8. 고급 조인 테크닉-1
2011.04.03 18:56
2.8 고급조인테크닉
2.8.1 누적매출구하기
- 전제 : 각 지점별로 판매월과 함께 증가하는 누적매출 구하는 방법
-- 1. 월별지점매출 테이블을 생성.
CREATE TABLE 월별지점매출
AS
SELECT DEPTNO "지점"
, ROW_NUMBER() OVER (PARTITION BY DEPTNO ORDER BY EMPNO) "판매월"
, ROUND(DBMS_RANDOM.VALUE(500, 1000)) "매출"
FROM EMP
ORDER BY DEPTNO ;
-- 2. 월별지점매출 테이블을 확인.
SELECT * FROM 월별지점매출;
-- 3. 오라클 8i에서부터 제공 된 분석함수 사용예
SELECT 지점, 판매월, 매출
, SUM(매출) OVER (PARTITION BY 지점 ORDER BY 판매월
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) 누적매출
FROM 월별지점매출;
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 546 | 4 (25)| 00:00:01 |
| 1 | WINDOW SORT | | 14 | 546 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL| 월별지 | 14 | 546 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------
-- 4. 오라클 8i이전 분석함수가 지원 되지않은 사용예
SELECT T1.지점, T1.판매월, MIN(T1.매출) 매출, SUM(T2.매출) 누적매출
FROM 월별지점매출 T1, 월별지점매출? T2
WHERE T2.지점 = T1.지점
AND T2.판매월 <= T1.판매월
GROUP BY T1.지점, T1.판매월
ORDER BY T1.지점, T1.판매월;
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 234 | 8 (25)| 00:00:01 |
| 1 | SORT GROUP BY | | 3 | 234 | 8 (25)| 00:00:01 |
|* 2 | HASH JOIN | | 3 | 234 | 7 (15)| 00:00:01 |
| 3 | TABLE ACCESS FULL| 월별지 | 14 | 546 | 3 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL| 월별지 | 14 | 546 | 3 (0)| 00:00:01 |
------------------------------------------------------------------------------
-- 5. 결과
지점 판매월 매출 지점 판매월 매출 누적매출
10 1 630 10 1 630 630
10 2 992 10 2 992 1622
10 3 911 10 3 911 2533
20 1 583 20 1 583 583
20 2 993 20 2 993 1576
20 3 874 20 3 874 2450
20 4 786 -------> 20 4 786 3236
20 5 738 20 5 738 3974
30 1 644 30 1 644 644
30 2 828 30 2 828 1472
30 3 778 30 3 778 2250
30 4 559 30 4 559 2809
30 5 799 30 5 799 3608
30 6 945 30 6 945 4553
- 분석함수는 8i 버전에서 PERSNAL EDITION, ENTERPRISE EDITION에서 지원하고,
- 9i버전에서는 모든 버전에 지원된다.
-- 6. 참고사항 : 분석함수문법은 다음과 같다.
SELECT ANALYTIC_FUNCTION ( ARGUMENTS )
OVER( [ PARTITION BY 칼럼 ] [ ORDER BY 절 ] [ WINDOWING 절] )
FROM 테이블 명;
- PARTITION BY : 전체 집합을 기준에 의해 소그룹 분할
- ORDER BY : PARTITION BY에 나열된 그룹을 정렬
- WINDOWING : 펑션의 대상이 되는 행 기준으로 범위를 세밀하게 조정
2.8.2 선분이력끊기
- 전제
1. 선분이력 레코드를 가공해야 할때, 월말 기준으로 선분을 끊는 경우
2. 두 선분이 겹치는 구간에 대한 시작일자 및 종료일자 선택 규칙



-- 1. 월도 및 선분이력 테이블 생성
-- 월도 데이블 생성
CREATE TABLE 월도 (기준월, 시작일자, 종료일자)
AS
SELECT '2009/06', '2009/06/01', '2009/06/30' FROM DUAL UNION ALL
SELECT '2009/07', '2009/07/01', '2009/07/31' FROM DUAL UNION ALL
SELECT '2009/08', '2009/08/01', '2009/08/31' FROM DUAL UNION ALL
SELECT '2009/09', '2009/09/01', '2009/09/30' FROM DUAL UNION ALL
SELECT '2009/10', '2009/10/01', '2009/10/31' FROM DUAL;
SELECT * FROM 월도;
기준월 시작일자 종료일자
2009/06 2009/06/01 2009/06/30
2009/07 2009/07/01 2009/07/31
2009/08 2009/08/01 2009/08/31
2009/09 2009/09/01 2009/09/30
2009/10 2009/10/01 2009/10/31
-- 선분이력 데이블 생성
CREATE TABLE 선분이력(상품번호, 시작일자, 종료일자, 데이터)
AS
SELECT 'A', '2009/07/13', '2009/08/08', 'A1' FROM DUAL UNION ALL
SELECT 'A', '2009/08/09', '2009/08/20', 'A2' FROM DUAL UNION ALL
SELECT 'A', '2009/08/21', '2009/10/07', 'A3' FROM DUAL;
SELECT * FROM 선분이력;
상품번호 시작일자 종료일자 데이터
A 2009/07/13 2009/08/08 A1
A 2009/08/09 2009/08/20 A2
A 2009/08/21 2009/10/07 A3
-- 변환된 선분이력
SELECT A.기준월, B.시작일자, B.종료일자, B.상품번호, B.데이터
FROM 월도 A, 선분이력 B
WHERE B.시작일자 <= A.종료일자
AND B.종료일자 >= A.시작일자
ORDER BY A.기준월, B.시작일자;
기준월 시작일자 종료일자 상품번호 데이터 스타일
2009/07 2009/07/13 2009/08/08 A A1 5----->8
2009/08 2009/07/13 2009/08/08 A A1 5----->9
2009/08 2009/08/09 2009/08/20 A A2 6----->10
2009/08 2009/08/21 2009/10/07 A A3 7----->11
2009/09 2009/08/21 2009/10/07 A A3 7----->12
2009/10 2009/08/21 2009/10/07 A A3 7----->13
-- 변환된 선분이력 결과집합
SELECT 기준월
, CASE WHEN LST = 시작일자1 AND GST = 종료일자2 THEN 시작일자2 -- 스타일 A
WHEN LST = 시작일자2 AND GST = 종료일자1 THEN 시작일자1 -- 스타일 B
WHEN LST = 시작일자1 AND GST = 종료일자1 THEN 시작일자2 -- 스타일 C
WHEN LST = 시작일자2 AND GST = 종료일자2 THEN 시작일자1 -- 스타일 D
END 시작일자
, CASE WHEN LST = 시작일자1 AND GST = 종료일자2 THEN 종료일자1 -- 스타일 A
WHEN LST = 시작일자2 AND GST = 종료일자1 THEN 종료일자2 -- 스타일 B
WHEN LST = 시작일자1 AND GST = 종료일자1 THEN 종료일자2 -- 스타일 C
WHEN LST = 시작일자2 AND GST = 종료일자2 THEN 종료일자1 -- 스타일 D
END 종료일자
, 상품번호
, 데이터
FROM (
SELECT B.상품번호, B.데이터, A.기준월
, A.시작일자 시작일자1, B.시작일자 시작일자2
, A.종료일자 종료일자1, B.종료일자 종료일자2
, LEAST(A.시작일자, A.종료일자, B.시작일자, B.종료일자) LST
, GREATEST(A.시작일자, A.종료일자, B.시작일자, B.종료일자) GST
FROM 월도 A, 선분이력 B
WHERE B.시작일자 <= A.종료일자
AND B.종료일자 >= A.시작일자
) ;
기준월 시작일자 종료일자 상품번호 데이터 스타일
2009/07 2009/07/13 2009/07/31 A A1 스타일 A
2009/08 2009/08/01 2009/08/08 A A1 스타일 B
2009/08 2009/08/09 2009/08/20 A A2 스타일 C
2009/08 2009/08/21 2009/08/31 A A3 스타일 A
2009/09 2009/09/01 2009/09/30 A A3 스타일 D
2009/10 2009/10/01 2009/10/07 A A3 스타일 B
- 결과
1. 겹치는 구간의 시작일자는 두시작일자 중 큽값을 취하고
2. 종료일자는 두 종료일자 중 작은 값을 취하면 된다.
