1._블록_단위_IO
2012.05.22 19:18
1. 블록 단위로 I/O를 한다는 것은,
하나의 레코드에서 하나의 컬럼만을 읽으려 할때도 레코드가 속한 블록 전체를 읽게 됨을 의미

이러한 블록 단위 I/O 원리 때문에 위 쿼리를 처리할 때 서버에서 발생하는 I/O측면에서의 일량은 동일하다고 볼수 있음
컬럼 단위 I/O를 지원하는 DBMS의 경우 일부컬럼만 읽어 집계할 때 I/O측면에서 성능을 극대화
2. 엑세스하는 블록 개수
- SQL 성능 지표
- 옵티마이저의 판탄에 가장 큰 영향
3. 블록 단위 I/O 적용 : 버퍼 캐시와 데이터 파일 모두에 적용됨
- 메모리 버퍼 캐시에서 블록을 읽고 쓸 때
- 데이터파일에 저장된 데이터 블록을 직접 읽거나 쓸때 ( Direct Path I/O)
- 데이터 파일에서 DB 버퍼 캐시로 블록을 적재할 때
: Single Block Read 또는 Multiblock Read 방식 사용
- 버퍼 캐시에서 변경된 블록을 다시 데이터 파일에 저장할때
: Dirty 버퍼를 주기적으로 데이터파일에 기록하는 것을 말하며 DBWR 프로세스에 의해 수행됨
성능 향상을 위해 한 번에 여러 블록씩 처리
(참고)
오라클 딕셔너리 캐시는 로우단위로 I/O를 수행한다.
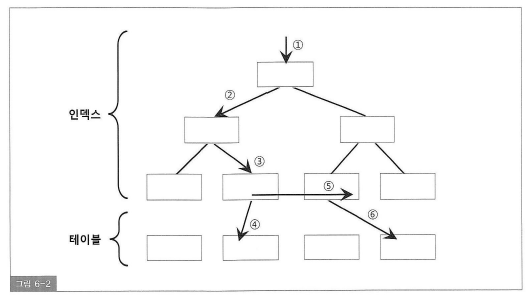
4. Sequential 엑세스
- 레코드간 논리적 또는 물리적인 순서를 따라 차례대로 읽어 나가는 방식
- 인덱스 리프 블록에 위치한 모든 레코드는 포인터를 따라 논리적으로 연결되어 있고 이 포인터를 따라 스캔하는 것(5번)
- 테이블의 경우 스캔할 때는 물리적으로 저장된 순서대로 읽어 나가는것
- Sequential 엑세스 성능을 향상시키는 방법
: 오라클 내부적으로 Multiblock I/O, 인덱스 Prefetch 같은 기능을 사용
5. Random 엑세스
- 한 건을 읽기 위해 한 블록씩 접근(1,2,3,4,6번)
- 4,6번의 엑세스가 성능 저하를 일으키며 NL조인에서 Inner 테이블 엑세스를 위해 사용되는 인덱스에서는 1,2,3번까지도
성능에 큰 영향을 미칠 수 있다.
- Random 엑세스 성능을 향상시키는 방법
: 오라클 내부적으로 버퍼 Pinning, 테이블 Prefetch 사용
6. 비효욜적이다?
- 한 번 엑세스할때 Sequential 방식으로 그안에 저장된 모든 레코드를 읽으면 비효율적인건 아님
- 다만 하나의 레코드를 읽으려고 한 블록씩 읽는다면 비효율적
- Sequential 방식으로 읽었을때 결과집합으로 선택되는 비중이 얼마나 되느냐가 중요 => 선택도(Selectivity)
- I/O튜닝의 핵심 원리 => 어떤 방식으로 엑세스든 비효율을 줄인다!!
(1) Sequential 엑세스의 선택도를 높인다
(2) Random 엑세스 발생량을 줄인다
7. Sequential 엑세스 선택도 높이기
- 샘플 테이블 생성
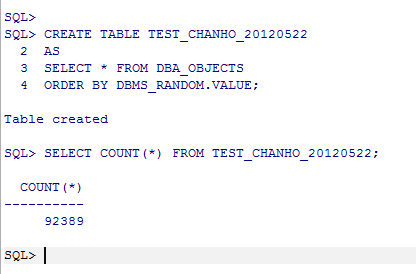
SQL> SELECT COUNT(*) FROM TEST_CHANHO_20120522
WHERE OWNER LIKE 'SYS%';
- 35364 레코드를 선택하려고 92389 레코드를 선택했다. (선택도 38.27%)

SQL> SELECT * FROM TEST_CHANHO_20120522
WHERE OWNER LIKE 'SYS%' AND OBJECT_NAME='ALL_OBJECTS';
- 1개 레코드를 선택하려고 TABLE ACCESS FULL을 하다니 상당히 비효율적이다.

