1. Nested Loops 조인
2011.03.22 19:50
01 Nested Loops 조인
(1)기본 메커니즘
-중첩 루프문(Nested lool) 수행 구조 이해
Begin
For outer in (select deptno, empno, rpad(ename, 10) ename from emp)
Loop -- outer 루프
For inner in (select dname from dept where deptno = outer.deptno)
Loop ? inner 루프
Dbms_ouput.put_line(outer.empno || ‘ : ‘ || outer.ename || ‘ : ‘ || inner.dname);
End loop;
End loop;
End;
(2)힌트를 이용해서 NL 조인을 제어하는 방법
select /*+ ordered use_nl(e) */ *
from dept d,emp e
where e.deptno=d.deptno;
----------------------------------------------------------------------
Rows Row Source Operation
------- ---------------------------------------------------
0 STATEMENT
14 NESTED LOOPS (cr=39 pr=0 pw=0 time=172 us)
4 TABLE ACCESS FULL DEPT (cr=9 pr=0 pw=0 time=114 us)
14 TABLE ACCESS FULL EMP (cr=30 pr=0 pw=0 time=331 us)
----------------------------------------------------------------------
-ordered : from 절에 기술된 순서래도 조인
-use_nl : NL방식으로 조인
- 두 힌트를 써서 dept table(outer table)을 기준으로 emp table(inner table)과 조인할 때 NL방식조인
*세 개이상 조인시
-orderd HINT
select /*+ ordered use_nl(E) use_nl(J) use_nl(h) */ *
from departments d,employees e,jobs j,job_history h
where d.department_id=e.department_id
and e.job_id=j.job_id
and j.job_id=h.job_id;
-------------------------------------------------------------------------------------------
Rows Row Source Operation
------- ---------------------------------------------------
0 STATEMENT
84 TABLE ACCESS BY INDEX ROWID JOB_HISTORY (cr=188 pr=0 pw=0 time=377 us)
191 NESTED LOOPS (cr=178 pr=0 pw=0 time=30226 us)
106 NESTED LOOPS (cr=159 pr=0 pw=0 time=9432 us)
106 NESTED LOOPS (cr=43 pr=0 pw=0 time=6014 us)
27 TABLE ACCESS FULL DEPARTMENTS (cr=10 pr=0 pw=0 time=385 us)
106 TABLE ACCESS BY INDEX ROWID EMPLOYEES (cr=33 pr=0 pw=0 time=1116 us)
106 INDEX RANGE SCAN EMP_DEPARTMENT_IX (cr=13 pr=0 pw=0 time=501 us)(Object ID 10457)
106 TABLE ACCESS BY INDEX ROWID JOBS (cr=116 pr=0 pw=0 time=2152 us)
106 INDEX UNIQUE SCAN JOB_ID_PK (cr=10 pr=0 pw=0 time=832 us)(Object ID 10450)
84 INDEX RANGE SCAN JHIST_JOB_IX (cr=19 pr=0 pw=0 time=965 us)(Object ID 10462)
-------------------------------------------------------------------------------------------
-leading HINT(10g부터 from 절을 바꾸지 않고 순서를 제어할 수 있음)
select /*+ leading(e,j,h,d) use_nl(j) use_nl(h) use_nl(d) */ *
from departments d,employees e,jobs j,job_history h
where d.department_id=e.department_id
and e.job_id=j.job_id
and j.job_id=h.job_id;
-------------------------------------------------------------------------------------------
Rows Row Source Operation
------- ---------------------------------------------------
0 STATEMENT
84 NESTED LOOPS (cr=308 pr=0 pw=0 time=510 us)
85 NESTED LOOPS (cr=214 pr=0 pw=0 time=9293 us)
107 NESTED LOOPS (cr=134 pr=0 pw=0 time=3656 us)