SELECT A.기준월
, LEAST(A.시작일자, B.시작일자) 시작일자
, GREATEST(A.종료일자, B.종료일자) 종료일자
, B.상품번호
, B.데이터
FROM 월도 A, 선분이력 B
WHERE B.시작일자 <= A.종료일자
AND B.종료일자 >= A.시작일자
ORDER BY A.기준월, B.시작일자;
기준월 시작일자 종료일자 상품번호 데이터
2009/07 2009/07/01 2009/08/08 A A1
2009/08 2009/07/13 2009/08/31 A A1
2009/08 2009/08/01 2009/08/31 A A2
2009/08 2009/08/01 2009/10/07 A A3
2009/09 2009/08/21 2009/10/07 A A3
2009/10 2009/08/21 2009/10/31 A A3
2.8.3 테이터 복제를 통한 소계 구하기
- 전제
1. 쿼리 작성시 데이터 복제 기법을 활용해야 할때
CREATE TABLE COPY_T (NO NUMBER, NO2 VARCHAR2(2));
INSERT INTO COPY_T
SELECT ROWNUM, LPAD(ROWNUM, 2, '0') FROM ALL_TABLES WHERE ROWNUM <= 31;
--SELECT ROWNUM, LPAD(ROWNUM, 2, '0') FROM DUAL CONNECT BY LEVEL <= 31;
ALTER TABLE COPY_T ADD CONSTRAINT COPY_T_PK PRIMARY KEY(NO);
CREATE UNIQUE INDEX COPY_T_NO2_IDX ON COPY_T(NO2);
- 방법
1. 부등호 조인을 이용한 데이터 복제
-- 총42건 : EMP 총 14 x (B.NO <= 3)
SELECT COUNT(*)
FROM EMP A, COPY_T B
WHERE B.NO <= 3;
2. 카티션 곱 발생 시켜 복제 (검색하고자 했던 데이터뿐 아니라 조인에 사용된 테이블의 모든 데이터가 RETRUN되는 현상)
-- 조인 조건이 잘못된 경우
-- 조인 조건을 정의하지 않았을경우
-- 9i 버그로 인해 인라인뷰로 구현
SELECT * FROM (SELECT ROWNUM, LPAD(ROWNUM, 2, '0') FROM DUAL CONNECT BY LEVEL <= 2);
-- 그 외 버전
SELECT ROWNUM, LPAD(ROWNUM, 2, '0') FROM DUAL CONNECT BY LEVEL <= 2;
-- 총42건 : EMP 총 14 x (LEVEL <= 2)
SELECT COUNT(*)
FROM EMP A, (SELECT ROWNUM NO FROM DUAL CONNECT BY LEVEL <= 2) B;
3. 데이터 복제 기법을 활용하여 부서별 소계 구하기
BREAK ON 부서번호
COLUMN 부서번호 FORMAT 9999
COLUMN 사원번호 FORMAT A10
SELECT DEPTNO 부서번호
, DECODE(NO, 1, TO_CHAR(EMPNO), 2, '부서계') 사원번호
, SUM(SAL) 급여합, ROUND(AVG(SAL)) 급여평균
FROM EMP A, (SELECT ROWNUM NO FROM DUAL CONNECT BY LEVEL <= 2)
GROUP BY DEPTNO, NO, DECODE(NO, 1, TO_CHAR(EMPNO), 2, '부서계')
ORDER BY 1, 2;
부서번호 사원번호 급여합 급여평균
-------- ---------- ---------- ----------
10 7782 2450 2450
7839 5000 5000
7934 1300 1300
부서계 8750 2917
20 7369 800 800
7566 2975 2975
7788 3000 3000
7876 1100 1100
7902 3000 3000
부서계 10875 2175
30 7499 1600 1600
7521 1250 1250
7654 1250 1250
7698 2850 2850
7844 1500 1500
7900 950 950
부서계 9400 1567
17 rows selected.
4. GROUP BY를 활용하여 부서별 소계 구하기
COLUMN 부서번호 FORMAT A10
SELECT DECODE(NO, 3, NULL, TO_CHAR(DEPTNO)) 부서번호
, DECODE(NO, 1, TO_CHAR(EMPNO), 2, '부서계', 3, '총계') 사원번호
, SUM(SAL) 급여합, ROUND(AVG(SAL)) 급여평균
FROM EMP A, (SELECT ROWNUM NO FROM DUAL CONNECT BY LEVEL <= 3)
GROUP BY DECODE(NO, 3, NULL, TO_CHAR(DEPTNO))
, NO, DECODE(NO, 1, TO_CHAR(EMPNO), 2, '부서계', 3, '총계')
ORDER BY 1, 2;
부서번호 사원번호 급여합 급여평균
---------- ---------- ---------- ----------
10 7782 2450 2450
7839 5000 5000
7934 1300 1300
부서계 8750 2917
20 7369 800 800
7566 2975 2975
7788 3000 3000
7876 1100 1100
7902 3000 3000
부서계 10875 2175
30 7499 1600 1600
7521 1250 1250
7654 1250 1250
7698 2850 2850
7844 1500 1500
7900 950 950
부서계 9400 1567
총계 29025 2073
18 rows selected.
5. ROLLUP을 활용하여 부서별 소계 구하기(데이터 복제 기법을 쓰지 않는다.)
BREAK ON 부서번호
COLUMN 부서번호 FORMAT 9999
COLUMN 사원번호 FORMAT A10
SELECT DEPTNO 부서번호
, CASE WHEN GROUPING(EMPNO) = 1 AND GROUPING(DEPTNO) = 1 THEN '총계'
WHEN GROUPING(EMPNO) = 1 THEN '부서계'
ELSE TO_CHAR(EMPNO) END 사원번호
, SUM(SAL) 급여합, ROUND(AVG(SAL)) 급여평균
FROM EMP
GROUP BY ROLLUP(DEPTNO, EMPNO)
ORDER BY 1, 2;
부서번호 사원번호 급여합 급여평균
-------- ---------- ---------- ----------
10 7782 2450 2450
7839 5000 5000
7934 1300 1300
부서계 8750 2917
20 7369 800 800
7566 2975 2975
7788 3000 3000
7876 1100 1100
7902 3000 3000
부서계 10875 2175
30 7499 1600 1600
7521 1250 1250
7654 1250 1250
7698 2850 2850
7844 1500 1500
7900 950 950
부서계 9400 1567
총계 29025 2073
18 rows selected.
