4. 단순 B-tree 액세스
2009.12.28 01:17
CHAPTER 4. 단순 B-tree 액세스
b-tree index를 사용하여 단일 테이블을 액세스 하는 비용계산식을 살펴봄
index range scan, index full scan , unique scan 등
기본적인 인덱스 비용 계산식 77 /남송휘
- 인덱스를 이용한 전형적인 액세스 경로
- 인덱스 루트(Root) 블록을 찾아감
- 인덱스 브랜치 레벨을 경유해 리프 블록을 찾아가며 (조건에 부합하는 시작키값이 있는 유일한 블록)
- 리프 블록간 연결고리를 따라 진행하다가 검색조건에 맞는 종료키값을 지나치는 지점에서 멈춤
- 각 인덱스 엔트리에 대해 테이블 블록을 방문할지 여부를 결정
- Wolfgang Breitling 의 기초공식
비용 =
blevel +
ceiling (리프 블록수 * 유효 인덱스 선택도) +
ceiling (클러스터링 팩터 * 유효 테이블 선택도)
- 첫번째: 첫번째 리프 블록을 읽는 비용을 제외한 읽어야 하는 블록의 방문 횟수 (오라클 Balanced B-tree이므로 브랜치 블록의 계층수는 항상 같음
- 두번째: 스캔해야할 리프 블록 개수 ( 유효인덱스 선택도는 10053 트레이스 파일에서 ix_sel_이라고 표시된 엔트리)
- 세번째: 방문해야 할 테이블 블록 수 (유효인덱스 선택도는 10053 트레이스 파일에서 tb_sel이라고 표시된 엔트리)
시작하면서 80 /남송휘
예제 테이블 생성
create table t1
as
select
trunc(dbms_random.value(0,25)) n1,
rpad('x',40) ind_pad,
trunc(dbms_random.value(0,20)) n2,
lpad (rownum,10,'0') small_vc,
rpad('x',200) padding
from all_objects
where
rownum <= 10000
;
create index t1_i1 on t1(n1),ind_pad, n2)
pctfree 91
;
* pctfree
테이블: 해당블록에 더이상의 새로운 로우 삽입을 멈추는 시점(update 대비용)
index: 새로운 로우 삽입을 위한 공간을 예약
예제 테이블과 인덱스에 대한 통계정보
테이블 정보 user_tables
TABLE_NAME BLOCKS NUM_ROWS
-------------------- ---------- ----------
T1 371 10000
1 row selected.
인덱스 정보 user_indexes
NUM_ROWS DIST.._KEYS BLEVEL LEAF_BLOCKS CLUST.._FACT AVG_LEAF_BLKS_PER_KEY AVG_DATA_BLOCKS_PER_KEY
-------- ------------ ------ --------- ------------ --------------------- -----------------------
10000 500 2 1111 9745 2 19
1 row selected.
테이블의 컬럼 정보 user_tab_columns
COLUMN_NAME NUM_NULLS NUM_DISTINCT DENSITY LOW_VALUE HIGH_VALUE
-------------------- ---------- ------------ ---------- ------------------------ ------------------------
IND_PAD 0 1 1 782020202020202020202020 782020202020202020202020
202020202020202020202020 202020202020202020202020
2020202020202020 2020202020202020
N1 0 25 .04 80 C119
N2 0 20 .05 80 C114
3 rows selected.
select
small_vc
from
t1
where
n1 = 2
and ind_pad = rpad('x',40)
and n2 = 3
;
Execution Plan (10g 결과, 9i 도 동일)
----------------------------------------------------------
---------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20 | 1160 | 25 |
| 1 | TABLE ACCESS BY INDEX ROWID| T1 | 20 | 1160 | 25 |
|* 2 | INDEX RANGE SCAN | T1_I1 | 20 | | 5 |
---------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("N1"=2 AND "IND_PAD"='x
' AND "N2"=3)
- 카디널리티: (10000 * 0.04) * 0.05 = 20
- cost: 라인2 중 blevel 2이므로 5 중2는 브랜치 부터 리프까지 가는 비용
- 3은 20개의 rowid를 얻기 위해 스캔해야 할 리프 블록 수
- 선택도란 - 제공된 조건절에 기초해서 옵티마이저가 현재의 데이터 집합에서 선택할 것으로 예상되는 로우 비율
- 선택도의 구분
- 유효 인덱스 선택도
- 유효 테이블 선택도
- 선택도 계산 공식
- 선택도(P and Q) = 선택도(P) * 선택도(Q)
- 선택도(X and Y and Z) = 선택도(X and Y) * 선택도(Z) = 선택도(X) * 선택도(Y) * 선택도(Z)
- Point
- 인덱스 리프 블록들이 정렬된 순서로 모임
- 질문
- 왜 옵티마이저는 결합 인덱스 선택도(1/인덱스 조합의 distinct) 선택하지 않나?
