1. 인덱스 구조
2011.03.30 01:54
(1) 범위 스캔
- 인덱스: 대용량 테이블에서 필요한 데이타를 빠르고 효율적으로 액세스 하기 위해 사용하는 오브젝트
- 범위스캔: 특정 위치에서 스캔을 시작해 조건에 일치하지 않는 값을 만나는 순간 멈추어 자료를 찾는 형태
- 일반적인 힙구조 테이블 (heap-organized table)에서 범위스캔을 할수는 없음 (IOT 는 제외)
(2) 인덱스 기본 구조
- B* Tree 인덱스 구조
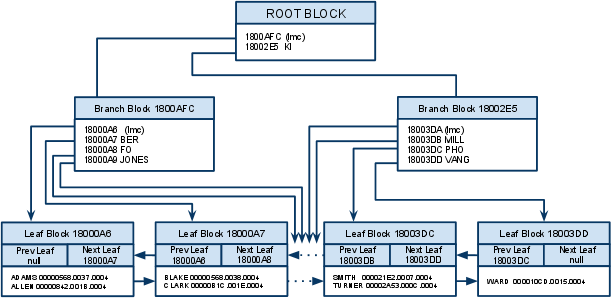
Root와 Branch Block는 하위 노드 블록을 찾아가기 위한 DBA정보를 갖고
최말단의 Leaf 블록은 인덱스 키 컬럼과 함께 해당 테이블 레코드를 찾아가기 위한 주소정보 rowid 를 가진다.
리프블록은 항상 키 컬럼순서로 정렬되어있어 범위스캔이 가능하게된다. (키값이 같을경우 rowid순)
※ LeftMost Child
브랜치 노드는 키 값과 하위노드를 지시하는 주소값을 가지는 엔트리와 함께 특별한 키값을 가지지 않은 엔트리가 있다.
그 엔트리를 lmc 라 하며 노드의 첫번째 값으로 ‘키값을 가진 첫번째 앤트리 보다 작은 값’ 이라는 의미를 가지어 그 브랜치 블록의 자식 노드 중 가장 왼쪽 끝에 위치한 블록을 가리킨다.
- 특징
- 오라클의 경우 구성 컬럼이 모두 null인 레코드의 경우 인덱스에 저장하지 않으며 인덱스와 테이블 레코드 간에는
서로 1:1 대응 관계를 갖는다. (클러스터 인덱스는 1:M의 관계를 가짐) - 브런치에 저장된 레코드 개수는 하위 레벨 블륵개수와 일치한다.
- 리프노드의 값은 테이블 레코드의 값이 갱신되면 키 값역시 같이 갱신(delete & insert) 된다.
- 브랜치 블록에 놓인 엔트리는 자신의 키값과 같거나 큰 값을 가진 하위 노드의 범위를 나타내기 때문에
엔트리 값의 갱신에 영향을 받지 않으며 하위노드의 첫번째 값과 반드시 일치하지는 않는다.
(브랜치 노드는 인덱스 분할에 의해 새로운 블록이 추가되거나 삭제 될때만 갱신된다.)
(3) 인덱스 탐색
- 수평적 탐색
- 범위 스캔- 리프 블록을 인덱스 레코드 간 논리적 순서에 따라 좌나 우로 스캔하기때문에 수평적 이라고 표현한다.
- 수직적 탐색
- 수평적 탐색을 위한 시작 지점을 찾는 과정 (루트에서 리프 블록까지 아래로 진행)
ex) 그림에서 CLARK 를 찾는 과정
1. 루트 블록에서 CLARK 값을 lmc (KI보다 작은값) 와 KI (KI보다 크거나 같은값) 를 비교하여 왼쪽으로 이동한다(C 는 K보다 작다)
2. 브랜치 블록을 스캔하면서 다음 익덱스 블록을 찾는다. ‘BER’보다 크고 ‘FO’보다 작으므로두번째 레코드 (18000A7) 로 찾아간다.
3. 도착한 리프 블록에서 ‘CLARK’ 를 찾으면 수평적 탐색으로 넘어가고 못찾으면 탐색을 중지한다.‘CLARK’를 찾았으므로 탐색(범위스캔)을 진행한다.
4. 리프블록들을 시캔하면서 CLARK와 같은 지 비교한다.