2.8.4 상호배타적 관계의 조인
- 상호배타적 관계(Exclusive OR) : 어떤 엔티티가 두 개 이상의 다른 엔티티의 합집합과 관계를 갖는것
- 상품권결제와 온라인권 및 실권 테이블과의 관계
- 관계선에 표시기된 아크(Arc) 관계 확인

1. 결제일자
SELECT /*+ ORDERED USE_NL(B) USE_NL(C) USE_NL(D) */
A.주문번호 , A.결제일자, A.결제금액
, NVL(B.온라인권번호, C.실권번호) 상품권번호
, NVL(B.발행일시, D.발행일시) 발행일시
FROM 상품권결제 A, 온라인권 B, 실권 C, 실권발행 D
WHERE A.결제일자 BETWEEN :DT1 AND :DT2
AND B.온라인권번호(+) = A.온라인권번호
AND C.실권번호(+) = A.실권번호
AND D.발행번호(+) = C.발행번호
2. 상품권구분 + 결제일자
SELECT X.주문번호 , X.결제일자, X.결제금액, Y.온라인권번호 상품권번호, X.발행일시 발행일시
FROM 상품권결제 X, 온라인권 Y
WHERE X.상품권구분 = '1'
AND X.결제일자 BETWEEN :DT1 AND :DT2
AND Y.온라인권번호 = X.온라인권번호
UNION ALL
SELECT X.주문번호 , X.결제일자, X.결제금액, Y.실권번호 상품권번호, Z.발행일시 발행일시
FROM 상품권결제 X, 실권 Y, 실권발행 Z
WHERE X.상품권구분 = '2'
AND X.결제일자 BETWEEN :DT1 AND :DT2
AND Y.실권번호 = X.실권번호
AND Z.발행번호 = Y.발행번호
3. [결제일자 + 상품권구분] 변경시 [상품권구분 + 결제일자] 인덱스의 스캔범위 중복,
[결제일자]인덱스만 사용시 랜덤액세스 불가피
SELECT /*+ ORDERED USE_NL(B) USE_NL(C) USE_NL(D) */
A.주문번호 , A.결제일자, A.결제금액
, NVL(B.온라인권번호, C.실권번호) 상품권번호
, NVL(B.발행일시, D.발행일시) 발행일시
FROM 상품권결제 A, 온라인권 B, 실권 C, 실권발행 D
WHERE 결제일자 BETWEEN :DT1 AND :DT2
AND B.온라인권번호(+) = DECODE(A.상품권구분, '1', A.상품권번호)
AND C.실권번호(+) = DECODE(A.상품권구분, '2', A.상품권번호)
AND D.발행번호(+) = C.발행번호
2.8.5 최종 출력 건에 대해서만 조인하기
- 전제
1. 흔히 개발할때 게시판 관련해서 복사하듯이 쓰는 페이징 쿼리
2. 게시판 테이타는 수백만건 게시판유형에 따라 평균 10만건
3. 회원, 게시판유형, 질문유형 3개 테이블과의 조인 수행 하므로 성능 부하
SELECT * FROM (
SELECT ROWNUM NO, 등록일자, 번호, 제목, 회원명
, 게시판유형명, 질문유형명, COUNT(*) OVER () CNT
FROM (
SELECT A.등록일자, A.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명
FROM 게시판 A, 회원 B, 게시판유형 C, 질문유형 D
WHERE A.게시판유형 = :TYPE
AND B.회원번호 = A.작성자번호
AND B.게시판유형 = A.게시판유형
AND C.질문유형 = A.질문유형
ORDER BY A.등록일자 DESC, A.질문유형, A.번호
) WHERE ROWNUM <= 31
)WHERE NO BETWEEN 21 AND 30
4. 인덱스 구성은 아래와 같이 소트 오퍼레이션이 불가피
게시판_X01 : 게시판유형 + 등록일자 DESC + 번호
5. 게시판_X01 + 질문유형 (인덱스 컬럼 순서를 바꾸는 결정은 하기 쉽지 않으나 추가는 그것보다 낫다.)
게시판_X01 : 게시판유형 + 등록일자 DESC + 번호 + 질문유형
SELECT /*+ ORDERED USE_NL(A) USE_NL(B) USE_NL(C) USE_NL(D) ROWID(A) */
A.등록일자, A.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명, X.CNT
FROM (
SELECT RID, ROWNUM NO, COUNT(*) OVER () CNT
FROM (
SELECT ROWID RID
FROM 게시판
WHERE 게시판유형 = :TYPE
ORDER BY 등록일자 DESC, 질문유형, 번호
)
WHERE ROWNUM <= 31
) X, 게시판 A, 회원 B, 게시판유형 C, 질문유형 D
WHERE A.ROWID = X.RID
AND B.회원번호 = A.작성자번호
AND B.게시판유형 = A.게시판유형
AND C.질문유형 = A.질문유형
1. 게시판 테이블 두번 읽도록 작성했지만 인라인뷰는 인덱스만 읽고
2. 게시판 A 테이블 액세스할때에는 인라인뷰 X ROWID로 직접액세스
3. 실행계획에서 TABLE ACCESS BY INDEX ROWID > TABLE ACCESS BY USER ROWID
- 전제 : 위와 달리 NULL 허용컬럼이 있을경우, 업무적으로 NOT NULL값에 제약이 없어 NULL이 허용될때
매우 흔하다는 표현....
- 수행 : Outer(+) 기호만 붙여주면 된다.
WHERE A.ROWID = X.RID
AND B.회원번호(+) = A.작성자번호
AND B.게시판유형(+) = A.게시판유형
AND C.질문유형(+) = A.질문유형
- 전제 : 업무적으로 NULL이 허용하는 조인컬럼들에 대한 제외하고자 할때
- 수행 : 인라인뷰에 IS NOT NULL 추가
WHERE 게시판유형 = :TYPE
AND 작성자번호 IS NOT NULL
AND 게시판유형 IS NOT NULL
AND A.질문유형 IS NOT NULL
SELECT /*+ ORDERED USE_NL(B) USE_NL(C) USE_NL(D) */
A.등록일자, A.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명, A.CNT
FROM (
SELECT A.*, ROWNUM NO, COUNT(*) OVER () CNT
FROM (
SELECT 등록일자, 번호, 제목, 작성자번호, 게시판유형, 질문유형
FROM 게시판
WHERE 게시판유형 = :TYPE
AND 작성자번호 IS NOT NULL
AND 게시판유형 IS NOT NULL
AND 질문유형 IS NOT NULL
ORDER BY 등록일자 DESC, 질문유형, 번호
) A WHERE ROWNUM <= 31
) A, 회원 B, 게시판유형 C, 질문유형 D
WHERE NO BETWEEN 21 AND 30
AND B.회원번호 = A.작성자번호
AND B.게시판유형 = A.게시판유형
AND C.질문유형 = A.질문유형
반정규화는 성능을 위한 최후의 수단
- 전제
1. 정규화된 모델로 성능내기 어려울때, 반정규화를 답처럼 쓰지마라..
2. 발송메시지건수, 수신인수 동일 추출 속성들이 설계되어있다.
3. 수신확인자수와 수신대상자수를 새고 새글여부를 확인하는 스칼라 서브쿼리 성능 문제

SELECT ... FROM (
SELECT ... FROM (
SELECT A.발신인ID, A.발송일시, A.제목, B.사용자이름 AS 보낸이
, (SELECT COUNT(수신일시) FROM 메시지수신인 ...) 수신확인자수
, (SELECT COUNT(*) FROM 메시지수신인 ...) 수신대상자수
, (CASE WHEN EXISTS (SELECT 'X' FROM 메시지수신인
WHERE 발신자ID = A.발신자ID
AND 발송일시 = A.발송일시
AND 수신자ID = :로그인사용자ID
AND 수신일시 IS NULL ) THEN 'Y' END ) 새글여부
FROM 메시지 A, 사용자 B
ORDER BY A.발송일시 DESC
) A
WHERE ROWNUM <= 10
)
WHERE NO BETWEEN 1 AND 10;
- 문제점
1. 메세지를 수신할 때마다 메시지 테이블의 수신인수를 갱신해주는 DML 프로그램도 같이 작성해야한다.
2. 일상적이지 않은 업무 때문에 데이터 정합성이 훼손될 수 있다.(예, 사용자 탈퇴 후 메시지인수 갱신)
- 해결
1. 업무 규칙 누락이 생기지 않도록 않도록 꼼꼼히 점검.(반정규화 없이 성능 문제를 해결하는 것이 좋다.)
- 수행
1. 최종 출력되는 10건에 대해서만 수신정보와 새글여부확인 하기 때문에
2. 데이터베이스 설계자에게 DB성능 원리에 대한 깊은 연구가 필요한 이유가 여기에 있다.