유효 테이블 선택도 84 /이태경
- 테이블 선택도 계산 공식 구분
- 테이블 엑세스 단계의 조건절만 사용하는 경우 ? 개별 선택도의 곱
- 인덱스를 이용한 경우
이때 유효 테이블 선택도라 할 수 있다.
(∵ 옵티마이저가 인덱스를 경유해 테이블을 선택한다면 별도의 테이블 엑세스 조건은 비용에서 유효하지 않다.)
클러스터링 팩터 85 /위충환
? Clustering Facter
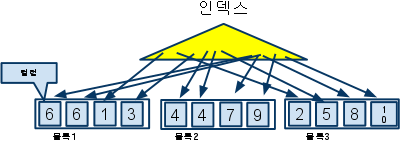
-
인덱스 정렬 상태와 테이블의 무질서하게 흩어진 정도를 비교하는 측정방법
-
다른 블록 점프 시 Counter 변수 1씩 증가로 Counter의 최종 값을 클러스터링 팩터라 함
- 최소 클러스터링 팩터 값 = 테이블 블록 수
- 최대 클러스터링 팩터 값 = 테이블 로우 수
(참고) 좋은 인덱스란 테이블의 블럭 수를 기준으로 클러스터링 팩터 값을 비교하여 높고 낮음에 따라 판단
인덱스 액세스 비용에 대한 종합적인 검토 87 /위충환
|
인덱스를 이용한 엑세스 경로에 대한 비용 공식 |
공식 적용 (계산 된 교재 테스트의 수치 ) |
|
비용 = blevel + ceiling(리프 블록 수 * 유효 인덱스 선택도) + ceiling(클러스터링 팩터 * 유효 테이블 선택도) |
비용 = 2 + ceiling(1,111 * 0.002) + ceiling(9,745 * 0.002) |
-
옵티마이저의 B-Tree 인덱스 사용에 대한 비용 인식
- 일반적으로 blevel은 3이하(대개는 2)이고, 특별한 경우에만 4
- 인덱스는 밀도있게 채워지는 경향
- 인덱스 엔트리는 테이블 로우보다 그 폭이 더 작기 때문에 대개 인덱스 리프 블록이 테이블 블록보다 훨씬 더 많은 엔트리 유지
- 인덱스 내의 리프 블록 수는 테이블 내의 블록 수와 비교할 때 일반적으로 더 작음
☞ 클러스터링 팩터(목표 데이터의 무작위 흩어짐 정도)는 조건절 집합에 의한 테이블 액세스 비용 계산 시 중요한 구성요소
※ 클러스터링 팩터의 실제 데이터 분포상황이 제대로 반영된 비용 계산이 되어야 옵티마이저가 적절한 실행계획 선택 가능성 ↑
알고리즘의 확장 89 /박우창
※6가지 사례에 대하여 구체적으로 비용 계산 방법 제시
1. 범위기반 검색 조건의 비용 계산
2. 범위기반 검색 조건의 비용 계산 - 추가사항
3. 범위기반 검색과 in-list의 비교
4. 일부 인덱스컬럼만을 사용할 때 비용계산
5. Index Full Scan시 비용 계산
6. 인덱스만 읽고 처리하는 쿼리
- (1) 범위기반 검색 조건의 비용 계산
? (문제정의) 범위구간 검색조건에서의 인덱스 비용 계산
? (사례) p90에서 “n2 between 1 and 3” 조건에 대한 검색 비용(btree_cost_02.sql)
실험 테이블구조 t1
|
열이름 |
값 list |
분포 ( 전체 10,000개) |
선택도 |
|
N1 |
1..24 |
각각 약 400개씩 |
1/25 |
|
IND_PAD |
‘x' |
모두 같은값 |
1 |
|
N2 |
0..19 |
각각 약 500개씩 |
1/20 |
|
SMALL_VC |
1..10,000 |
1개씩 |
1/10000 |
|
PADDING |
‘x' |
모두 같은값 |
1 |
? (SQL 문)
create index t1_i1 on t1(n1, ind_pad, n2)
select /*+ index(t1) */ small_vc
from t1
where n1 = 2 and ind_pad = rpad('x',40) and n2 between 1 and 3
? (실행계획)
Execution Plan (9.2.0.6 and 10.1.0.4)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=93 Card=82 Bytes=4756)
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'T1' (Cost=93 Card=82 Bytes=4756)
