7._PLSQL_함수의_특징과_성능_부하
2012.05.15 01:49
(1) PL/SQL 함수의 특징
- PL/SQL로 작성된 함수/프로시저
- Oracle Forms, Roacle Reports 같은 제품에서도 수행가능
- 컴파일 -> 바이트코드 생성 -> pl/sql 엔진만 있으면 어디서든 실행
- Interpreted
SQL> show parameter PLSQL
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
plsql_ccflags string
plsql_code_type string INTERPRETED
plsql_debug boolean FALSE
plsql_optimize_level integer 2
plsql_v2_compatibility boolean FALSE
plsql_warnings string DISABLE:ALL
SQL>
- PL/SQL 특징
- 함수실행시 sql 실행엔진과 pl/sql 가상머신 사이에 컨텍스트 스위칭이 일어남
- sql 실행 엔진이 사용하던 레이스터 정보를 백업후 pl/sql 엔진이 실행을 마치면 다시 복원
- c++,java,vb와 같은 일반 언어-> 모듈화, pl/sql 과 함수는 느려질수 있음
(2) Recursive Call 를 포함하지 않는 함수의 성능 부하
- 남용사례
SQL> create or replace function date_to_char(p_dt date) return varchar2
2 as
3 begin
4 return to_char(p_dt,'yyyy/mm/dd hh24:mi:ss');
5 end;
6 /
Function created.
SQL> create table t (no number,char_time varchar2(21) );
Table created.
SQL> set timing on
SQL> insert into t
2 select rownum no
3 , to_char(sysdate+rownum,'yyyy/mm/dd hh24:mi:ss') char_time
4 from dual
5 connect by level <=1000000;
1000000 rows created.
Elapsed: 00:00:06.76
SQL> insert into t
2 select rownum no
3 , date_to_char(sysdate+rownum) char_time
4 from dual
5 connect by level <=1000000;
1000000 rows created.
Elapsed: 00:00:27.02
SQL>
- 내장함수 to_char -> 6.76초
- 사용자함수 date_to_char ->27.02
- Recursive Call 없이 컨텍스트 스위칭 효과만으로 5~10배 느려질수 있음
(3) Recursive Call을 포함하는 함수의 성능 부하
- User Call