SELECT A.발신인ID, A.발송일시, A.제목, B.사용자이름 AS 보낸이
, ( SELECT COUNT(수신일시) || '/' || COUNT(*) FROM 메시지수신인 ...) 수신확인
, ( CASE WHEN EXISTS (...) THEN 'Y' END ) 새글여부
FROM (
SELECT ROWNUM NO, ...
FROM (SELECT 발신인ID, 발송일시, 제목 FROM 메시지 ORDER BY 발송일시 DESC)
WHERE ROWNUM <= 30
) A, 사용자 B
WHERE NO BETWEEN 21 AND 30
AND ............;
2.8.6 징검다리 테이블 조인을 이용한 튜닝
- 전제
1. 앞서 성능저하를 두려워해 논리 데이터 모델링 단계에서 습관적인 반정규화실시

2. FROM 절에서 테이블 개수를 늘려 성능 향상시키는 방법
3. 아래의 쿼리는 고객의 요금 할인 혜택을 조회하고자 한다.
SELECT /*+ ORDERED USE_NL(S R)*/
C.고객번호, S.서비스번호, S.서비스구분
, S.서비스상태코드, S.서비스상태변경코드, R.할인시작일자, R.할인종료일자
FROM 고객 C, 서비스 S, 서비스요금할인 R
WHERE C.주민법인등록번호 = :CTZ_BIZ_NUM
AND S.명의고객번호 = C.고객번호
AND R.서비스번호 = S.서비스번호
AND R.서비스상품그룹 = '3001'
AND R.할인기간코드 = '15'
ORDER BY R.할인종료일자 DESC, S.서비스번호
--인덱스
고객_N1 : 주민법인등록번호
서비스_N2 : 명의고객번호 + 서비스번호
서비스요금할인_PK : 서비스요금할인_PK + 서비스상품그룹
서비스요금할인_N1 : 서비스상품그룹 + 할인기간코드
- 쿼리 수행시(319p~320p) : 서버구간에서만 28초, 블록I/O는 226,672번 발생
- Row Source Operation의 처리과정에서 각 오퍼레이션 단계에서의 출력 건수와 블록I/O 발생량
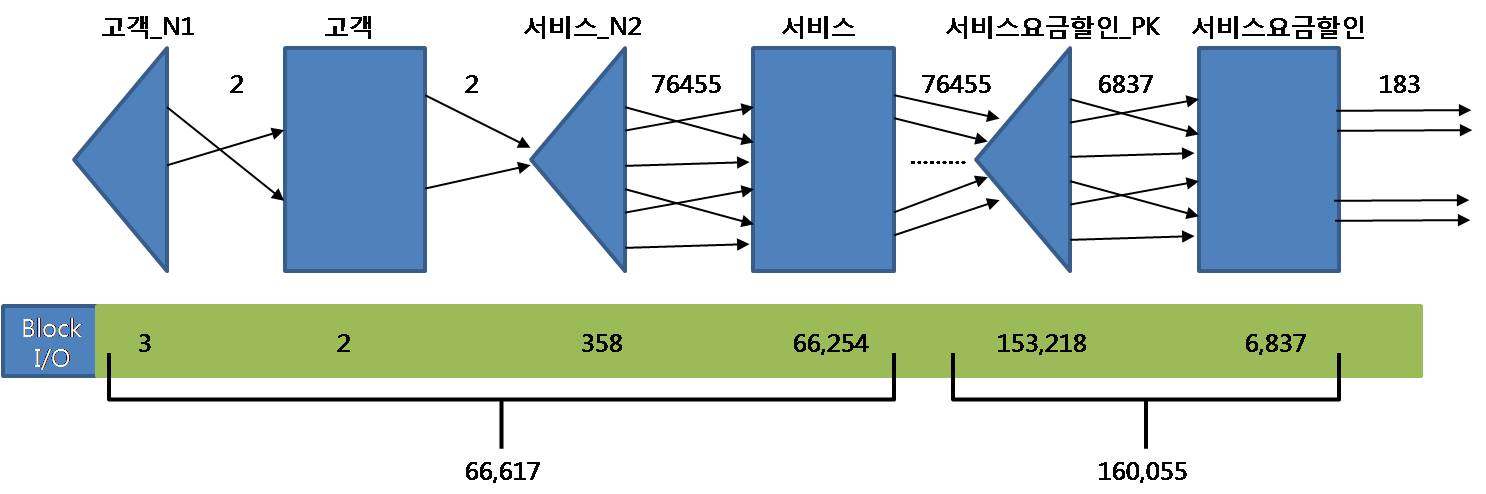
1. 최종건수 183건
2. 고객테이블 먼저 드리이빙 후 서비스테이블과 NL조인과정에서 66,617개의 블록I/O 발생
3. 서비스요금할인테이블과 NL조인과정에서 160,055개의 블록I/O 추가발생
4. 총 226,672개의 블록I/O 추가발생
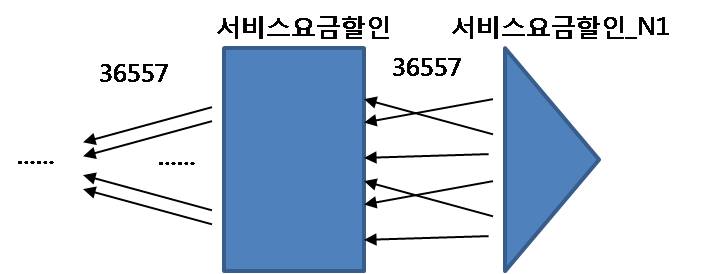
1. 서비스요금할인 테이블 먼저 드라이빙 되도록 바꾼다면
2. [할인기간코드 = '15' AND 서비스상품그룹코드 = '3001'] == 36,557레코드건
2. 테이블 액세스 하는 단계에서 24,826개의 블록I/O 발생
3. 조인순서를 바꾸더라도 조인액세스량 줄이기는 어렵다.
4. 해시조인유도시 91,443(= 66,617 + 24,826)개의 블록I/O 발생 예상.
5. 비록 I/O가 절반이상 줄었다 하더라도 속도는 만족할 수 없다.
6. 최종결과는 얼마되지않으나 필터조건만으로 각부분을 따로 읽으면 결과 건수가 아주 많을때는 튜닝이 어렵다.
7. 즉 NL, 해시 조인도 부하를 줄일 수 없다.