2 1 INDEX (RANGE SCAN) OF 'T1_I1' (NON-UNIQUE) (Cost=12 Card=82)
? (비용계산)
선택도(n2 between 1 and 3)
= (요청범위)/(전체범위) + 1/NDV + 1/NDV (여기서 NDV=num_distinct)
= (3-1)/(19-0) + 1/20 + 1/20
= 0.205263
유효인덱스선택도 = 1*0.04*0.205263 = 0.0082105
유효테이블선택도 = 1*0.04*0.205263 = 0.0082105
인덱스비용식
= blevel
+ ceiling(리프블록수*유효인덱스선택도)
+ ceiling(클러스터링팩터*유효테이블선택도)
= 2
+ ceiling(1,111*0.0082105) /* = 10 */
+ ceiling(9,745*0.0082105) /* = 81 */
= 93 /* SQL 문 비용과 동일 */
- (2) 범위기반 검색 조건의 비용 계산 - 추가사항
? (문제정의) 범위구간 검색조건에서의 인덱스 비용 계산 -인덱스 앞쪽에 조건사용
? (SQL 문)
create index t1_i1 on t1(n1, ind_pad, n2)
select /*+ index(t1) */ small_vc
from t1
where n1 = between 1 and 3 and ind_pad = rpad('x',40) and n2 = 2
? (실행계획)
Execution Plan (9.2.0.6 and 10.1.0.4)
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=264 Card=82 Bytes=4756)
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'T1' (Cost=264 Card=82 Bytes=4756)
2 1 INDEX (RANGE SCAN) OF 'T1_I1' (NON-UNIQUE) (Cost=184 Card=1633)
? (비용계산)
선택도(n1 between 1 and 3)
= (요청범위)/(전체범위) + 1/NDV + 1/NDV (여기서 NDV=num_distinct)
= (3-1)/(24-0) + 1/25 + 1/25
= 0.163333
유효인덱스선택도 = 1*0.163333*0.05 = 0.0081677
유효테이블선택도 = 1*0.163333*0.05 = 0.0081677인덱스비용식
= blevel
+ ceiling(리프블록수*유효인덱스선택도)
+ ceiling(클러스터링팩터*유효테이블선택도)
= 2
+ ceiling(1,111*0.0081677) /* = 10 */
+ ceiling(9,745*0.0081677) /* = 80 */
= 92 /* SQL 문 비용과 다름 !!! */
? (분석)
계산결과는 92
실행결과는 264(인덱스비용=184, 264-184=80)
인덱스리프블록쪽에 계산 차이(이유 = 인덱스리프블록 카디널리티가 1633이다)
결합인덱스의 앞쪽컬럼에 범위검색을 하면 인덱스리프블록 범위를 줄이지 못한다.
? (비용 재계산)
선택도(n1 between 1 and 3)
= (요청범위)/(전체범위) + 1/NDV + 1/NDV (여기서 NDV=num_distinct)
= (3-1)/(24-0) + 1/25 + 1/25
= 0.163333
유효인덱스선택도 = 0.163333
유효테이블선택도 = 1*0.163333*0.05 = 0.0081677
인덱스비용식
= blevel
+ ceiling(리프블록수*유효인덱스선택도)
+ ceiling(클러스터링팩터*유효테이블선택도)
= 2
+ ceiling(1,111*0.163333) /* = 182 */
+ ceiling(9,745*0.0081677) /* = 80 */
= 264 /* SQL 문 비용과 같음 !!! */
? (결론)
범위기반 조건에 사용되는 컬럼들은 ‘=’조건으로 사용되는 컬럼보다
결합인덱스에서 뒤쪽에 위치해야한다.
