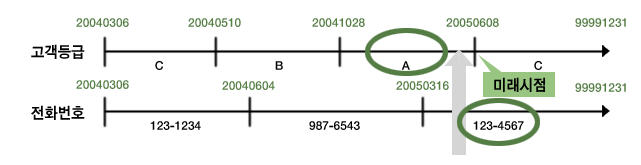
현재 시점 조회 (선분이력 조건이 상수)
▶ 미래 시점 데이터를 미리 입력하는 기능 없음
|
‘=’ 조건으로 만들어 주는 것이 효과적 |
SELECT c.고객번호, c.고객명, c1.고객등급, c2.전화번호
FROM 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2
WHERE c.고객번호 = 123
AND c1.고객번호 = c고객번호
AND c2.고객번호 = c고객번호
AND c1.종료일자 = ‘99991231’
AND c2.종료일자 = ‘99991231’
▶ 데이터를 미리 입력해 두는 기능이 있음
|
sysdate 와 between 사용 |
SELECT c.고객번호, c.고객명, c1.고객등급, c2.전화번호
FROM 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2
WHERE c.고객번호 = 123
AND c1.고객번호 = c고객번호
AND c2.고객번호 = c고객번호
AND TO_CHAR(sysdate, ‘yyyymmdd’) BETWEEN c1.시작일자 AND c1.종료일자
AND TO_CHAR(sysdate, ‘yyyymmdd’) BETWEEN c2.시작일자 AND c2.종료일자
|
|
Between 조인 (미지의 거래일자 시점으로 조회)
SELECT a.거래일자, a.종목코드, b.종목한글명, b.종목영문명, b.상장주식주,
a.시가, a.종가, a.체결건수, a.체결수량, a.거래대금
FROM 일별종목거래및시세 a, 종목이력 b
WHERE a.거래일자 BETWEEN TO_CHAR(ADD_MONTHS(SYSDATE, -20*12), ‘yyyymmdd’) AND TO_CHAR(SYSDATE-1, ‘yyyymmdd’)
AND a.종가 = a.최고가
AND b.종목코드 = a.종목코드
AND a.거래일자 BETWEEN b.시작일자 AND b.종료일자
- 현재(=최종) 시점의 종목명을 가져오는 것이 아니라 거래가 일어난 바로 그 시점의 종목명을 읽음
- 현재(=최종) 시점에서 출력하려면 between 조인 대신 상수 조건으로 입력
(9) 선분이력 조인 튜닝
|
조인 유형 |
데이터 상황 |
튜닝 방안 |
|
정해진 시점으로 선분이력과 단순 조인 |
①조회 대상이 많지 않을 때 |
인덱스 순서 조정 |
|
②조회 대상이 많을 때 |
해시 조인 (대상별 이력 레코드가 많더라도 Full Scan 하는 비용만 커질 뿐 조인 과정에서의 탐색 비효율 없음) | |
|
Between 조인 |
③조회 대상이 많지 않을 때 |
스칼라 서브쿼리 등에 Stopkey조건을 사용해 인덱스 한 건만 스캔하도록 구현 |
|
④조회 대상이 많지만 대상별 이력 레코드가 많지 않을 때 |
해시 조인 (대상별 이력 레코드가 많지 않아 해시 테이블 탐색 비용이 크지 않음) | |
|
⑤대상별 이력 레코드가 많을 때 |
? (대상별 이력 레코드가 많아 해시 테이블 탐색 비용이 매우 큼) |
정해진 시점을 기준으로 선분이력과 단순 조인할 때
① 조회 대상이 많지 않을 때
‘C70’회사를 통해 가입한 고객만 조회
SELECT /*+ ORDERED USE_NL(b) */ a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
FROM 고객 a, 고객별연체이력 b
WHERE a.가입회사 = ‘C70’
AND b.고객번호 = a.고객번호
AND ‘20050131’ BETWEEN b.시작일 AND b.종료일
> 고객별연체이력_idx01 : 고객번호 + 종료일 + 시작일
> SELECT MIN(시작일) MN_시작일, MAX(시작일) MX_시작일 FROM 고객별연체이력;
MN_시작일 MX_시작일
-------- ---------
20050103 25520801
Rows Row Source Operation
------------------------------------------------------------------------------------------
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=4636 pr=4621 pw=0 time=36078 us)
21 NESTED LOOPS (cr=4634 pr=4620 pw=0 time=717946 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=1 pw=0 time=15870 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=61 us)(object id 50402)
10 INDEX RANGE SCAN 고객별연체이력_IDX01 (cr=4630 pr=4619 pw=0 time=55057 us
- 고객마다 종료일이 20050131(시작일의 최소값)보다 크거나 같은 이력을 모두 스캔하여 4630개 블록I/O 발생
튜닝 : 인덱스 순서 조정
create index 고객별연체이력_idx01 on 고객별연체이력(고객번호, 시작일, 종료일);
Rows Row Source Operation
------------------------------------------------------------------------------------------
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=30 pr=23 pw=0 time=32866 us)
21 NESTED LOOPS (cr=28 pr=22 pw=0 time=653626 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=1 pw=0 time=12574 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=44 us)(object id 50402)
10 INDEX RANGE SCAN 고객별연체이력_IDX01 (cr=24 pr=21 pw=0 time=117797 us)
- 시작일이 20050131보다 작거나 같은 이력은 소량이므로 인덱스 스캔량이 줄게 됨.