8. 서비스요금할인_N1 인덱스에 서비스번호컬럼을 추가
서비스요금할인_N1 : 서비스상품그룹 + 할인기간코드 + 서비스번호
SELECT /*+ ORDERED USE_HASH(R_BRDG) ROWID(S) ROWID(R) */ ------------------- 1
C.고객번호, S.서비스번호, S.서비스구분
, S.서비스상태코드, S.서비스상태변경코드, R.할인시작일자, R.할인종료일자
FROM 고객 C
, 서비스 S_BRDG, 서비스요금할인 R_BRDG -------------------- 2
, 서비스 S, 서비스요금할인 R
WHERE C.주민법인등록번호 = :CTZ_BIZ_NUM
AND S_BRDG.명의고객번호 = C.고객번호
AND R_BRDG.서비스번호 = S_BRDG.서비스번호
AND R_BRDG.서비스상품그룹 = '3001'
AND R_BRDG.할인기간코드 = '15'
AND S.ROWID = S_BRDG.ROWID -------------------- 3
AND R.ROWID = R_BRDG.ROWID -------------------- 4
ORDER BY R.할인종료일자 DESC, S.서비스번호
- 수행
1. 서비스번호를 추가함으로써 양쪽테이블에서 인덱스만 읽은 결과끼리 먼저 조인하고서
최종결과집합 183건에 대해서만 테이블 액세스
2. 테이블 액세스량을 줄이기 위해 징거다리 조인 추가(ALIAS '_BRDG' == BRIDGE)
3. 쿼리1번 인덱스에서 얻어진 집합끼리 조인할때 대량 데이터 조인이므로 해시조인
4. 쿼리3~4번 추가적인 인덱스 탐색없이 인덱스에서 읽은 ROWID값을 가지고 직접액세스(TABLE ACCESS BY USER ROWID)
5. 두번씩 액세스를 하도록 했지만 실제 처리일량은 한번만 액세스(323p)
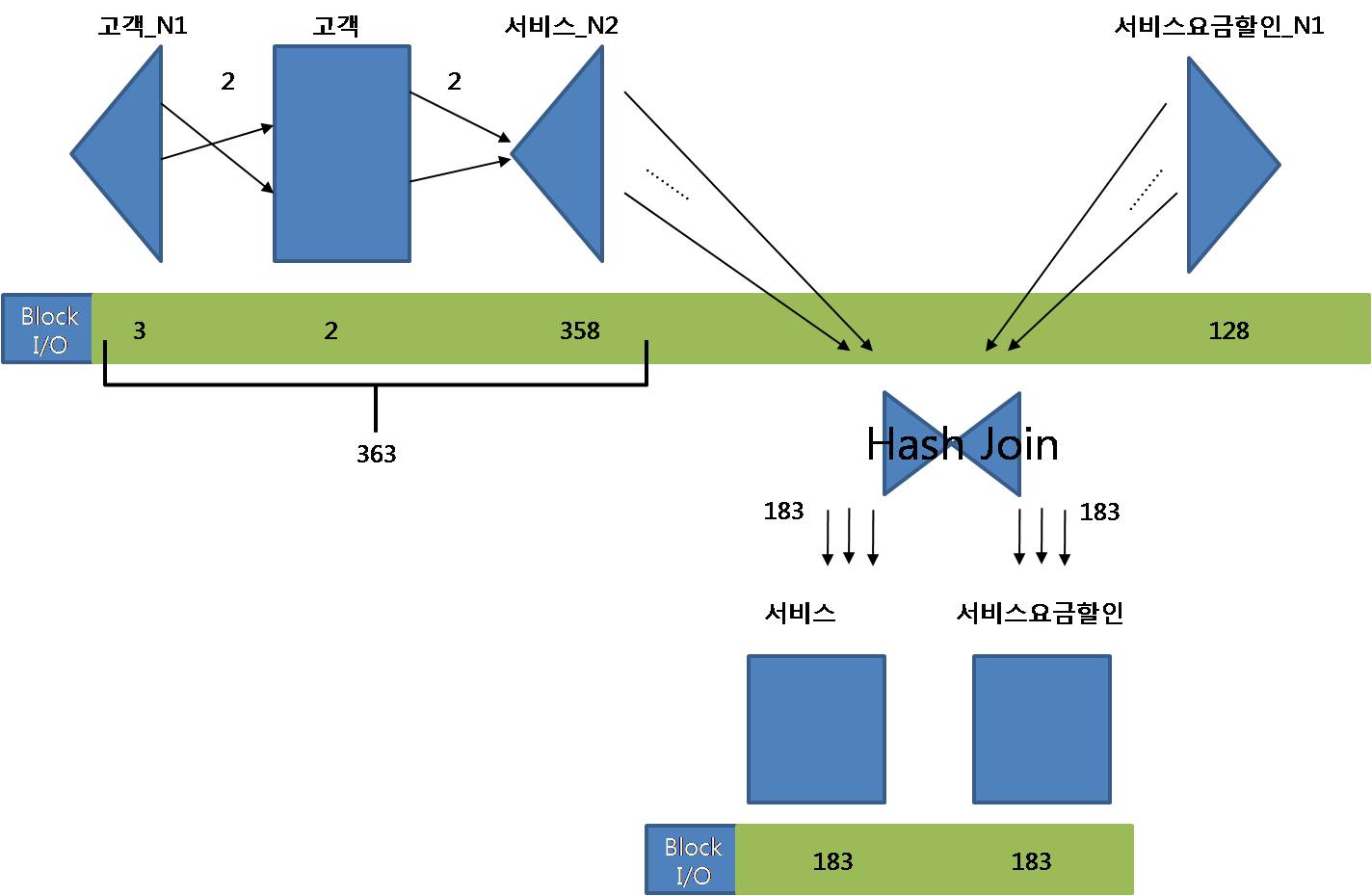
- 결과
1. 고객테이블과 서비스_N2 인덱스를 조인할 때는 블록I/O가 총 363번 발생
2. 서비스요금할인_N1만 읽을때도 블록I/O는 128개뿐
인조식별자사용에 의한 조인 성능 이슈
- 전제
1. 액세스경로에 대한 고려없이 인조 식별자를 설계하면 위와같은 조인이슈가 자주발생
*인조 식별자(Artificial Identifier OR Surrogate Identifier)
2. 주문일자 와 주문순번을 주문상세에 상속
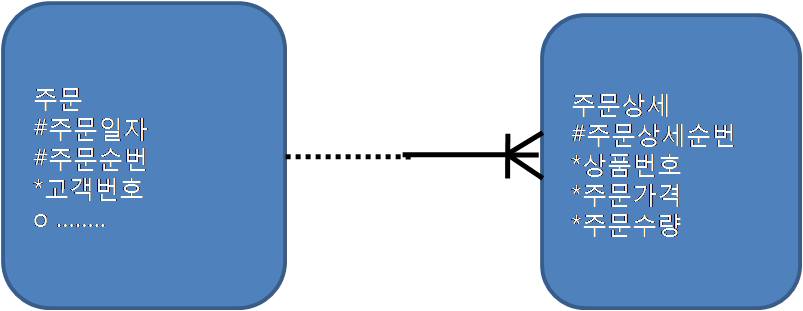
3. 특정주문일자에 발생한 특정상품 주문금액 집계(주문일자평균 10만건, 상품번호 1000건, 상품번호별 하루평균 600건)
SELECT SUM(주문상세.가격 * 주문상세.주문수량) 주문금액
FROM 주문, 주문상세
WHERE 주문.주문일자 = 주문상세.주문일자
AND 주문.주문순번 = 주문상세.주문순번
AND 주문.주문일자 = '20090315'
AND 주문상세.상품번호 = 'AC001'
- 결과
주문상세 인덱스 : [상품번호 + 주문일자] OR [주문일자 + 상품번호] 구성으로 효과적 대응
-- 4장 5절 조건절 이행 참조
- 전제
1. 주문번호을 주문상세에 상속
2. 특정주문일자에 발생한 특정상품 주문금액 집계
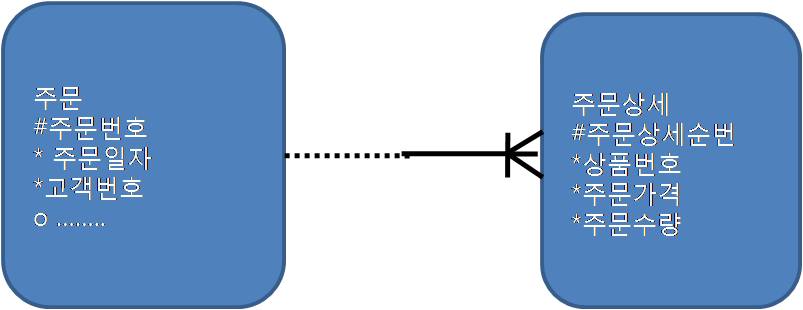
주문_PK : 주문번호
주문_X01 : 주문일자
주문상세_PK : 주문번호 + 주문일자
주문상세_X01 : 상품번호
SELECT SUM(주문상세.가격 * 주문상세.주문수량) 주문금액
FROM 주문, 주문상세
WHERE 주문.주문번호 = 주문상세.주문번호
AND 주문.주문일자 = '20090315'
AND 주문상세.상품번호 = 'AC001'
- 결과
1. 주문_PK 인덱스를 거쳐 주문상세 테이블 10만건 액세스 하고 상품번호로 필터 600건
2. 주문상세_PK 인덱스로 랜덤액세스를 줄이지만 조인 시도 횟수는 줄지 않음
3. 주문상세를 먼저 읽을시 상품번호로 인한 평균카디널리티 증가로 인한 본테이블 및 주문테이블의 랜덤액세스 비효율발생
4. 주문번호로 반정규화 하기보다 주문일자로 반정규화 하는게 더 효과적
5. 되도록이면, 반정규화를 정규화하든지 방법을 통해서 반정규화를 최대한 피하는게 좋다.