- (3) 범위기반 검색과 in-list의 비교
? (문제정의) 8i와 (9i,10g)의 in-list 조건의 선택도 차이가 인덱스 경우 검색시 영향
? (결론)
8i와 (9i,10g)의 in-list 조건의 선택도 차이가 인덱스 경우 검색시 영향을 키친다.
8i가 (9i,10g)보다 카디널리티를 적게 계산하기 때문에 비용이 조금 낮다
8i에서 (9i,10g)로 업그레이드할 때 실행계획이 일부 바뀔수도 있음에 주의
- (4) 일부 인덱스컬럼만을 사용할 때 비용계산
? (문제정의) 결합인덱스 ind(col1,col2,col3,col4)를 가진 테이블에서 일부인덱스에만 조건이 있을 경우 비용 계산
? (SQL 문 모형)
select *
from t1
where col1 = {const} and col2 = {const} and col4 = {const}
/* no predicate on col3 */
? (실험방법) (col1, col2)의 인택스선택도 와 (col1, col2, col4)의 테이블선택로 하여계산
- (5) Index Full Scan시 비용 계산
? (문제정의) 인덱스 리프블록을 따라 검색하는 것이 최적의 접근 경로일때
- order by 정렬작업을 대신할 경우
- 대부분 데이터가 지워져있을 때 데이터블록 보다는 인덱스 이용이 더 빠를때
? (SQL 문)
alter session set "_optimizer_skip_scan_enabled"=false;
select /*+ index(t1) */ small_vc
from t1
where n2 = 2
order by n1;
? (실행계획)
Execution Plan
----------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes| Cost |
----------------------------------------------------------------
| 0 | SELECT STATEMENT | | 500 | 8500| 1601 |
| 1 | TABLE ACCESS BY INDEX ROWID| T1 | 500 | 8500| 1601 |
|* 2 | INDEX FULL SCAN | T1_I1 | 500 | | 1113 |
----------------------------------------------------------------
? (비용계산)
유효인덱스선택도 = 1
유효테이블선택도 = 0.02( n2=2 조건)
인덱스비용식
= blevel
+ ceiling(리프블록수*유효인덱스선택도)
+ ceiling(클러스터링팩터*유효테이블선택도)
= 2
+ ceiling(1,111*1) /* = 1,111 */
+ ceiling(9,745*0.05) /* = 488 */
= 1601 /* SQL 문 비용과 같음 */? (참고) 위 예제를 index를 경유하지 않고 실행하면 비용 = 39(full scan)+7(정렬)
- (6) 인덱스만 읽고 처리하는 쿼리
? (문제정의) 인덱스만 읽고 처리하는 경우 테이블 검색 비용은 없다.
? (SQL 문)
alter session set "_optimizer_skip_scan_enabled"=false;
select /*+ index(t1) */ n2
from t1
where n1 between 6 and 9
order by n1;
? (실행계획)
Execution Plan
---------------------------------------------------------
| Id | Operation | Name | Rows | Bytes| Cost |
---------------------------------------------------------
| 0 | SELECT STATEMENT | | 2050 | 12300| 230 |
|* 1 | INDEX RANGE SCAN | T1_I1 | 2050 | 12300| 230 |
---------------------------------------------------------
? (비용계산)
선택도(n1 between 6 and 9)
= (요청범위)/(전체범위) + 1/NDV + 1/NDV (여기서 NDV=num_distinct)
= (9-6)/(24-0) + 1/25 + 1/25
= 0.205
유효인덱스선택도 = 0.205
유효테이블선택도 = ?