107 TABLE ACCESS FULL EMPLOYEES (cr=16 pr=0 pw=0 time=583 us)
107 TABLE ACCESS BY INDEX ROWID JOBS (cr=118 pr=0 pw=0 time=2175 us)
107 INDEX UNIQUE SCAN JOB_ID_PK (cr=11 pr=0 pw=0 time=899 us)(Object ID 10450)
85 TABLE ACCESS BY INDEX ROWID JOB_HISTORY (cr=80 pr=0 pw=0 time=3121 us)
85 INDEX RANGE SCAN JHIST_JOB_IX (cr=16 pr=0 pw=0 time=1924 us)(Object ID 10462)
84 TABLE ACCESS BY INDEX ROWID DEPARTMENTS (cr=94 pr=0 pw=0 time=1601 us)
84 INDEX UNIQUE SCAN DEPT_ID_PK (cr=10 pr=0 pw=0 time=646 us)(Object ID 10447)
-------------------------------------------------------------------------------------------
(3)NL 조인 수행 과정 분석
select /*+ ordered use_nl(e) */ e.empno,e.enmae,d.dname,e.job,e.sal
from dept d,emp e
where e.deptno=d.deptno
and d.loc='SEOUL'
and d.gb='2'
and e.sal >=1500
order by sal desc;
---------- index ----------------
pk_dept : dept.deptno
dept_loc_idx : dept.loc
pk_emp : emp.empno
emp_deptnpo_idx : emp.deptno
emp_sal_idx : emp.sal
---------------------------------------
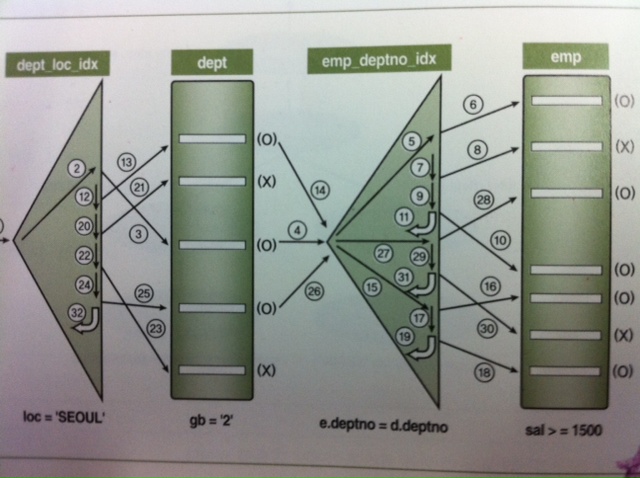
1)dept.loc='SEOUL' 조건 만족(dept_loc_idx 범위스캔)
2)dept_loc_idx인덱스에서 읽은 deptno 값을 가지고 dept 테이블을 액세스해 dept.gb='2' 필터조건
3)dept 테이블에서 읽은 deptno 값을 가지고 조인 조건을 만족하는 emp.deptno_idx를 범위스캔
4)emp.deptno_idx에서 읽은 rowid를 가지고 emp 테이블에 액세스해 sal>=1500 필터조건
5)1~4과정을 통과한 레코드를 sal기준으로 내리차순 정렬
<부하 지점>
*dept_loc_idx의 인덱스 스캔량에 따라 전체 일량이 좌우 됨(gb='2' 필터링이 높다면 인덱스 추가)
*emp_deptno_idx부분에서 outer 테이블인 dept를 읽고나서 조인 액세스가 얼만큼 발생하느냐에 결정
*emp_deptno_idx를 읽고 나서 emp 테이블을 액세스하는 부분(sal>=1500 필터링이 높다면 인덱스 추가)
-NL 조인 매커니즘을 따라 각 단계의 수행 일량을 분석해 과도한 randowm 액세스가 발생하는 지점을 파악 후
조언 순서를 변경해 randowm 액세스 발생량을 줄이거나 인덱스 컬럼구성 변경 고려-
(4)NL조인의 특징
1.Randowm 액세스 위주의 조인 방식(오라클은 블록단위로 I/O 수행)
-대량의 데이터를 조인할 때 매우 비효율적
2.조인을 한 레코드씩 순차적으로 진행
-대용량이라도 부분범위처리가 가능하다면 빠른 응답 속도 기대
-순차적으로 진행하는 특징 때문에 먼저 액세스되는 테이블의 처리범위에 의해 전체 일량 결정
3.인덱스 구성 전략이 중요
-조인 컬럼에 인덱스가 있고 없고...있다면 컬럼 구성에 따라 조인 효율이 달라짐
(5)NL 조인 튜닝 실습
------------ index ------------------
pk_jobs : jops.jop_id
jobs_max_sal_ix : jobs.max_salary
pk_employees : employees.employee_id
emp_job_ix : employees.job_id
emp_hiredate_ix : employees.hire_date
-----------------------------------------------
select /*+ ordered use_nl(e) index(j) index(e) */
j.job_title,e.first_name,e.last_name,e.hire_date,e.salary,e.email,e.phone_number
from jobs s, employees e
where e.job_id=j.job_id ------ 3)
and j.max_salary >= 1500 ----- 1)
and j.job_type='A' ------ 2)
and e.hire_date>=to_date('19960101','yyyymmdd') -------4)
?----------------------------------------------------------------------------------------------------
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.010 0.012 0 0 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 2 0.000 0.007 1 9 0 5
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 4 0.00 0.01 1 9 0 5
1.블록 I/O가 9개 발생.