인조식별자를 둘 때 주의사항
- 장점
1. PK, FK가 단일 컬럼으로 구성되므로 테이블 간 연결 구조가 단순해지고 인덱스 저장공간이 최소화된다.
2. 다중컬럼으로 조인할 때보다 조인연산을 위한 CPU 사용량이 조금 감소
- 단점
1. 조인연산시 CPU 사용량이 감소가 미미
2. 조인연산횟수와 블록I/O 증가로 더 많은 시스템 리소스 낭비가 쉽다.
- 결과
1. 업무적으로 이미 통용되는 식별자이거나 유연성/확장성을 고려해 인조 식별자를 설계하는 경우를 제외하면
가급적 피하는것이 좋다.
2.8.7 점이력 조회
1. 점이력 : 데이터 변경이 발생할때마다 변경일자와 함께 새로운 이력레코드를 쌓는 방식
2. 점이력 레코드 빠르게 조회하는 방법
- 전제 : 찾고자 하는 시점보다 앞선 변경일자 중 마지막 레코드
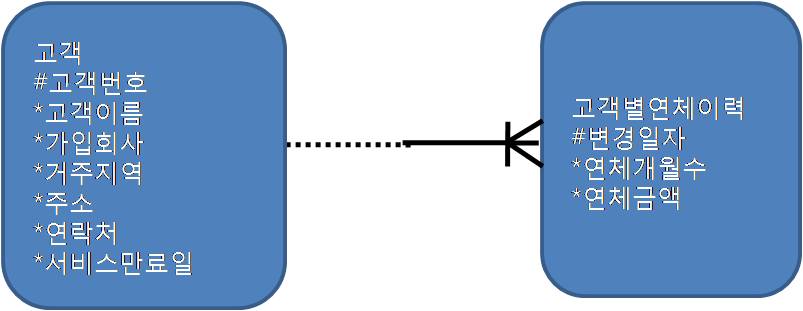
CREATE TABLE 고객
AS
SELECT EMPNO 고객번호, ENAME 고객명, 'C70' 가입회사
, '서울' 거주지역, '...' 주소, '123-' || EMPNO 연락처
, TO_CHAR(TO_DATE('20050101','YYYYMMDD')+ROWNUM*20000,'YYYYMMDD') 서비스만료일
FROM EMP
WHERE ROWNUM <= 10;
CREATE INDEX 고객_IDX01 ON 고객(가입회사);
CREATE TABLE 고객별연체이력
AS
SELECT A.고객번호, B.변경일자, B.연체개월수, B.연체금액
FROM 고객 A
,(SELECT TO_CHAR(TO_DATE('20050101', 'YYYYMMDD')+ROWNUM*2, 'YYYYMMDD') 변경일자
, ROUND(DBMS_RANDOM.VALUE(1, 12)) 연체개월수
, ROUND(DBMS_RANDOM.VALUE(100, 1000)) * 100 연체금액
FROM DUAL
CONNECT BY LEVEL <= 100000) B;
CREATE INDEX 고객별연체이력_IDX01 ON 고객별연체이력(고객번호, 변경일자);
SELECT A.고객명, A.거주지역, A.주소, A.연락처, B.연체금액
FROM 고객 A, 고객별연체이력 B
WHERE A.가입회사 = 'C70'
AND B.고객번호 = A.고객번호
AND B.변경일자 = (SELECT MAX(변경일자)
FROM 고객별연체이력
WHERE 고객번호 = A.고객번호
AND 변경일자 <= A.서비스만료일);
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 60M| 5690M| 62 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 4 | 128 | 3 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 39 | 3822 | 32 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID | 고객 | 10 | 660 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력| 1115K| | 2 (0)| 00:00:01 |
| 6 | SORT AGGREGATE | | 1 | 19 | | |
| 7 | FIRST ROW | | 558 | 10602 | 3 (0)| 00:00:01 |
|* 8 | INDEX RANGE SCAN (MIN/MAX)| 고객별연체이력| 558 | 10602 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.01 0 6 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.00 0 59 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.01 0.01 0 65 0 10
-- ID7~8 : 서브쿼리 내에서 서비스만료일보다 작은 레코드를 모두 스캔하지 않고 오라클이
인덱스를 꺼꾸로 스캔하면서 가장 큰값 하나만 찾는 방식
SELECT A.고객명, A.거주지역, A.주소, A.연락처, B.연체금액
FROM 고객 A, 고객별연체이력 B
WHERE A.가입회사 = 'C70'
AND B.고객번호 = A.고객번호
AND B.변경일자 = (SELECT /*+ INDEX_DESC(B 고객별연체이력_IDX01) */ 변경일자
FROM 고객별연체이력
WHERE 고객번호 = A.고객번호
AND 변경일자 <= A.서비스만료일
AND ROWNUM <= 1);
-----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 0 | 4 | 62 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID | 고객별연체이력| 4 | 128 | 3 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 39 | 3822 | 32 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 660 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객별연체이력| 1115K| | 2 (0)| 00:00:01 |
|* 6 | COUNT STOPKEY | | | | | |
|* 7 | INDEX RANGE SCAN | 고객별연체이력| 558 | 10602 | 3 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 6 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.00 0.08 11 59 0 10
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.00 0.08 11 65 0 10
-- 서브쿼리 내에서 액세스되는 인덱스 루트블록에 대한 버퍼 Pinning 효과가 사라져 블록 I/O가 더 발생
-- 두 쿼리 모두 고객별연체이력_idx01 두번 액세스하는 비효율 발생
-- index_desc 힌트와 rownum <= 1 조건 사용시 주의사항
1. 인덱스 구성이 변경되면 쿼리결과가 틀리게 될수있다. 따라서 first row(min/max) 알고리즘이 작동할때는
반드시 min/max 함수를 사용하는 것이 올바르다.
SELECT A.고객명, A.거주지역, A.주소, A.연락처
,(SELECT /*+ INDEX_DESC(B 고객별연체이력_IDX01) */ 연체금액
FROM 고객별연체이력 B
WHERE B.고객번호 = A.고객번호
AND B.변경일자 <= A.서비스만료일
AND ROWNUM <= 1) 연체금액
FROM 고객 A
WHERE 가입회사 = 'C70'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 3 0.00 0.01 0 3 0 0
Execute 3 0.00 0.00 0 0 0 0
Fetch 6 0.00 0.00 0 132 0 30
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 12 0.00 0.02 0 135 0 30
Rows Row Source Operation
------- ---------------------------------------------------
10 COUNT STOPKEY (cr=40 pr=0 pw=0 time=387 us)
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (cr=40 pr=0 pw=0 time=286 us)
10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=0 pw=0 time=191 us)(object id 52904)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=35 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=108 us)(object id 52902)
-- 스칼라 서브쿼리로 변환하면 인덱스를 두번 액세스하지 않아도 되기때문에 I/O를 그만큼 줄일 수 있다.
-- 인덱스 루트 블록에 대한 버퍼 Pinning 효과는 없다.
-- 연체금액 하나만 읽기 때문에 스칼라 서브쿼리로 변경하기가 쉬웠다.
-- 만약 두개 이상 컬럼을 읽어야 한다면, 필요한 컬럼연결(||)잘라쓰는(substr) 방법을 사용한다.