5. ‘CLARK’과 같으면 rowid(00000B1C.001E.0004)를 이용해 해당 테이블 레코들 찾아가 필요한 컬럼 값을 읽는다.
6. 4,5번 과정을 반복하다가 검색하는 조건을 만족하지 못하는 레코드를 만나면 점춘다.
- 브랜치 블록 스캔
- 브랜치 블록을 스캔할경우 뒤에서 스캔하는 방식이 유리하다.
- 앞
에서 탐색할경우 크거나 같은 첫번째 레코드를 만나면 바로 뒤쪽으로 이동한후 진행해야하지만
뒤쪽에서 스캔하는 경우 찾고자 하는 레코드보다 작은 레코드를 만나는 순간 바로 아래 블록으로 이동하면 된다.
(오라클의 방법은 미확인, 필자의 의견 이며 본서는 뒤쪽에서 부터 스캔한다고 가정) - 수직적 탐색을 진행할때는 찾고자 하는 값보다 키 값이 작은 엔트리를 따라 내려간다.
- 결합 인덱스 구조와 스캔
- 인덱스가 deptno + sal 이고 조건이 deptno=20 and sal >= 2000
일경우 수직적 탐색 과정에서 deptno를 먼저 찾고 진행하는것이 아니라 deptno와 함께 sal값에 대한 필터링이 같이 이루어 진후 탐색을 진행한다..
(4) ROWID 포맷
- rowid 는 데이터 파일 번호, 블록 번호, 로우 번호 같은 테이블 레코드의 물리적 위치 정보를 가지며 레코드를 찾아가는데 필요한 주소정보이며 index에서 저장된다.
- ‘제한 rowid 포맷’
- 오라클 7버젼 까지 사용
- 구성
- 데이터 파일 번호 (4자리) : row가 속한 데이터 파일번호, 데이터페이스 내의 유일한값
- 블록번호 (8자리) :데이터 파일내 상대적 위치
- 로우 번호 (4자리) :블록내의 일련번호
- 6 바이트 공간을 차지
- 파티션되지 않은 일반 테이블에 생성한 인덱스
- 파티션된 테이블에 생성한 로컬 파티션 (Local Partitioned) 인덱스
- ‘확장 rowid 포맷’
- 오라클 8버전 부터 사용
- 10 바이트, tera-byte에서 peta-byte 단위의 데이터까지 저장할수 있게됨
- 구성
- 데이터 오브젝트 번호 (6자리) : 데이터베이스 세그먼트를 식별하 기해 사용되는 오브젝트 번호
- 데이터 파일 번호 (3자리): 테이블 스페이스 내의 상대적인 파일번호
- 블록 번호(6자리): 해당 로우가 저장된 데이터 블록 번호(데이터 파일내의 상대적위치)
- 로우번호(3자리): 블록내의 일력번호
* ubuntu / oracle 10g XErowid 의 활용
SQL> conn scott/tiger
연결되었습니다.
SQL> select rowid, empno, ename from emp;
ROWID EMPNO ENAME
------------------ ---------- ----------
AAAEKaAAEAAAAG3AAA 7369 SMITH
AAAEKaAAEAAAAG3AAB 7499 ALLEN
AAAEKaAAEAAAAG3AAC 7521 WARD
AAAEKaAAEAAAAG3AAD 7566 JONES
AAAEKaAAEAAAAG3AAE 7654 MARTIN
AAAEKaAAEAAAAG3AAF 7698 BLAKE
AAAEKaAAEAAAAG3AAG 7782 CLARK
AAAEKaAAEAAAAG3AAH 7788 SCOTT
AAAEKaAAEAAAAG3AAI 7839 Kinng
AAAEKaAAEAAAAG3AAJ 7844 TURNER
AAAEKaAAEAAAAG3AAK 7876 KING
ROWID EMPNO ENAME
------------------ ---------- ----------
AAAEKaAAEAAAAG3AAL 7900 JAMES
AAAEKaAAEAAAAG3AAM 7902 FORD
AAAEKaAAEAAAAG3AAN 7934 MILLER
14 개의 행이 선택되었습니다.