- 이런 경우 인덱스를 사용하는것이 매우 효과적이다.
SQL> CREATE INDEX INDEX_TEST_CHANHO_20120522 ON TEST_CHANHO_20120522 (OWNER,OBJECT_NAME);
SQL> SELECT /*+ INDEX( TEST_CHANHO_20120522 INDEX_TEST_CHANHO_20120522) */ COUNT(*) FROM TEST_CHANHO_20120522 WHERE OWNER LIKE 'SYS%' AND OBJECT_NAME='ALL_OBJECTS';

- Bytes수와 Cost를 전의 쿼리와 비교해보았을때 보다 효과적인 것을 볼수 있다.
- 인덱스는 테이블과 달리 정렬된 순서를 유지하므로 일정 범위를 읽다가 멈출수 있다는 점만 다르지 테이블과 마찬가지로
인덱스 또한 Sequential 엑세스 방식으로 스캔하면 비효율이 존재한다.
- 인덱스 스캔의 효율은 조건절에 사용된 컬럼과 연산자 형태, 인덱스 구성에 영향을 받는다.
SQL> drop index INDEX_TEST_CHANHO_20120522;
SQL> CREATE INDEX INDEX_TEST_CHANHO_20120522 ON TEST_CHANHO_20120522(OBJECT_NAME, OWNER);
SQL> SELECT /*+ INDEX( TEST_CHANHO_20120522 INDEX_TEST_CHANHO_20120522) */ COUNT(*) FROM TEST_CHANHO_20120522 WHERE OWNER LIKE 'SYS%' AND OBJECT_NAME='ALL_OBJECTS';

- 인덱스 컬럼 순서를 바꾸니 선택도가 높아진 것을 확인할 수 있다.
8. Random 엑세스 발생량 줄이기
- 인덱스에 속하지 않는 컬럼을 참조하도록 쿼리를 변경해본다.
SQL> CREATE INDEX INDEX_TEST_CHANHO_20120522 ON TEST_CHANHO_20120522(OWNER);
SQL> SELECT /*+ INDEX( TEST_CHANHO_20120522 INDEX_TEST_CHANHO_20120522) */ OBJECT_ID FROM TEST_CHANHO_20120522 WHERE OWNER='SYS' AND OBJECT_NAME='ALL_OBJECTS';

- 내부적으로 블록을 34774번 방문했으나 3626(=3707-81)개 블록을 Random 엑세스했다. 이것은 버퍼 Pinning 효과 때문이다. 클러스터링 팩터가 좋을수록 버퍼 Pinning에 의한 블록 I/O감소 효과는 더 커진다.
- 위의 상황상 최종 한건을 선택하기 위해 너무 많은 Random 엑세스가 발생했다.
SQL> CREATE INDEX INDEX_TEST_CHANHO_20120522 ON TEST_CHANHO_20120522(OWNER, object_name);

- 인덱스로부터 1건을 출력했으므로 테이블을 1번 방문한다. 이렇듯 인덱스 구성이 바뀌자 테이블 Random 엑세스가 대폭 감소한 것이다.
감사합니다.^^
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 66 | 부록 | 남송휘 | 2012.06.06 | 2425 |
| 65 | 8._IO_효율화_원리 | 운영자 | 2012.06.06 | 4115 |
| 64 |
3._Deterministic_함수_사용_시_주의사항
| 정찬호 | 2012.05.29 | 4084 |
| 63 | 2._Cursor_Sharing | 운영자 | 2012.05.28 | 5988 |
| 62 | 7._Result_캐시 | 운영자 | 2012.05.27 | 4155 |
| 61 |
3._Single_Block_vs._Multiblock_IO
| 정찬호 | 2012.05.23 | 3958 |
| 60 |
2._Memory_vs._Disk_IO
| 정찬호 | 2012.05.23 | 4164 |
| » |
1._블록_단위_IO
| 정찬호 | 2012.05.22 | 3922 |
| 58 |
6장._IO_효율화_원리
| 정찬호 | 2012.05.22 | 3805 |
| 57 |
1._Library_Cache_Lock_Pin
| 남송휘 | 2012.05.21 | 3961 |
| 56 |
6._RAC_캐시_퓨전
| 남송휘 | 2012.05.21 | 17524 |
| 55 | 5._Direct_Path_IO | 남송휘 | 2012.05.21 | 7533 |
| 54 |
4._Prefetch
| 남송휘 | 2012.05.21 | 3593 |
| 53 | 8._PLSQL_함수_호출_부하_해소_방안 | 남송휘 | 2012.05.21 | 3445 |
| 52 | 5._Fetch_Call_최소화 [1] | 박영창 | 2012.05.15 | 4806 |
| 51 |
7._PLSQL_함수의_특징과_성능_부하
| 남송휘 | 2012.05.15 | 6636 |
| 50 | 6._페이지_처리의_중요성 | 남송휘 | 2012.05.15 | 3117 |
| 49 | 4._Array_Processing_활용 | 시와처 | 2012.05.14 | 3764 |
| 48 |
3._데이터베이스_Call이_성능에_미치는_영향
| 시와처 | 2012.05.13 | 3380 |
| 47 |
10._Dynamic_SQL_사용_기준
| 남송휘 | 2012.05.07 | 4275 |