- 네트워크 트래필 발생
- Recursive Call
- 매번 Execute Call과 Fetch call 발생
- 대용량 데이터 조회시 레코드 단위로 함수를 호출하도록 쿼리 작성시 성능 저하
SQL> create or replace function date_to_char(p_dt date) return varchar2
2 as
3 l_empno number;
4 begin
5 select 1 into l_empno from dual;
6 return to_char(p_dt,'yyyy/mm/dd hh24:mi:ss');
7 end;
8 /
Elapsed: 00:00:00.19
SQL> insert into t
2 select rownum no
3 ,date_to_char(sysdate+rownum) char_time
4 from dual
5 connect by level <=1000000
6 /
Elapsed: 00:00:59.78
- dual 의 경우 i/o 전혀 발생하지 않는 쿼리
- Recursive Call 없는 함수와 비교하면 수배,
- 함수를 사용하지 않았을 때와 비교하면 매우 느려짐
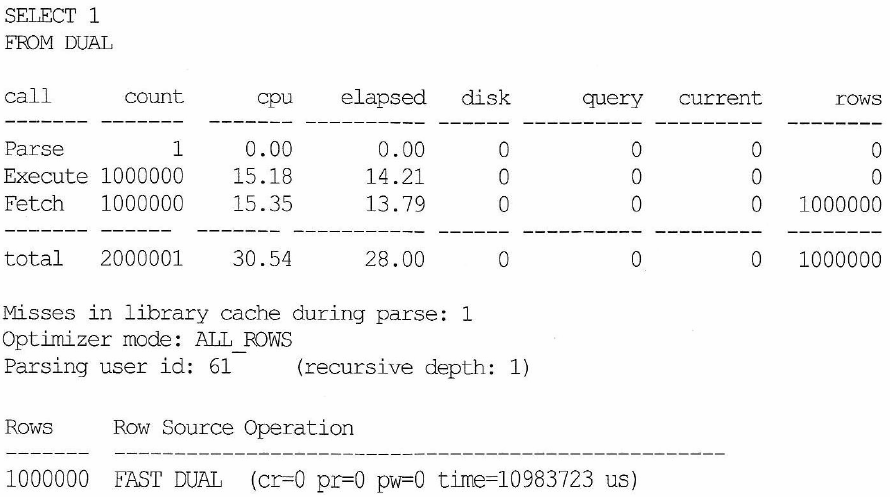
- 데이터베이스 Call이 200만번 추가 발생
- dual 이 아니라는 실제라면 훨씬 큰 성능 저하가 발생
(4) 함수를 필터 조건으로 사용할대 주의 사항
- 함수를 where 절에서 필터 조건으로 사용할때 주의 가 필요
- 조건절과 인덱스 상황에 따라 함수 호출 횟수가 달라짐
create or replace function emp_avg_sal return number
is
l_avg_sal number;
begin
select avg(sal) into l_avg_sal from emp;
return l_avg_sal;
end;
/
SQL> create index EMP_X01 on emp(sal);
Index created.
SQL> create index EMP_X02 on emp(deptno);
Index created.
SQL> create index EMP_X03 on emp(deptno,sal);
Index created.
SQL> create index EMP_X04 on emp(deptno, ename,sal);
Index created.
<case 1>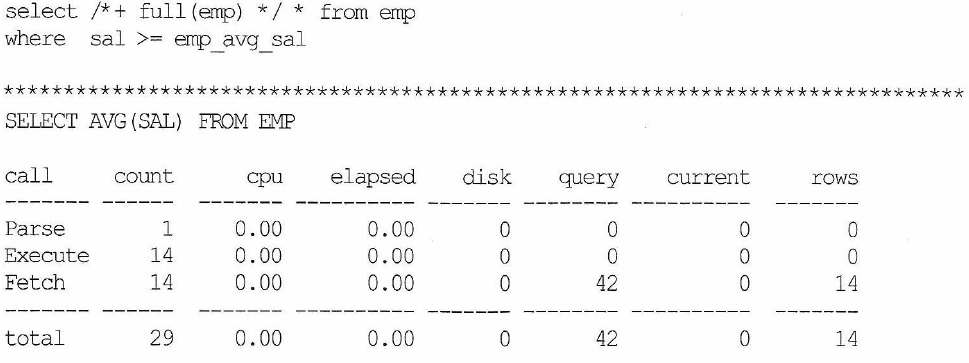
- 스캔 하면서 읽은 전체 건수 만큼 함수 호출
- emp table 레코드 14건
<case 2>
select /*+ index(emp (sal)) */* from emp
where sal>=emp_avg_sal
- sal 컬럼을 선두로 갖는 인덱스를 이용하면 함수호출이 단 한번
- 함수를 먼저 실행하고 , 리턴된 값으로 emp_x01인덱스를 액세스하는 상수 조건으로 사용
<case 3>