- 인덱스비용식
= blevel
+ ceiling(리프블록수*유효인덱스선택도)
+ ceiling(클러스터링팩터*유효테이블선택도)
= 2
+ ceiling(1,111*0.205) /* = 227.755 */
+ 0 /* = 0 */
= 230 /* SQL 문 비용과 같음 */
세 가지 선택도 98/ 이창헌
select /*+ index(t1) */
small_vc
from t1
where n1 between 1 and 3
and ind_pad = rpad('x',40)
and n2 = 2
and small_vc = lpad(100,10);
--------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=264 Card=1 Bytes=58)
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'T1' (TABLE) (Cost=264 Card=1 Bytes=58)
2 1 INDEX (RANGE SCAN) OF 'T1_I1' (INDEX) (Cost=184 Card=1633)
'범위 기반 검색조건에 and small_vc = lpad(100,10);부분 추가' 쿼리에서 비용은 달라지지 않았지만 카디널리티는 82->1
실행 시 단계별 작동원리
1. between 1 and 3범위에 해당하는 모든 인덱스 리프 블록을 체크(유효 인덱스 선택도)
선택도 n1 = 0.1633333
카디널리티 : round( 0.1633333 * user_tables.num_rows(10,000)) = 1,633
1.633 = 실행계획의 인덱스 라인에서 검사될 로우 수가 아니라 해당 라인에서 통과될 것으로 예상되는 로우 수
2. 세 개의 인덱스 조건걸을 모두 통과하는 인덱스 엔트리에 대해 테이블 로우를 체크(유효 테이블 선택도)
선택도 (n1, ind_pad, n2) = 0.163333 *1 * 0.05
카디널리티 : round( 0.0081667 * user_tables.num_rows(10,000)) = 82 <= 8i에서는 표시됨
3. 네 번째 조건절을 통과하는 로우를 최종적으로 리턴
최종 테이블 선택도( n1, ind_pad, n2, small_vc ) = 0.163333 *1 * 0.05 * 0.0001
카디널리티 : round( 0.0000081667 * user_tables.num_rows(10,000)) = 0
결과치가 0 이어야 하는 상황에서 1로 바꿔는 사례 = 9i and 10g round()함수를 사용함.
10g와 관련된 이슈
user_tables 또는 user_indexes에 저장된 num_rows값을 사용하는지 여부(hack_stats.sql호출해서 num_rows값을 일시적으로 변경함)
- 8i or 9i에서는 카디널리티 변경 없음
- 10g 카디널리티 변경 됨
10,000->11,000(num_rows값) => 1,633->1,797(카디널리티)
184->12(인덱스 라인의 비용) => 1,633-> 82(카디널리티) = 실행계획 전체에 영향을 미침
update t1
set
n1 = null,
ind_pad = null,
n2 = null
where
rownum <= 100(인덱스에서 지워지도록 한다.)
작업 후 아래 쿼리 다시 테스트
select /*+ index(t1) */
small_vc
from t1
where n1 between 1 and 3
and ind_pad = rpad('x',40)
and n2 = 2
and small_vc = lpad(100,10);
8i, 9i = 비용과 카디널리티에 전혀 영향 없음.
10g = 비용과 카디널리티에 영향을 줌
cf) btree_cost_02a.sql
select
/*+
index(t1)
*/
small_vc
from
t1
where
n1 between 1 and 3
and ind_pad = rpad('x',40)
and n2 = 2
and small_vc = lpad(100,10)
;
실행
NULL이 없는 T1 테이블
9.2.0.4
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=264 Card=1 Bytes=58)
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'T1' (Cost=264 Card=1 Bytes=58)
2 1 INDEX (RANGE SCAN) OF 'T1_I1' (NON-UNIQUE) (Cost=184 Card=1633)
10.2.0.1
---------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 58 | 264 |
|* 1 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 58 | 264 |
|* 2 | INDEX RANGE SCAN | T1_I1 | 82 | | 184 |
---------------------------------------------------------------------
NULL 100개 UPDATE
update t1
set
n1 = null, ind_pad = null, n2 = null
where
rownum <= 100
;
테이블
TABLE_NAME BLOCKS NUM_ROWS
------------- ---------- ----------
T1 371 10000
1 row selected.
인덱스
NUM_ROWS DISTINCT_KEYS BLVL LEAF_BLKS CLST_FACTOR A_LEAF_BLOCKS_PER_KEY A_DATA_BLKS_PER_KEY
---------- ------------- ---- ----------- ----------------- ----------------------- -------------------
9900 500 2 1111 9648 2 19
1 row selected.