② 조회 대상이 많을 때
전체 고객을 조회
튜닝 : Random 액세스 위주의 NL조인보다 해시 조인
Between 조인 튜닝 (미지의 거래일자 시점으로 조회)
③ Between 조인 튜닝 ? 조회 대상이 많지 않을 때
‘C70’회사를 통해 가입한 고객만 조회
|
SELECT /*+ ORDERED USE_NL(b) */ a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액 FROM 고객 a, 고객별연체이력 b WHERE a.가입회사 = ‘C70’ AND b.고객번호 = a.고객번호 AND a.서비스만료일 BETWEEN b.시작일 AND b.종료일 Rows Row Source Operation ------- --------------------------------------------------- 10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=2571 pr=2542 pw=0 time=36478 us) 21 NESTED LOOPS (cr=2561 pr=2533 pw=0 time=729065 us) 10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=50 us) 10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=28 us)(object id 50402) 10 INDEX RANGE SCAN 고객별연체이력_IDX01 (cr=2557 pr=2533 pw=0 time=740663 us) > 인덱스 : 고객번호 + 시작일 + 종료일 - 고객에서 읽힌 값이 최대만료일일 경우 처음부터 끝까지 스캔, 최소만료일일 경우는 스캔량 많지 않음. - 인덱스를 조정해도 나아질 것 없음 튜닝 : 스칼라 서브쿼리나 중첩된 서브쿼리 형태로 바꿔 각 고객별로 단 하나의 이력만 읽도록 ROWNUM <= 1조건 추가 SELECT a.고객명, a.거주지역, a.주소, a.연락처, (SELECT /*+ INDEX_DESC(b 고객별연체이력_IDX01) */ 연체금액 FROM 고객별연체이력 b WHERE b.고객번호 = a.고객번호 AND a.서비스만료일 BETWEEN 시작일 AND 종료일 AND ROWNUM <= 1) 연체금액 FROM 고객 a WHERE a.가입회사 = ‘C70’ Rows Row Source Operation ------- --------------------------------------------------- 10 COUNT STOPKEY (cr=40 pr=14 pw=0 time=99469 us) 10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=40 pr=14 pw=0 time=99414 us) 10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=8 pw=0 time=60446 us) 10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=26 us) 10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=52 us) |
< 연체금액, 연체개월수 두 컬럼 >
(방법1) 컬럼들을 문자열로 연결하고서 바깥 쪽 액세스 쿼리에서 SUBSTR 함수로 자른다.
(방법2) 스칼라 서브쿼리에서 ROWID만 취하고 고객별연체이력을 한번 더 조인
방법2.