- exp_x02 인덱스,. deptno=20
- deptno=20 ; 5건, sal>=emp_avg_sal ; 3건
- deptno=20은 인덱스 액세스 조건, sal>= 테이블 필터 조건
- 테이블 액세스 하는 횟수 만큼 5번의 호출
<case 4>

- deptno+sal , emp_x03 인덱스
- sa.+ 조건까지 인덱스 액세스
- 함수 호출이 1번만
<case 5>
- deptno와 sal 컬럼 중간에 ename 컬럼, emp_x04
- ename 조건이 없어서 sal >= 이 인덱스 액세스 조건과 필터로 같이 사용
- 첫번째 레코드 액세스 단계에서 1번,
- 필터단계에서 나머지 4건을 찾는 동안 4번,
- deptno=20 범위를 넘어서는 조건 확인 에서 +1 , 총 6번의 함수 호출

<case 6>
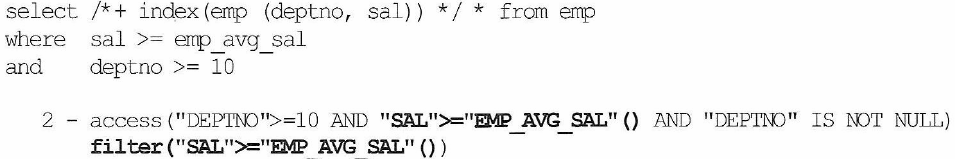
- ‘=’ 조건이 아닌경우
- 선행 컬럼이 조건절에 누락되거나 ‘=’ 조건이 아닌 경우 필터 조건으로 사용
- 인덱스 스캔할 첫번째 레코드 액세스 1번
- deptno >=10 조건 만족하는 나머지 13건 스캔시 13번
- 총 14번 발생 (맨마지막 까지 가므로 +1 없음)
| 조건절 | 사용인덱스 | 함수 호출 횟수 |
| sal>=emp_avg_sal | Full Table Scan | 14 |
| sal>=emp_avg_sal | emp_x01: sal | 1 |
| sal>=emp_avg_sal deptno=20 | emp_x02: deptno | 5 |
| sal>=emp_avg_sal deptmp=20 | emp_x03: deptno,sal | 1 |
| sal>=emp_avg_sal deptno=20 | emp_x04: deptno,ename,sal | 6 |
| sal>=emp_avg_sal deptno>=10 | emp_x03: deptno,sal | 14 |
- 대용량 테이블에서는 조건절과 인덱스 구성에 따라 성능 차이가 매우 크게 나타남
(5) 함수와 읽기 일관성
SQL> create table lookuptable (key number,value varchar2(100) );
Table created.
Elapsed: 00:00:00.16
SQL> insert into lookuptable values (1,'YAMAHA');
1 row created.
Elapsed: 00:00:00.00
SQL> commit;
Commit complete.
Elapsed: 00:00:00.00
SQL> create or replace function lookup (l_input number) return varchar2
2 as
3 l_output lookuptable.value%TYPE;
4 begin
5 select value into l_output from lookuptable where key=l_input;
6 return l_output;
7 end;
8 /
Function created.
Elapsed: 00:00:00.05
SQL>
- lookup 함수를 참조하는 쿼리를 수행하고 결과 집합을 fetch 하는 동안
- 다른세션에서 lookuptable 로부터 value 값을 변경한다면?
- fetch 하면서 lookup 함수가 반복 호출되서 중간부터 다른 결과 값을 리턴
- 문장 수준 읽기 일관성이 보장되지 않음
session 1 | session 2 |
| SQL> update lookuptable set value='babo'; |
- 함수 내에서 수행되는 Recursive 쿼리는 메인 쿼리의 시작 시점와 무관하게 그 쿼리가 수행되는 시점을 기준으로 블록을 읽음

- 주식 종몰별 현재가와 시가총액이 수시로 변함
- 함수에 스칼라 서브쿼리를 덧씌우더라도 인 문제를 해소할수 업음
- 아래처럼 조인문또는 스칼라 서브쿼리를 사용할때만 완벽한 문장수준 읽기 일관성이 보장

- 프로시저, 패키지, 트리거 사용시 공통으로 나타남
(6) 함수의 올바른 사용기준
- 정해진 shared pool 크기 내에서 소화할 수 있는 적정 개수의 SQL과 pl/sql 단위 프로그램을 유지하도록 노력해야함
- 연산 위주의 작업은 애플리케이션 서바단에서
- SQL 수행이 많은 작업은 오라클 함수 /프로시저를 이용
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 66 | 부록 | 남송휘 | 2012.06.06 | 2425 |
| 65 | 8._IO_효율화_원리 | 운영자 | 2012.06.06 | 4118 |
| 64 |
3._Deterministic_함수_사용_시_주의사항
| 정찬호 | 2012.05.29 | 4085 |
| 63 | 2._Cursor_Sharing | 운영자 | 2012.05.28 | 5990 |
| 62 | 7._Result_캐시 | 운영자 | 2012.05.27 | 4156 |
| 61 |
3._Single_Block_vs._Multiblock_IO
| 정찬호 | 2012.05.23 | 3959 |
| 60 |
2._Memory_vs._Disk_IO
| 정찬호 | 2012.05.23 | 4166 |
| 59 |
1._블록_단위_IO
| 정찬호 | 2012.05.22 | 3923 |
| 58 |
6장._IO_효율화_원리
| 정찬호 | 2012.05.22 | 3806 |
| 57 |
1._Library_Cache_Lock_Pin
| 남송휘 | 2012.05.21 | 3962 |
| 56 |
6._RAC_캐시_퓨전
| 남송휘 | 2012.05.21 | 17525 |
| 55 | 5._Direct_Path_IO | 남송휘 | 2012.05.21 | 7534 |
| 54 |
4._Prefetch
| 남송휘 | 2012.05.21 | 3593 |
| 53 | 8._PLSQL_함수_호출_부하_해소_방안 | 남송휘 | 2012.05.21 | 3451 |
| 52 | 5._Fetch_Call_최소화 [1] | 박영창 | 2012.05.15 | 4806 |
| » |
7._PLSQL_함수의_특징과_성능_부하
| 남송휘 | 2012.05.15 | 6638 |
| 50 | 6._페이지_처리의_중요성 | 남송휘 | 2012.05.15 | 3117 |
| 49 | 4._Array_Processing_활용 | 시와처 | 2012.05.14 | 3764 |
| 48 |
3._데이터베이스_Call이_성능에_미치는_영향
| 시와처 | 2012.05.13 | 3381 |
| 47 |
10._Dynamic_SQL_사용_기준
| 남송휘 | 2012.05.07 | 4275 |