-----------------------------------------------------------
Rows Row Source Operation
------- ---------------------------------------------------
5 NESTED LOOPS
3 TABLE ACCESS BY INDEX ROWID JOBS
5 INDEX RANGE SCAN JOBS_MAX_SAL_IX
5 TABLE ACCESS BY INDEX ROWID EMPLOYEES
8 INDEX RANGE SCAN EMP_JOB_IX
---------------------------------------------------------------------------------------------------------
2.JOBS_MAX_SAL_IX 를 스캔하고 JOB 테이블에 액세스한 획수가 278인 반면 FITEERING 된 결과는 3건
-----------------------------------------------------------
Rows Row Source Operation
------- ---------------------------------------------------
5 NESTED LOOPS
3 TABLE ACCESS BY INDEX ROWID JOBS
278 INDEX RANGE SCAN JOBS_MAX_SAL_IX
5 TABLE ACCESS BY INDEX ROWID EMPLOYEES
8 INDEX RANGE SCAN EMP_JOB_IX
-----------------------------------------------------------
*테이블을 액세스한 후에 필터링되는 비율이 높다면 인덱스에 필터 조건 컬럼을 추가(JOB_TYPE='A' 조건)
3.row에 대한 비효율적인 액세스는 없지만 인덱스 스캔단계에서의 블록 비효율
-----------------------------------------------------------
Rows Row Source Operation
------- ---------------------------------------------------
5 NESTED LOOPS (cr=1015 ----
3 TABLE ACCESS BY INDEX ROWID JOBS (cr=1003 ---
3 INDEX RANGE SCAN JOBS_MAX_SAL_IX (cr=1000 ---
5 TABLE ACCESS BY INDEX ROWID EMPLOYEES (cr=12 ----
8 INDEX RANGE SCAN EMP_JOB_IX (cr=8 -----
-----------------------------------------------------------
<부하원인>
JOBS_MAX_SAL_IX 가 [max_salary+job_type] 이고 선두컬럼이 부등호 조건임
max_salary>=1500의 레코드가 엄청 많다면 많은 양의 인덱스 블록을 스캔하고 필터링
3건을 리턴하기 위해 인덱스 블록을 1000개 읽은 것을 확인
<해결책>
JOBS_MAX_SAL_IX의 순서를 [job_type+max_salary]로 구성
4.employees와의 조인 액세스 부하
-----------------------------------------------------------
Rows Row Source Operation
------- ---------------------------------------------------
5 NESTED LOOPS (cr=1015 ----
1278 TABLE ACCESS BY INDEX ROWID JOBS (cr=166 ---
1278 INDEX RANGE SCAN JOBS_MAX_SAL_IX (cr=4 ---
5 TABLE ACCESS BY INDEX ROWID EMPLOYEES (cr=2566 ----
8 INDEX RANGE SCAN EMP_JOB_IX (cr=2558 -----
-----------------------------------------------------------
<부하원인>
job 테이블에 대해 일량은 많지만 비효율은 없음
employees 와의 조인 횟수가 1278번이지만 조인에 성공한 횟수는 5건
<해결책>
조인순서를 바꾸는 것을 고려(hire_data 조건절이 부합되는 레코드가 별로 없을 경우)
(6)테이블 Prefetch
-오라클 9i부터 nl 조인시 index rowid 에의한 inner table 액세스가 nested loops 위쪽으로 표시
테이블 액세스 단계에서 prefetch기능이 적용
-인덱스를 경유해 테이블 레코들를 액세스하는 도중 디스크에서 캐시로 블록을 적재해야 될 경우
읽을 가능성이 큰 블록들을 캐시에 미리 적재해 두는 기능
-_table_lookup_prefetch_size=0 으로 제어
----------------------------------------------------------------------
Rows Row Source Operation
------- ---------------------------------------------------
0 STATEMENT
14 NESTED LOOPS (cr=39 pr=0 pw=0 time=172 us)
4 TABLE ACCESS FULL DEPT (cr=9 pr=0 pw=0 time=114 us)
14 TABLE ACCESS (BY INDEX ROWID) OF 'EMP' (TABLE) (cr=30 pr=0 pw=0 time=331 us)
14 INDEX RANGE SCAN EMP_DEPT_IX (cr=13 pr=0 pw=0 time=501 us)(Object ID 10457)