▶ 스칼라 서브쿼리
SELECT /*+ ORDERED USE_NL(b) ROWID(b) */ a.*, b.연체금액, b.연체개월수
FROM (SELECT a.고객명, a.거주지역, a.주소, a.연락처,
(SELECT /*+ INDEX_DESC(b 고객별연체이력_IDX01) */ ROWID
FROM 고객별연체이력 b
WHERE b.고객번호 = a.고객번호
AND a.서비스만료일 BETWEEN 시작일 AND 종료일
AND ROWNUM <= 1) RID
FROM 고객 a
WHERE a.가입회사 = ‘C70’) a, 고객벽연체이력 b
WHERE b.ROWID = a.RID
Rows Row Source Operation
------- ---------------------------------------------------
10 COUNT STOPKEY (cr=30 pr=0 pw=0 time=114 us)
10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=0 pw=0 time=84 us)
10 NESTED LOOPS (cr=44 pr=0 pw=0 time=78 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=91 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=62 us)(object id 50402)
10 TABLE ACCESS BY USER ROWID 고객별연체이력 (cr=40 pr=0 pw=0 time=190 us)
▶ 일반 서브쿼리의 ROWID로 테이블 직접 액세스
SELECT /*+ ORDERED USE_NL(b) ROWID(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
FROM 고객 a, 고객별연체이력 b
WHERE a.가입회사 = ‘C70’
AND b.ROWID = (SELECT /*+ INDEX_DESC(c 고객별연체이력_IDX01) */ ROWID
FROM 고객별연체이력 c
WHERE c.고객번호 = c.고객번호
AND a.서비스만료일 BETWEEN 시작일 AND 종료일
AND ROWNUM <= 1)
Row Row Source Operation
----------------------------------------------------------------------------------
10 NESTED LOOPS (cr=44 pr=0 pw=0)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0)
10 TABLE ACCESS BY USER ROWID 고객별연체이력 (cr=40 pr=0 pw=0)
10 COUNT STOPKEY (cr=30 pr=0 pw=0)
10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=0 pw=
④ Between 조인 튜닝 ? 조회 대상이 많지만 대상별 이력 레코드가 많지 않을 때
전체 고객을 조회
튜닝 : Random 액세스 위주의 NL조인보다 해시 조인
SELECT /*+ ORDERED USE_HASH(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
FROM 고객 a, 고객별연체이력 b
WHERE b.고객번호 = a.고객번호
AND a.서비스만료일 BETWEEN b.시작일 AND b.종료일
⑤ Between 조인 튜닝 ? 대상별 이력 레코드가 많을 때
▶ 대상별 이력 레코드가 많다면 해시 탐색 부하로 성능저하
▶ Build Input 해시 키 값에 중복이 많을 때 발생하는 비효율
------------------------------------------------------------------------------------------
1) 방안 1
두 개 이상 월에 걸치는 이력이 생기지 않도록 매월 말일 시점에 강제로 이력을 끊어 준다.
(해시 체인을 스캔하는 비효율을 완전히 없앨 수는 없지만 최대 31개가 넘지 않도록 제한하려는 것)
------------------------------------------------------------------------------------------
> 저자는 디스크I/O를 발생하지 않도록 한 상태에서 쿼리 테스트를 했는데, 실제 운영 환경에서 디스크 I/O까지 수반한 Random 액세스 방식으로 많은 블록(테스트 결과 : 146만개 블록)을 읽는 경우 대량의 데이터를 NL조인을 할 때는 비효율적임을 설명.
▶ 해시조인
select /*+ leading(a) use_hash(b) */
sum(b.거래수량) 총거래수량
, sum(b.거래수량 * a.판매가) 총판매금액
, round(avg(b.거래수량 * a.판매가)) 평균판매금액
from 상품이력2 a, 일별상품거래 b
where b.상품번호 = a.상품번호
and b.거래일자 between a.시작일자 and a.종료일자
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 1 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 52.953 52.976 0 1578 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 52.953 52.976 0 1578 0 1
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1578 pr=0 pw=0 time=52976159 us)
365300 HASH JOIN (cr=1578 pr=0 pw=2303 time=58163616 us)
100325 TABLE ACCESS FULL 상품이력 (cr=409 pr=0 pw=0 time=365351 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=0 pw=0 time=1095943 us)
- 인덱스 기반 between 조인할 때 보다 오래 걸림(상품별 이력 평균 913건) 즉, 해시 탐색 비용 높음
▶ 두 개 이상 월에 걸치는 이력 레코드가 없도록 상품이력2 테이블 생성 후, 해시조인
select /*+ leading(a) use_hash(b) */
sum(b.거래수량) 총거래수량
, sum(b.거래수량 * a.판매가) 총판매금액
, round(avg(b.거래수량 * a.판매가)) 평균판매금액
from 상품이력2 a, 일별상품거래 b
where b.상품번호 = a.상품번호
and b.거래일자 between a.시작일자 and a.종료일자
and trunc(to_date(b.거래일자, 'yyyymmdd'), 'mm') = trunc(to_date(a.시작일자, 'yyyymmdd'), 'mm')
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 1 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 1.81 2.49 3668 1617 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 1.81 2.49 3668 1618 0 1
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1617 pr=3668 pw=2303 time=2494976 us)
365300 HASH JOIN (cr=1617 pr=3668 pw=2303 time=1843577 us)
100325 TABLE ACCESS FULL 상품이력2 (cr=448 pr=201 pw=0 time=14668 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=1164 pw=0 time=1837976 us)
- 선분 형태의 이력이지만 한 달 범위를 넘지 않도록 했기에 ‘=’ 조인문을 더 추가
------------------------------------------------------------------------------------------
2) 방안 2
두 개 이상 월에 걸치는 이력이 없도록 쿼리 시점에 선분이력을 변환해 주는 것.
