10._Dynamic_SQL_사용_기준
2012.05.07 21:52
(1) Dynamic SQL 사용에 관한 기본 원칙
- Static SQL 을 지원하는 개발환경이라면 Static SQL로 작성하는것이 원칙
- Dynamic SQL 을 사용해도 무방한 경우
- PreCompile 과정에서 컴파일 에러가 나는 구문 ( Pro*C 에서 스칼라서브쿼리,분석함수등)
- 상황과 조건에 따라 생성되는 SQL최대 개수가 많아 유지보수 비용이 커질때
- 조건절에 바인드 변수 사용 원칙, 사용빈도 가 높고, 조건절 컬럼의 값 종류가 많을때
- 3번조건의 예외
- 배치 프로그램이나 DW,OLAP 등 정보계 시스템에사용되는 Long Running 쿼리
(파싱시간이 쿼리 총소요시간에 차지하는 비중이 매우 낮을때) - OLTP 성 이라도 사용빈도가 낮아 하드파싱에 의한 라이브러리 캐시 부하 유발 가능성이 없을때
- 조건절 컬럼의 값 종류 (distinct value)가 소수일때, 값 분포가 균일하지 않아
옵티마이져가 컬럼 히스토그램 정보를 활용하도록 유도 할때
- Static SQL을 지원하지 않는 개발환경에서의 static 과 dynamic sql 재정의 (편의상)
- Static SQL
- SQL Repository 에 완성된 형태로 저장된 SQL
- Dynamic SQL
- SQL Repository 에 불완전한 형태로 저장후 런타임시 상황과 조건에 따라
동적으로 생성되도록 작성한 SQL
(2) 기본 원칙이 잘 지켜지지 않는 첫번 째 이유, 선택적 검색 조건
- 대용량 테이블을 검색하는 애플리케이션에서 기간, 필수 검색조건없이 조회가능하도록 만든경우 성능 이슈 발생
-> 설계 단계에서 성능을 고려한 업무 요건 도출 필요 - 기간 검색만 필수이고 나머지는 선택일 경우
ex)
select 거래일자, 종목코드, 투자자유형코드, 주문매체 코드
, 체결건수, 체결수량, 거래대금
from 일별종목거래
where 거래일자 between :시작일자 and :종료일자
%option
%option = “ and 종목코드 = ‘KR123456’ and 투자자유형코드 = ‘1000’ “
개선
select 거래일자, 종목코드, 투자자유형코드, 주문매체 코드
, 체결건수, 체결수량, 거래대금
from 일별종목거래
where 거래일자 between :시작일자 and :종료일자
and 종목코드 = nvl (:종목코드,종목코드)
and 투자자유형코드 = nvl(:투자자유형코드, 투자자유형코드)
and 주문매체구분코드 = nvl(:주문매체구분코드, 주문매체구분코드)
- 사용자가 어떻게 값을 입력하더라도 한개의 실행 계획 공유
- so) 라이브러리 캐시 효율 최상
- but) 인덱스 사용에 문제 발생 (사용못하거나 사용하더라도 비효율적일수 있음)
- 라이브러리 캐시 효율과 i/o 효율 모두 고려한다면 각 조건별 입력에 따라 sql을 모두 분리
- 3가지 선택적 입력이라면
1. 거래일자 between
2. 거래일자 between, 종목코드=
3. 거래일자 between,종목코드=,투자자유형코드=
4. 거래일자 between,종목코드=,투자자유형코드=,주문매체구분코드=
5. 거래일자 between,종목코드=,주문모체구분코드=
6. 거래일자 between,투자자유형코드=
7. 거래일자 between,투자자유형코드=, 주문매체구분코드=
8. 거래일자 between,주문매체구분코드=
- but ) 현실적으로 어려움
- so) 변별력이 좋은 컬럼 중심으로 2~3개의 sql로 분기
- if 문을 이용해 분기하거나 union all을 사용