----------------------------------------------------------------------
----------------------------------------------------------------------
Rows Row Source Operation
------- ---------------------------------------------------
0 STATEMENT
14 TABLE ACCESS (BY INDEX ROWID) OF 'EMP' (TABLE) (cr=30 pr=0 pw=0 time=331 us)
14 NESTED LOOPS (cr=39 pr=0 pw=0 time=172 us)
4 TABLE ACCESS FULL DEPT (cr=9 pr=0 pw=0 time=114 us)
14 INDEX RANGE SCAN EMP_DEPT_IX (cr=13 pr=0 pw=0 time=501 us)(Object ID 10457)
----------------------------------------------------------------------
<TABLE PREFETCH 나타나는 경우>
1. inner쪽 non-unique인덱스를 range scan할 경우
2. inner쪽 unique 인덱스를 non-unique조건(인덱스 구성 컬럼이 '=' 조건이 아닐때)range scan할 경우
3. inner쪽 unique 인덱스를 unique조건(인덱스 구성 컬럼이 '=' 조건)을 range scan 할 경우 나타날 수 있다.
unique scan일 때는 안 나타날 수 있음-정확한 규칙은 찾지 못함
(7)배치 I/O (공식 명칭은 아님)-가설
-inner 쪽 index만으로 조인을 하고 테이블과의 조인은 나중에 일괄처리하는 매커니즘
-outer 테이블로부터 액세스되는 inner 테이블 블록에 대한 disk I/O 횟수를 줄이기 위해
table prefetch에 이어 추가 도입
-nlj_batching 사용. nlj_prefetch(table prefetch 로 전환)
<실행순서>
1.드라이빙 테이블에서 일정량의 레코드를 읽어 inner 쪽 index와 조인하면서 중간 결과집합을 만듬
2.중간 결과집합이 일정량 쌓이면 inner 테이블 레코드를 액세스.
테이블 블록을 버퍼에서 쌓으면 최종 결과 집합, 못 찾으면 중간집합
3.2번 과정에서 남겨진 중간 집합을 inner 쪽 테이블 블록을 디스크에서 읽음
4.버퍼에 올라온 테이블 레코드를 읽어 최종 결과 집합에 담는다
5.모든 레코드 처리하거나 fetch call 을 중단할 때까지 1~4 반복
(8)버퍼 pinging 효과
<8i 버퍼 pinning 효과>
1.inner 쪽 인덱스를 통해 액세스되는 테이블 블록이 계속 같은 블록을 가리키면 논리 I/O는 발생하지 않는다
2.하나의 outer 레코드에 대한 inner 쪽과의 조인을 마치고 다른 레코드를 읽기 위해 outer 쪽으로
돌아오는 수간 pin을 해제
<9i 버퍼 pinning 효과>
1.inner쪽 index 루트 블록에 대한 buffer pinning효과(두번째 액세스 되는 순간)
2.inner쪽을 한 번 액세스할 때마다 non-unique인덱스로 여러개의 테이블 레코드를 읽을 때
<10g 버퍼 pinning 효과>
-inner 쪽 테이블을 index range scan을 거쳐 NL조인 위쪽에서 액세스할 때는 하나의 outer 레코드에 대한 inner쪽과의
조인을 마치고 outer 쪽으로 돌아오더라고 테이블 블록에 대한 pinning상태는 유지한다
<TEST1>
-dept:4건(pk 설정)
emp:140만건
select /*+ ordered use_nl(d) */ count(e.ename), count(d.dname)
from t_emp e, dept d
where d.deptno = e.deptno
-------------------------------------------------------------------------------------------
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.050 0.101 0 78 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 2 31.640 38.674 8845 1409213 0 1
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 4 31.690 38.776 8845 1409291 0 1
Misses in library cache during parse: 1
Optimizer goal: ALL_ROWS
Parsing user: HR (ID=34)
Rows Row Source Operation
------- ---------------------------------------------------
0 STATEMENT
1 SORT AGGREGATE (cr=1409213 pr=8845 pw=0 time=38674389 us)
1400000 NESTED LOOPS (cr=1409213 pr=8845 pw=0 time=49030749 us)
1400000 TABLE ACCESS FULL T_EMP (cr=9211 pr=8845 pw=0 time=21030654 us)
1400000 TABLE ACCESS BY INDEX ROWID DEPT (cr=1400002 pr=0 pw=0 time=24163811 us)
1400000 INDEX UNIQUE SCAN DEPT_PK (cr=2 pr=0 pw=0 time=9583422 us)(Object ID 10554)
-------------------------------------------------------------------------------------------