------------------------------------------------------------------------------------------
select /*+ ordered use_merge(b) use_hash(c) */
sum(c.거래수량) 총거래수량
, sum(c.거래수량 * b.판매가) 총판매금액
, round(avg(c.거래수량 * b.판매가)) 평균판매금액
from 월도 a, 상품이력 b, 일별상품거래 c
where b.시작일자 <= a.종료일자
and b.종료일자 >= a.시작일자
and c.상품번호 = b.상품번호
and c.거래일자 between b.시작일자 and b.종료일자
and a.기준월 || ‘01’ = trunc(to_date(c.거래일자, 'yyyymmdd'), 'mm')
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 1 0 0
Execute 2 0.00 0.00 0 0 0 0
Fetch 2 4.26 5.87 38005 1581 11 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 5 4.26 5.87 38005 1582 11 1
Rows Row Source Operation
------- ---------------------------------------------------
1 SORT AGGREGATE (cr=1581 pr=38005 pw=3636 time=5871283 us)
365300 HASH JOIN (cr=1581 pr=38005 pw=3636 time=4991715 us)
100325 MERGE JOIN (cr=412 pr=34293 pw=1088 time=6098194 us)
241 SORT JOIN (cr=3 pr=0 pw=0 time=376 us)
241 TABLE ACCESS FULL 월도 (cr=3 pr=0 pw=0 time=267 us)
100325 FILTER (cr=409 pr=34293 pw=1088 time=489506 us)
5610425 SORT JOIN (cr=409 pr=34293 pw=1088 time=345876 us)
91325 TABLE ACCESS FULL 상품이력 (cr=409 pr=133 pw=0 time=14 us)
365300 TABLE ACCESS FULL 일별상품거래 (cr=1169 pr=1164 pw=0 time=387425 us)
- 상품이력2를 이용할 때보다는 느리지만 그냥 해시 조인할 때보다 빨라짐.
- 일별상품거래와 조인 시 빠르지만, 월도와 조인 시 오히려 병목 생길 수 있음
Between 조인 튜닝 요약
* 대상별 이력 레코드가 많을 때의 between 조인은 좋은 성능을 내기 쉽지 않음.
→ 월말 시점마다 선분을 끊어주는 것을 고려
* 마스터 데이터 건수가 적으면서 변경이 잦은 경우
→ 매일 전체 대상 집합을 새로 저장하는 이력관리방식(스냅샷 형태)도 고려
(10) 조인에 실패한 레코드 읽기
select 국가코드, '''' || 지역 || '''', 요금 from cdr_rating ;
국 ''''||지역|| 요금
-- ------------ ----------
82 'A' 100
82 'B' 200
82 'C' 500
82 'D' 300
82 'E' 100
84 'A' 300
84 'B' 500
84 'C' 400
84 ' ' 800
86 'A' 500
86 'B' 200
86 ' ' 700
select * from cdr;
통화시간 국 지역
--------------- -- ---------
20050315 010101 82 A
20050315 020101 82 B
20050315 030101 82 C
20050315 040101 84 A
20050315 050101 84 B
20050315 060101 84 C
20050315 070101 84 D
20050315 080101 84 E
20050315 090101 86 A
20050315 100101 86 B
20050315 110101 86 C
20050315 120101 86 D
20050315 130101 86 E
20050315 140101 86 F
select /*+ ordered use_nl(r) */
c.통화시간, c.국가코드, c.지역, r.요금
from cdr c, cdr_rating r
where c.통화시간 like '20050315%'
and c.국가코드 = r.국가코드(+)
and c.지역 = r.지역(+) ;
통화시간 국 지역 요금
--------------- -- ---------- ----------
20050315 010101 82 A 100
20050315 020101 82 B 200
20050315 030101 82 C 500