컬럼
COLUMN_NAME NUM_NULLS NUM_DISTINCT DENSITY LOW_VALUE HIGH_VALUE
-------------------- ---------- ------------ ---------- ------------------------ ------------------------
IND_PAD 100 1 1 782020202020202020202020 782020202020202020202020
202020202020202020202020 202020202020202020202020
2020202020202020 2020202020202020
N1 100 25 .04 80 C119
N2 100 20 .05 80 C114
3 rows selected.
9.2.0.4
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=262 Card=1 Bytes=58)
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'T1' (Cost=262 Card=1 Bytes=58)
2 1 INDEX (RANGE SCAN) OF 'T1_I1' (NON-UNIQUE) (Cost=184 Card=1633)
10.2.0.1
---------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 58 | 262 |
|* 1 | TABLE ACCESS BY INDEX ROWID| T1 | 1 | 58 | 262 |
|* 2 | INDEX RANGE SCAN | T1_I1 | 79 | | 184 |
---------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("SMALL_VC"=' 100')
2 - access("N1">=1 AND "IND_PAD"='x
' AND "N2"=2 AND "N1"<=3)
filter("IND_PAD"='x ' AND
"N2"=2)
CPU costing 103/ 이창헌
- 9i부터 오라클 사용자는 시스템 통계를 활성화할 수 있는 옵션을 갖게 됨.
- CPU costing의 중요한 특징은 다중 블록(multiblcok)i/o와 cpu사용률에 대한 시간 구성요소에 있다. 그러나 전형적인 인덱스 기반 액세스는 단일 블록(single-block)i/o방식으로 수행되기 때문에 시간 구성요소와는 관련이 적다.
- CPU costing을 활성화(_optimizer_cost_model 기본값 choose)했을 때 나타나는 가장 큰 변화 => 테이블 스캔 비용
alter session set "_optimizer_cost_model" = cpu;
begin
dbms_stats.set_system_stats('MBRC',8);
dbms_stats.set_system_stats('MREADTIM',20); -- millisec
dbms_stats.set_system_stats('SREADTIM',10); -- millisec
dbms_stats.set_system_stats('CPUSPEED',350); -- "MHz"
end;
/
테스트 케이스
원래 비용
시스템 통계 활성화 시 9I/10G
index()힌트 사용
68
69(68)
full()힌트 사용
58
96(95)
힌트가 없을 때 익세스 경로
full tablescan
index iterator
select
/*+ index(t1) cpu_costing */
small_vc
from
t1
where
ind_pad = rpad('x',40)
and n1 = 2
and n2 in (5,6,7)
9.2.0.4
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=69 Card=60 Bytes=3480)
1 0 INLIST ITERATOR
2 1 TABLE ACCESS (BY INDEX ROWID) OF 'T1' (Cost=69 Card=60 Bytes=3480)
3 2 INDEX (RANGE SCAN) OF 'T1_I1' (NON-UNIQUE) (Cost=10 Card=60)
10.2.0.1
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 60 | 3480 | 70 (0)| 00:00:01 |
| 1 | INLIST ITERATOR | | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 60 | 3480 | 70 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | T1_I1 | 60 | | 11 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
select
/*+ index(t1) nocpu_costing */
small_vc
from
t1
where
ind_pad = rpad('x',40)
and n1 = 2
and n2 in (5,6,7)
;
9.2.0.4
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=68 Card=60 Bytes=3480)
1 0 INLIST ITERATOR
2 1 TABLE ACCESS (BY INDEX ROWID) OF 'T1' (Cost=68 Card=60 Bytes=3480)
3 2 INDEX (RANGE SCAN) OF 'T1_I1' (NON-UNIQUE) (Cost=9 Card=60)
10.2.0.1
----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 60 | 3480 | 70 |