*inner 쪽 index(dept_pk)로 140만번 액세스가 일어났지만 논리적인 블록 I/O는 2번
*10g까지는 루트블록만 pinning대상(test 환경의 dept는 작은 테이블이라 인덱스 루트블록이 곧 리프블록)
*테이블 블록은 inner 쪽을 액세스할 때마다 한건씩만 읽고 outer 쪽으로 돌아가므로 pinning은 일어나지 않음
<TEST2>
-unique index 를 range scan하도록 조절
-------------------------------------------------------------------------------------------
select /*+ ordered use_nl(d) */ count(e.ename), count(d.dname)
from t_emp e, dept d
where d.deptno between e.deptno and e.deptno + 1
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.040 0.045 0 78 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 2 29.280 29.226 0 9214 0 1
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 4 29.320 29.272 0 9292 0 1
Misses in library cache during parse: 1
Optimizer goal: ALL_ROWS
Parsing user: HR (ID=34)
Rows Row Source Operation
------- ---------------------------------------------------
0 STATEMENT
1 SORT AGGREGATE (cr=9214 pr=0 pw=0 time=29226350 us)
1400000 TABLE ACCESS BY INDEX ROWID DEPT (cr=9214 pr=0 pw=0 time=35000227 us)
2800001 NESTED LOOPS (cr=9213 pr=0 pw=0 time=8455667 us)
1400000 TABLE ACCESS FULL T_EMP (cr=9211 pr=0 pw=0 time=4200081 us)
1400000 INDEX RANGE SCAN DEPT_PK (cr=2 pr=0 pw=0 time=13438959 us)(Object ID 10554)
-------------------------------------------------------------------------------------------
*unique index이지만 range scan으로 테이블 엑세스가 NL 위쪽에 위치하면 버퍼 pinning상태가 유지
블록 I/O는 1 (9214-9213)
<11g 버퍼 pinning 효과>
-user rowid로 테이블 액세스할 때도 버퍼 pinning
-NL조인에서 inner쪽 루트 아래 인덱스 블록들도 buffer pinning
<TEST1>
-table prefetch 방식으로 액세스하더라도 인덱스 블록에 대한 buffer pinning효과는 똑같이 나타남
-------------------------------------------------------------------------------------------
select /*+ ordered use_nl_with_index(d) nlj_prefetch(d) */
count(e.ename), count(d.dname)
from t_emp e, t_dept d
where d.no = e.no
and d.deptno = e.deptno
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.080 0.078 0 87 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 2 0.320 0.625 0 14167 0 1
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 4 0.400 0.703 0 14254 0 1
Misses in library cache during parse: 1
Optimizer goal: ALL_ROWS
Parsing user: SCOTT (ID=36)
Rows Row Source Operation
------- ---------------------------------------------------
0 STATEMENT
1 SORT AGGREGATE (cr=14167 pr=0 pw=0 time=0 us)
14000 TABLE ACCESS BY INDEX ROWID T_DEPT (cr=14167 pr=0 pw=0 time=369828 us cost=1 size=35 card=1)
28001 NESTED LOOPS (cr=167 pr=0 pw=0 time=114684 us cost=3150 size=272000 card=4000)
14000 TABLE ACCESS FULL T_EMP (cr=95 pr=0 pw=0 time=49505 us cost=30 size=488334 card=14798)
14000 INDEX UNIQUE SCAN T_DEPT_PK (cr=72 pr=0 pw=0 time=0 us cost=0 size=0 card=1)(Object ID 16136)
-------------------------------------------------------------------------------------------
<TEST2>
-배치 I/O포맷 test