- dbms_rowid 패키지를 사용하여 정보 확인
SQL> select rowid extended_format,
2 dbms_rowid.rowid_to_restricted(rowid,0) restricted_format,
3 dbms_rowid.rowid_object(rowid) object,
4 dbms_rowid.rowid_relative_fno(rowid) file_no,
5 dbms_rowid.rowid_block_number(rowid) block_no,
6 dbms_rowid.rowid_row_number(rowid) row_number
7 from emp e
8 where empno=7369;
EXTENDED_FORMAT RESTRICTED_FORMAT OBJECT FILE_NO BLOCK_NO ROW_NUMBER
------------------ ------------------ ---------- ---------- ---------- ----------
AAAEKaAAEAAAAG3AAA 000001B7.0000.0004 17050 4 439 0
- rowid의 타입 구분
SQL> select dbms_rowid.rowid_type('AAAEKaAAEAAAAG3AAA') extended_format,
2 dbms_rowid.rowid_type('000001B7.0000.0004') restricted_format
3 from dual;
EXTENDED_FORMAT RESTRICTED_FORMAT
--------------- -----------------
1 0
SQL>
- rowid 문자열 정보를 가지고 해당 오브젝트와 데이터 파일 정보 찾기
SQL> select object_id,owner,object_name,subobject_name
2 from dba_objects
3 where data_object_id=17050;
OBJECT_ID OWNER OBJECT_NAME SUBOBJECT_NAME
--------- ----------------- ---------------------- ------------------------------
17050 SCOTT EMP
SQL> select file_id,file_name, tablespace_name
2 from dba_data_files
3 where relative_fno=4;
FILE_ID FILE_NAME TABLESPACE_NAME
---------- -------------------------------------- ------------------------------
4 /usr/lib/oracle/xe/oradata/XE/users.dbf USERS
SQL>
- 오라클 고도화 원리와 해법 2 (bysql.net 2011년 1차 스터디)
- 작성자: 남송휘 (tofriend)
- 최초작성일: 2011년 2월 20일
- 본문서는 bysql.net 스터디 결과입니다 .본 문서를 인용하실때는 출처를 밝혀주세요. http://www.bysql.net
- 문서의 잘못된 점이나 질문사항은 본 문서에 댓글로 남겨주세요. ^^
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 55 |
Front Page
| 운영자 | 2011.02.16 | 114629 |
| 54 | 2. 인덱스 기본 원리 | balto | 2011.02.18 | 18844 |
| 53 | 1장. 인덱스 원리와 활용 | 휘휘 | 2011.02.21 | 6796 |
| 52 |
4. 테이블 Random 액세스 부하
| 휘휘 | 2011.02.26 | 6942 |
| 51 | 5. 테이블 Random 액세스 최소화 튜닝 | 휘휘 | 2011.02.26 | 9502 |
| 50 | 6. IOT, 클러스터 테이블 활용 | 오예스 | 2011.02.26 | 15597 |
| 49 |
7. 인덱스 스캔 효율
| 휘휘 | 2011.03.06 | 8449 |
| 48 | 9. 비트맵 인덱스 | 휘휘 | 2011.03.07 | 5014 |
| 47 | 8. 인덱스 설계 | AskZZang | 2011.03.09 | 5725 |
| 46 | 2. 소트 머지 조인 | 오예스 | 2011.03.21 | 7912 |
| 45 | 3. 해시 조인 | 휘휘 | 2011.03.21 | 6483 |
| 44 | 2장. 조인 원리와 활용 | 운영자 | 2011.03.23 | 3307 |
| 43 |
1. Nested Loops 조인
| 오라클잭 | 2011.03.23 | 23028 |
| 42 |
6. 스칼라 서브쿼리를 이용한 조인
| balto | 2011.03.27 | 18958 |
| 41 |
5. Outer 조인
| 휘휘 | 2011.03.28 | 17668 |
| » |
1. 인덱스 구조
| 운영자 | 2011.03.30 | 15951 |
| 39 | 4. 조인 순서의 중요성 | AskZZang | 2011.03.30 | 5328 |
| 38 | 7. 조인을 내포한 DML 튜닝 | 오예스 | 2011.04.04 | 9945 |
| 37 | 8. 고급 조인 테크닉-2 | 오라클잭 | 2011.04.05 | 12560 |
| 36 |
8. 고급 조인 테크닉-1
| 휘휘 | 2011.04.05 | 6459 |