20050315 040101 84 A 300
20050315 050101 84 B 500
20050315 060101 84 C 400
20050315 070101 84 D
20050315 080101 84 E
20050315 090101 86 A 500
20050315 100101 86 B 200
20050315 110101 86 C
20050315 120101 86 D
20050315 130101 86 E
20050315 140101 86 F
select /*+ ordered use_nl(r) */
c.통화시간, c.국가코드, c.지역, r.요금
from cdr c, cdr_rating r
where c.통화시간 like '20050315%'
and (r.국가코드, r.지역) =
(select c.국가코드, max(지역)
from cdr_rating
where 국가코드 = c.국가코드
and 지역 in (' ', c.지역) ) ;
통화시간 국 지역 요금
--------------- -- ---------- ----------
20050315 010101 82 A 100
20050315 020101 82 B 200
20050315 030101 82 C 500
20050315 040101 84 A 300
20050315 050101 84 B 500
20050315 060101 84 C 400
20050315 070101 84 D 800
20050315 080101 84 E 800
20050315 090101 86 A 500
20050315 100101 86 B 200
20050315 110101 86 C 700
20050315 120101 86 D 700
20050315 130101 86 E 700
20050315 140101 86 F 700
> 9i 까지는 use_concat 힌트 사용(IN-List가 concatenation(or-expansion)방식으로 풀리면 뒤쪽에 있는 값이 먼저 실행되는 특징 이용)
> 10g부터는 use_concat 힌트로는 or-expansion가 일어나지 않기 때문에 9i때처럼 쓸 수 없다.
따라서 ordered_predicates 힌트를 사용하거나 no_cpu_costing 힌트를 이용해 I/0 비용 모델로 바꿔줘야 한다.
오라클 고도화 원리와 해법 2 (bysql.net 2011년 1차 스터디)
작성자: 이주영 (suspace)
최초작성일: 2011년 4월 3일
본문서는 bysql.net 스터디 결과입니다 .본 문서를 인용하실때는 출처를 밝혀주세요. http://www.bysql.net
문서의 잘못된 점이나 질문사항은 본문서에 댓글로 남겨주세요. ^^
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| » |
8. 고급 조인 테크닉-2
| suspace | 2011.04.05 | 7017 |
| 39 | 2. 옵티마이저 행동에 영향을 미치는 요소 | 휘휘 | 2011.04.18 | 5094 |
| 38 |
1. 옵티마이저
| 실천하자 | 2011.04.18 | 11211 |
| 37 | 3. 옵티마이저의 한계 | 멋진넘 | 2011.04.19 | 7857 |
| 36 | 6. 히스토그램 | 실천하자 | 2011.04.25 | 10917 |
| 35 | 4. 통계정보 Ⅰ | darkbeom | 2011.04.26 | 18091 |
| 34 | 5. 카디널리티 | suspace | 2011.04.26 | 5953 |
| 33 | 8. 통계정보 Ⅱ [1] | 멋진넘 | 2011.04.30 | 31079 |
| 32 | 1. 쿼리 변환이란? | 실천하자 | 2011.05.02 | 4927 |
| 31 | 7. 비용 | 휘휘 | 2011.05.03 | 6167 |
| 30 | 3. 뷰 Merging | 실천하자 | 2011.05.15 | 23381 |
| 29 | 2. 서브쿼리 Unnesting | darkbeom | 2011.05.16 | 19700 |
| 28 | 5. 조건절 이행 | 휘휘 | 2011.05.30 | 5406 |
| 27 | 6. 조인 제거 | 멋진넘 | 2011.05.30 | 4595 |
| 26 | 7. OR-Expansion | 멋진넘 | 2011.05.31 | 8720 |
| 25 | 4. 조건절 Pushing | 실천하자 | 2011.05.31 | 7021 |
| 24 | 12. 기타 쿼리 변환 [3] | 실천하자 | 2011.06.03 | 6646 |
| 23 | 8. 공통 표현식 제거 | darkbeom | 2011.06.07 | 5223 |
| 22 | 9. Outer 조인을 Inner 조인으로 변환 | darkbeom | 2011.06.07 | 7834 |
| 21 | 10. 실체화 뷰 쿼리로 재작성 | suspace | 2011.06.07 | 5531 |