<인덱스 구성>
index01: 종목코드 + 거래일자
index02: 투자자유형코드 + 거래일자 + 주문매체구분코드
index03: 거래일자 + 주문매체구분코드
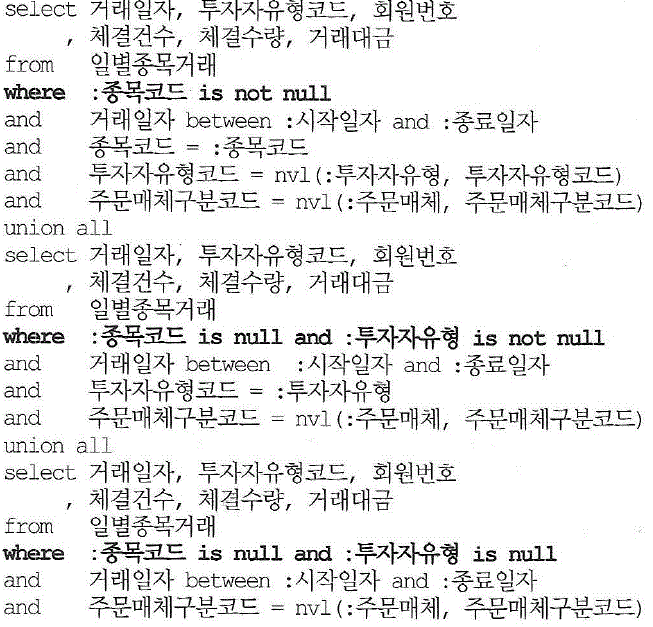
- 이방법 역시 매번 인덱스 구성전략을 고민하면서 개발하기는 힘들므로
- union all 분기는 일반적인 sql 작성보다 튜닝차원에서 접근이 필요
(3) 선택적 검색 조건에 대한 현실적인 대안
- static sql 사용을 원칙으로 하되 입력 조건에 따라 sql이 너무 많이 생성될때는 dynamic sql의 사용을 허가
- sql 개수 많더라도 일부만 주로 사용되므로 실질적인 하드 파싱 부하는 거의 없음
- 라이브러리 캐시 효율화의 핵심인 바인드 변수 사용 원칙은 준수
- pl/sql 문에서 조건절을 동적으로 구성하되 바인드 변수를 사용하도록 코딩한 예 (java,pro*c활용)
SQLStmt := ‘SELECT 거래일자, 종목코드, 투자자유형코드, ‘
|| ‘주문매체코드, 체결건수, 체결수량, 거래대금 ‘
|| ‘FROM 일별종목거래’
|| ‘WHERE 거래일자 BETWEEN :1 and :2 ‘;
if :종목코드 is null then
sqlstmt:=sqlstmt|| ‘and :3 is null ‘;
else
sqlstmt:=sqlstmt|| ‘and 종목코드=:3 ‘;
end if;
if :투자자유형 is null then
sqlstmt:=sqlstmt|| ‘and :4 is null ‘;
else
sqlstmt:=sqlstmt|| ‘and 투자자유형코드=:4 ‘;
end if;
execute immediate SQLStmt
into :A, :B, :C, :D, :E, :F, :G
using :시작일자, 종료일자, :종목코드, :투자자유형코드;
- Visual Basic 스타일로 변환 (delphi등 활용)
SQLStmt =”select 거래일자, 종목코드, 투자자유형코드 “&
“ , 주문매체코드, 체결건수, 체결수량, 거래대금 “ &_
“from 일별종목거래 where 거래일자 between ? and ? “
comm.parameters.append _
comm.createparameter (“시작일자”,advarchar, adparaminput,8,시작일자.text)
comm.parameters.append _
comm.createparameter (“종료일자”,advarchar, adparaminput,8,종료일자.text)
if 종목.text <>”” then
sqlstmt=sqlstmt & “and 종목코드 =?”
comm.parameters.append _
comm.createparameter (“종목코드작일자”,advarchar, adparaminput,8,종목.text)
end if
if 투자자유형.목.text <>”” then
sqlstmt=sqlstmt & “and 투자자유형코드 =?”
comm.parameters.append _
comm.createparameter (“투자자유형코드”,advarchar, adparaminput,8,투자자유형.text)
end if
comm.commandtext =sqlstmt
set rs.comm.execute
- sql을 다이나믹하게 구성하면 sql repository에서 sql을 수집해
테이블 액세스 유형을 분석하면서 인덱스를 설계할때 다소 불편해짐, 힌트를 사용해 튜닝하기도 곤란
(4) 선택적 검색 조건에 사용할 수 있는 기법 성능 비교
A. OR 조건을 사용하는 경우