SELECT 고객명, 거주지역, 주소, 연락처
, TO_NUMBER(SUBSTR(연체, 3)) 연체금액
, TO_NUMBER(SUBSTR(연체, 1, 2)) 연체개월수
FROM (SELECT A.고객명, A.거주지역, A.주소, A.연락처
,(SELECT /*+ INDEX_DESC(B 고객별연체이력_IDX01) */
LPAD(연체개월수, 2) || 연체금액
FROM 고객별연체이력
WHERE 고객번호 = A.고객번호
AND 변경일자 <= A.서비스만료일
AND ROWNUM <= 1) 연체
FROM 고객 A
WHERE 가입회사 = 'C70'
)
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.01 0.00 0 3 0 0
Execute 2 0.00 0.00 0 0 0 0
Fetch 4 0.03 0.07 11 88 0 20
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 8 0.04 0.08 11 91 0 20
Rows Row Source Operation
------- ---------------------------------------------------
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=35 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=181 us)(object id 52902)
-- 이력테이블에서 읽어야 할 컬럼 개수가 많다면 일일이 문자열 연결작업이 번거롭다.
-- 이때, 스칼라 서브쿼리에서 rowid 값만 취하고 고객 연체이력을 한번더 조인해보자.
SELECT /*+ ORDERED USE_NL(B) ROWID(B) */ A.*, B.연체금액, B.연체개월수
FROM (SELECT A.고객명, A.거주지역, A.주소, A.연락처
,(SELECT /*+ INDEX_DESC(B 고객별연체이력_IDX01) */ ROWID RID
FROM 고객별연체이력 B
WHERE B.고객번호 = A.고객번호
AND B.변경일자 <= A.서비스만료일
AND ROWNUM <= 1) RID
FROM 고객 A
WHERE 가입회사 = 'C70') A, 고객별연체이력 B
WHERE B.ROWID = A.RID
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 111K| 10M| 15 (0)| 00:00:01 |
|* 1 | COUNT STOPKEY | | | | | |
|* 2 | INDEX RANGE SCAN DESCENDING | 고객별연체이력| 558 | 14508 | 3 (0)| 00:00:01 |
| 3 | NESTED LOOPS | | 11M| 1053M| 12 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY INDEX ROWID | 고객 | 10 | 660 | 2 (0)| 00:00:01 |
|* 5 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY USER ROWID | 고객별연체이력| 1115K| 35M| 1 (0)| 00:00:01 |
|* 7 | COUNT STOPKEY | | | | | |
|* 8 | INDEX RANGE SCAN DESCENDING| 고객별연체이력| 558 | 14508 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 4 0.00 0.00 0 5 0 0
Execute 4 0.00 0.00 0 0 0 0
Fetch 8 0.00 0.00 0 176 0 40
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 16 0.00 0.01 0 181 0 40
Rows Row Source Operation
------- ---------------------------------------------------
10 COUNT STOPKEY (cr=30 pr=0 pw=0 time=301 us)
10 INDEX RANGE SCAN DESCENDING 고객별연체이력_IDX01 (cr=30 pr=0 pw=0 time=201 us)(object id 52904)
10 NESTED LOOPS (cr=44 pr=0 pw=0 time=111 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=255 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=137 us)(object id 52902)
10 TABLE ACCESS BY USER ROWID 고객별연체이력 (cr=40 pr=0 pw=0 time=445 us)
-- 인덱스 이외의 컬럼을 참조하지 않았으므로 인덱스만 스캔 예상(TABLE ACCESS BY USER ROWID)
-- 일반적인 NL조인과 같은 Outer 인덱스 > Outer 테이블 > Inner 인덱스 > Inner 테이블 로 진행
-- 스칼라 서브쿼리를 이용하지않고
SELECT /*+ ORDERED USE_NL(B) ROWID(B) */
A.고객명, A.거주지역, A.주소, A.연락처, B.연체금액, B.연체개월수
FROM 고객 A, 고객별연체이력 B
WHERE A.가입회사 = 'C70'
AND B.ROWID = (SELECT /*+ INDEX(C 고객별연체이력_IDX01) */ ROWID
FROM 고객별연체이력 C
WHERE C.고객번호 = A.고객번호
AND C.변경일자 <= A.서비스만료일
AND ROWNUM <= 1);
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 111K| 10M| 15 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 11M| 1053M| 12 (0)| 00:00:01 |
| 2 | TABLE ACCESS BY INDEX ROWID| 고객 | 10 | 660 | 2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | 고객_IDX01 | 10 | | 1 (0)| 00:00:01 |
| 4 | TABLE ACCESS BY USER ROWID | 고객별연체이력| 1115K| 35M| 1 (0)| 00:00:01 |
|* 5 | COUNT STOPKEY | | | | | |
|* 6 | INDEX RANGE SCAN | 고객별연체이력| 558 | 14508 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------
SELECT /*+ ORDERED USE_NL(B) ROWID(B) */
A.고객명, A.거주지역, A.주소, A.연락처, B.연체금액, B.연체개월수
FROM 고객 A, 고객별연체이력 B
WHERE A.가입회사 = 'C70'
AND B.ROWID = (SELECT /*+ INDEX(C 고객별연체이력_IDX01) */ ROWID
FROM 고객별연체이력 C
WHERE C.고객번호 = A.고객번호
AND C.변경일자 <= A.서비스만료일
AND ROWNUM <= 1)
Rows Row Source Operation
------- ---------------------------------------------------
10 NESTED LOOPS (cr=44 pr=0 pw=0 time=107 us)
10 TABLE ACCESS BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=226 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr=2 pr=0 pw=0 time=132 us)(object id 52902)
10 TABLE ACCESS BY USER ROWID 고객별연체이력 (cr=40 pr=0 pw=0 time=413 us)
- 정해진 시점 기준으로 조회
- 전제 : 가입회사 = 'C70' 은 고객 10명 이였는데 가입회사별 고객수가 많을 경우 서브 쿼리 수행 횟수가 늘어나
랜덤 I/O 부하도 심해질 것이다.