| 1 | INLIST ITERATOR | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID| T1 | 60 | 3480 | 70 |
|* 3 | INDEX RANGE SCAN | T1_I1 | 60 | | 11 |
----------------------------------------------------------------------
select
/*+ full(t1) cpu_costing */
small_vc
from
t1
where
ind_pad = rpad('x',40)
and n1 = 2
and n2 in (5,6,7)
;
9.2.0.4
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=96 Card=60 Bytes=3480)
1 0 TABLE ACCESS (FULL) OF 'T1' (Cost=96 Card=60 Bytes=3480)
10.2.0.1
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 60 | 3480 | 95 (2)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| T1 | 60 | 3480 | 95 (2)| 00:00:01 |
--------------------------------------------------------------------------
select
/*+ full(t1) nocpu_costing */
small_vc
from
t1
where
ind_pad = rpad('x',40)
and n1 = 2
and n2 in (5,6,7)
;
9.2.0.4
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=94 Card=60 Bytes=3480)
1 0 TABLE ACCESS (FULL) OF 'T1' (Cost=94 Card=60 Bytes=3480)
10.2.0.1
----------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost |
----------------------------------------------------------
| 0 | SELECT STATEMENT | | 60 | 3480 | 37 |
|* 1 | TABLE ACCESS FULL| T1 | 60 | 3480 | 37 |
----------------------------------------------------------
끝으로 106 / 남송휘
- 현재 일어나는 일을 정확히 알아냈다고 믿을 만한 근사치에 아주 가까이 왔다고 쉽게 단정하지 말아야 함
- 오라클 버젼에 다라 다양성이 존재 (round(), ceil() 의 예)
- ex)
- Nonunique 인덱스의 경우 기본공식에서 1을 뺌, 제약에 deferrable옵션을 사용할때 조정이 일어나지 않음
- 인덱스 blevel이 1인경우 blevel을 무시하지만 루트블록 분할이 발생하면 액세스 경로가 바꿀수 있음
요약 107 / 남송휘
- B-tree 인덱스를 사용할 때의 비용 구성 세가지
- 인덱스 깊이 :blevel 에 기초해서 계산
- 스캔해야 할 인덱스 리프 블록수: leaf_blocks에 기초해서 게산
- 테이블 블록 방문 횟수: clustering_factor 에 기초해서 계산
- 인덱스 클러스터링 팩터는 옵타미아저가 해당 인덱스를 선호하게 하는 주요 지표
- WHERE 조건절에서 자주 빠지거나 범위 기반검색조건으로 사용된다면 인덱스 컬럼 구성시 뒤쪽으로 옮겨져야 함
본자료는 durinuri.com 의 비용기반의 오라클원리 스터디 결과로 만들어진자료입니다.
자료를 사용하실경우 출처를 밝혀주시기바립니다. ^^
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 17 | 진행기록 | 운영자 | 2010.04.10 | 13098 |
| 16 |
Front Page
| 운영자 | 2009.12.20 | 134794 |
| 15 | 비용기반의 오라클 원리 첫 모임 [4] | 운영자 | 2010.01.03 | 10261 |
| 14 | 1. 비용(COST)이란? | ZoneWorker2 | 2009.12.28 | 22696 |
| 13 | 2. 테이블 스캔 | balto | 2009.12.28 | 17861 |
| 12 | 3. 단일 테이블 선택도 | ZoneWorker2 | 2009.12.28 | 13089 |
| » |
4. 단순 B-tree 액세스
| 휘휘 | 2009.12.28 | 13601 |
| 10 | 5. 클러스터링 팩터 | balto | 2009.12.28 | 19476 |
| 9 | 6. 선택도 이슈 | ZoneWorker2 | 2009.12.28 | 12328 |
| 8 | 7. 히스토그램 | ZoneWorker2 | 2009.12.28 | 14890 |
| 7 | 8. 비트맵 인덱스 | ZoneWorker2 | 2009.12.28 | 12720 |
| 6 | 9. 쿼리 변환 | 헌쓰 | 2009.12.28 | 19900 |
| 5 | 10. 조인 카디널리티 | 휘휘 | 2009.12.28 | 13649 |
| 4 | 11. NL(Nested Loops) 조인 | 휘휘 | 2009.12.28 | 16633 |
| 3 |
12. 해시 조인
| 헌쓰 | 2009.12.28 | 21703 |
| 2 | 13. 정렬과 머지 조인 | 실천하자 | 2009.12.28 | 21545 |
| 1 |
14. 10053 트레이스 파일
| 휘휘 | 2009.12.28 | 14968 |