- 항상 table full scan 으로 처리 되므로 인덱스 활용시는 사용 불가
B. LIKE 연산자를 사용하는 경우

- 인덱스 사용가능
- but) :isu_cd 값을 입력하지 않을때 table full scan이 유리한데도 인덱스 사용
C. NVL 함수를 사용하는 경우

D. DECODE 함수를 사용하는 경우

- c,d 방식은 사용자의 :isu_cd 입력 여부에 따라 full table scan과 index scan으로 실행계획이 자동 분기
- 해당 컬럼이 not null 컬럼이여야함, null 허용일경우 결과 집합이 달라짐
SQL> SELECT * FROM dual;
D
-
X
SQL> SELECT * FROM dual WHERE NULL is null;
D
-
X
SQL> SELECT * FROM dual WHERE NULL=null;
no rows selected
SQL>
- SELECT * FROM dual; -> x 리턴
- SELECT * FROM dual WHERE NULLis null; -> x 리턴
- SELECT * FROM dual WHERE NULL=null; -> false 리턴, 아무것도 없음
- nvl,decode 를 여러 컬럼에 사용했을경우 변별력이 가장 좋은 컬럼 기준으로 한번만 분기가 일어남
-> 복잡한 옵션 처리시는 어려움
E. Union all 을 사용하는 경우

- 정리
- not null 컬럼일 경우 nvl, decode 를 사용 하는것이 편함
- null 값을 허용하고 인덱스 조건으로 의미있는 컬럼이라면 union all을 사용해 명시적으로 분기
- 인덱스 액세스 조건 이 아닌경우 (인덱스 필터, 테이블 필터 조건으로 사용되는 컬럼)
:c is null or col =:c 또는 c like :c ||’%’ 어떤 방식을 사용해도 무방
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 66 | 부록 | 남송휘 | 2012.06.06 | 2425 |
| 65 | 8._IO_효율화_원리 | 운영자 | 2012.06.06 | 4118 |
| 64 |
3._Deterministic_함수_사용_시_주의사항
| 정찬호 | 2012.05.29 | 4085 |
| 63 | 2._Cursor_Sharing | 운영자 | 2012.05.28 | 5990 |
| 62 | 7._Result_캐시 | 운영자 | 2012.05.27 | 4156 |
| 61 |
3._Single_Block_vs._Multiblock_IO
| 정찬호 | 2012.05.23 | 3959 |
| 60 |
2._Memory_vs._Disk_IO
| 정찬호 | 2012.05.23 | 4166 |
| 59 |
1._블록_단위_IO
| 정찬호 | 2012.05.22 | 3923 |
| 58 |
6장._IO_효율화_원리
| 정찬호 | 2012.05.22 | 3806 |
| 57 |
1._Library_Cache_Lock_Pin
| 남송휘 | 2012.05.21 | 3962 |
| 56 |
6._RAC_캐시_퓨전
| 남송휘 | 2012.05.21 | 17525 |
| 55 | 5._Direct_Path_IO | 남송휘 | 2012.05.21 | 7533 |
| 54 |
4._Prefetch
| 남송휘 | 2012.05.21 | 3593 |
| 53 | 8._PLSQL_함수_호출_부하_해소_방안 | 남송휘 | 2012.05.21 | 3451 |
| 52 | 5._Fetch_Call_최소화 [1] | 박영창 | 2012.05.15 | 4806 |
| 51 |
7._PLSQL_함수의_특징과_성능_부하
| 남송휘 | 2012.05.15 | 6638 |
| 50 | 6._페이지_처리의_중요성 | 남송휘 | 2012.05.15 | 3117 |
| 49 | 4._Array_Processing_활용 | 시와처 | 2012.05.14 | 3764 |
| 48 |
3._데이터베이스_Call이_성능에_미치는_영향
| 시와처 | 2012.05.13 | 3381 |
| » |
10._Dynamic_SQL_사용_기준
| 남송휘 | 2012.05.07 | 4275 |