가입회사 조건이 없고 정해진 시점을 기준으로 조회 한다면
SELECT /*+ FULL(A) FULL(B) FULL(C) USE_HASH(A B C) NO_MERGE(B) */
A.고객명, A.거주지역, A.주소, A.연락처, C.연체금액, C.연체개월수
FROM 고객 A
,(SELECT 고객번호, MAX(변경일자) 변경일자
FROM 고객별연체이력
WHERE 변경일자 <= TO_CHAR(SYSDATE, 'YYYYMMDD')
GROUP BY 고객번호) B, 고객별연체이력 C
WHERE B.고객번호 = A.고객번호
AND C.고객번호 = B.고객번호
AND C.변경일자 = B.변경일자;
--------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 400K| 45M| | 5080 (1)| 00:01:01 |
|* 1 | HASH JOIN | | 400K| 45M| | 5080 (1)| 00:01:01 |
| 2 | TABLE ACCESS FULL | 고객 | 10 | 550 | | 3 (0)| 00:00:01 |
|* 3 | HASH JOIN | | 400K| 24M| 984K| 5072 (1)| 00:01:01 |
| 4 | VIEW | | 32331 | 599K| | 754 (1)| 00:00:10 |
| 5 | SORT GROUP BY | | 32331 | 599K| | 754 (1)| 00:00:10 |
|* 6 | INDEX FAST FULL SCAN| 고객별연체이력| 32331 | 599K| | 751 (1)| 00:00:10 |
| 7 | TABLE ACCESS FULL | 고객별연체이력| 1115K| 47M| | 789 (3)| 00:00:10 |
--------------------------------------------------------------------------------------------------
Rows Row Source Operation
------- ---------------------------------------------------
10 HASH JOIN (cr=6838 pr=6774 pw=0 time=2081110 us)
10 TABLE ACCESS FULL 고객 (cr=3 pr=0 pw=0 time=92 us)
10 HASH JOIN (cr=6835 pr=6774 pw=0 time=2075882 us)
10 VIEW (cr=3367 pr=3325 pw=0 time=2050235 us)
10 SORT GROUP BY (cr=3367 pr=3325 pw=0 time=2050210 us)
11410 INDEX FAST FULL SCAN 고객별연체이력_IDX01 (cr=3367 pr=3325 pw=0 time=22883 us)(object id 52904)
1000000 TABLE ACCESS FULL 고객별연체이력 (cr=3468 pr=3449 pw=0 time=1000057 us)
-- 위의 쿼리는 고객별연체이력 테이블을 두번 Full Scan하는 비효율
SELECT A.고객명, A.거주지역, A.주소, A.연락처
, TO_NUMBER(SUBSTR(연체, 11)) 연체금액
, TO_NUMBER(SUBSTR(연체, 9, 2)) 연체개월수
FROM 고객 A
,(SELECT 고객번호, MAX(변경일자 || LPAD(연체개월수, 2) || 연체금액 ) 연체
FROM 고객별연체이력
WHERE 변경일자 <= TO_CHAR(SYSDATE, 'YYYYMMDD')
GROUP BY 고객번호) B
WHERE B.고객번호 = A.고객번호;
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 32331 | 3031K| 831 (7)| 00:00:10 |
|* 1 | HASH JOIN | | 32331 | 3031K| 831 (7)| 00:00:10 |
| 2 | TABLE ACCESS FULL | 고객 | 10 | 550 | 3 (0)| 00:00:01 |
| 3 | VIEW | | 32331 | 1294K| 827 (7)| 00:00:10 |
| 4 | SORT GROUP BY | | 32331 | 1420K| 827 (7)| 00:00:10 |
|* 5 | TABLE ACCESS FULL| 고객별연| 32331 | 1420K| 824 (7)| 00:00:10 |
--------------------------------------------------------------------------------
Rows Row Source Operation
------- ---------------------------------------------------
10 HASH JOIN (cr=3470 pr=2979 pw=0 time=2130794 us)
10 TABLE ACCESS FULL 고객 (cr=3 pr=0 pw=0 time=102 us)
10 VIEW (cr=3467 pr=2979 pw=0 time=2129922 us)
10 SORT GROUP BY (cr=3467 pr=2979 pw=0 time=2129916 us)
11410 TABLE ACCESS FULL 고객별연체이력 (cr=3467 pr=2979 pw=0 time=34273 us)
-- 분석함수 사용시 편리하고 수행속도에도 전혀 불리 하지 않다.(5장 6절 3항에서 다시)
SELECT A.고객명, A.거주지역, A.주소, A.연락처, B.연체금액, B.연체개월수
FROM 고객 A
,(SELECT 고객번호, 연체금액, 연체개월수, 변경일자
, ROW_NUMBER() OVER (PARTITION BY 고객번호 ORDER BY 변경일자 DESC) NO
FROM 고객별연체이력
WHERE 변경일자 <= TO_CHAR(SYSDATE, 'YYYYMMDD')) B
WHERE B.고객번호 = A.고객번호
AND B.NO = 1;
-- MAX 함수를 이용 헐수도 있지만 위와같이 row_number를 이용하는 것이 더 효과적이다.(5장 6절에서 다시)
SELECT A.고객명, A.거주지역, A.주소, A.연락처, B.연체금액, B.연체개월수
FROM 고객 A
,(SELECT 고객번호, 연체금액, 연체개월수, 변경일자
, MAX(변경일자) OVER (PARTITION BY 고객번호) MAX_DT
FROM 고객별연체이력
WHERE 변경일자 <= TO_CHAR(SYSDATE, 'YYYYMMDD')) B
WHERE B.고객번호 = A.고객번호
AND B.변경일자 = B.MAX_DT;
오라클 고도화 원리와 해법 2 (bysql.net 2011년 1차 스터디)
작성자: 김범석 (darkbeom)
최초작성일: 2011년 4월 3일
본문서는 bysql.net 스터디 결과입니다 .본 문서를 인용하실때는 출처를 밝혀주세요. http://www.bysql.net
문서의 잘못된 점이나 질문사항은 본문서에 댓글로 남겨주세요. ^^
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 20 | 5. 인덱스를 이용한 소트 연산 대체 | 멋진넘 | 2011.06.13 | 3360 |
| 19 | 6. IOT, 클러스터 테이블 활용 | 휘휘 | 2011.02.26 | 2764 |
| 18 | 6. 히스토그램 | 실천하자 | 2011.04.24 | 10955 |
| 17 | 6. 조인 제거 | 멋진넘 | 2011.05.30 | 4605 |
| 16 |
6. Sort Area를 적게 사용하도록 SQL 작성
| 실천하자 | 2011.06.13 | 8878 |
| 15 | 7. 인덱스 스캔 효율 [1] | 휘휘 | 2011.03.08 | 16955 |
| 14 | 7. 비용 | 휘휘 | 2011.05.02 | 6182 |
| 13 | 7. OR-Expansion | 멋진넘 | 2011.05.31 | 8733 |
| 12 | 7. Sort Area 크기 조정 | 실천하자 | 2011.06.13 | 15117 |
| 11 | 8. 인덱스 설계 | 멋진넘 | 2011.03.06 | 8356 |
| 10 | 7. 조인을 내포한 DML 튜닝 | 실천하자 | 2011.04.03 | 7192 |
| 9 | 8. 통계정보 Ⅱ [1] | 멋진넘 | 2011.04.29 | 31578 |
| 8 | 8. 공통 표현식 제거 | darkbeom | 2011.06.06 | 5232 |
| 7 |
9. 비트맵 인덱스
| 실천하자 | 2011.03.05 | 12376 |
| » |
8. 고급 조인 테크닉-1
[1] | darkbeom | 2011.04.03 | 13294 |
| 5 | 9. Outer 조인을 Inner 조인으로 변환 | darkbeom | 2011.06.06 | 7861 |
| 4 |
8. 고급 조인 테크닉-2
| suspace | 2011.04.05 | 7027 |
| 3 | 10. 실체화 뷰 쿼리로 재작성 | suspace | 2011.06.07 | 5540 |
| 2 | 11. 집합 연산을 조인으로 변환 | suspace | 2011.06.07 | 6005 |
| 1 | 12. 기타 쿼리 변환 [3] | 실천하자 | 2011.06.02 | 6658 |
ROLLUP 오라클 8i에서도 잘 됩니다.!! ㅋ (Win2003 Server / Oracle 8i)
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
다음에 접속됨:
Oracle8i Release 8.1.7.0.0 - Production
JServer Release 8.1.7.0.0 - Production
SQL> SELECT DEPTNO, JOB, SUM(SAL)
2 FROM SCOTT.EMP
3 GROUP BY ROLLUP(DEPTNO, JOB);
DEPTNO JOB SUM(SAL)
---------- ------------------ ----------
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
10 8750
20 ANALYST 6000
20 CLERK 1900
20 MANAGER 2975
20 10875
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
30 9400
29025
하면서 CUBE도 같이 적용해봤는데 같이 잘되더라고요~ㅋ
8i 너무 무시하지 않으셔도 될듯...쿨럭~
SQL> SELECT DEPTNO, JOB, SUM(SAL)
2 FROM SCOTT.EMP
3 GROUP BY CUBE(DEPTNO,JOB);
DEPTNO JOB SUM(SAL)
---------- ------------------ ----------
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
10 8750
20 ANALYST 6000
20 CLERK 1900
20 MANAGER 2975
20 10875
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 5600
30 9400
ANALYST 6000
CLERK 4150
MANAGER 8275
PRESIDENT 5000
SALESMAN 5600
29025