-드라이빙 테이블을 무작위로 정렬한 결과 인덱스 블록에 대한 buffer pinning 효과가 사라짐(같은 값으로 반복액세스가 힘듬)
-------------------------------------------------------------------------------------------
select /*+ ordered use_nl_with_index(d) nlj_batching(d) */
count(e.ename), count(d.dname)
from t_emp e, t_dept d
where d.no = e.no
and d.deptno = e.deptno
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.100 0.104 0 87 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 2 0.350 0.355 7 28098 0 1
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 4 0.450 0.459 7 28185 0 1
Misses in library cache during parse: 1
Optimizer goal: ALL_ROWS
Parsing user: SCOTT (ID=36)
Rows Row Source Operation
------- ---------------------------------------------------
0 STATEMENT
1 SORT AGGREGATE (cr=28098 pr=7 pw=0 time=0 us)
14000 NESTED LOOPS (cr=28098 pr=7 pw=0 time=398080 us)
14000 NESTED LOOPS (cr=14098 pr=7 pw=0 time=231365 us cost=3149 size=272000 card=4000)
14000 TABLE ACCESS FULL T_EMP (cr=95 pr=7 pw=0 time=21634 us cost=30 size=488730 card=14810)
14000 INDEX UNIQUE SCAN T_DEPT_PK (cr=14003 pr=0 pw=0 time=0 us cost=0 size=0 card=1)(Object ID 16136)
14000 TABLE ACCESS BY INDEX ROWID T_DEPT (cr=14000 pr=0 pw=0 time=0 us cost=1 size=35 card=1)4
-------------------------------------------------------------------------------------------
<TET4>
-드라이빙 테이블을 무작위로 정렬한 결과 table prefetch 에도 buffer pinning 효과가 없음
-------------------------------------------------------------------------------------------
select /*+ ordered use_nl_with_index(d) nlj_prefetch(d) */
count(e.ename), count(d.dname)
from t_emp e, t_dept d
where d.no = e.no
and d.deptno = e.deptno
Call Count CPU Time Elapsed Time Disk Query Current Rows
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Parse 1 0.080 0.083 0 87 0 0
Execute 1 0.000 0.000 0 0 0 0
Fetch 2 0.360 0.371 0 28098 0 1
------- ------ -------- ------------ ---------- ---------- ---------- ----------
Total 4 0.440 0.454 0 28185 0 1
Misses in library cache during parse: 1
Optimizer goal: ALL_ROWS
Parsing user: SCOTT (ID=36)
Rows Row Source Operation
------- ---------------------------------------------------
0 STATEMENT
1 SORT AGGREGATE (cr=28098 pr=0 pw=0 time=0 us)
14000 TABLE ACCESS BY INDEX ROWID T_DEPT (cr=28098 pr=0 pw=0 time=414624 us cost=1 size=35 card=1)
28001 NESTED LOOPS (cr=14098 pr=0 pw=0 time=119159 us cost=3149 size=272000 card=4000)
14000 TABLE ACCESS FULL T_EMP (cr=95 pr=0 pw=0 time=51923 us cost=30 size=488730 card=14810)
14000 INDEX UNIQUE SCAN T_DEPT_PK (cr=14003 pr=0 pw=0 time=0 us cost=0 size=0 card=1)(Object ID 16136)
-------------------------------------------------------------------------------------------
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 55 |
Front Page
| 운영자 | 2011.02.16 | 115484 |
| 54 | 2. 인덱스 기본 원리 | balto | 2011.02.17 | 19710 |
| 53 | 1장. 인덱스 원리와 활용 | 휘휘 | 2011.02.20 | 7703 |
| 52 |
4. 테이블 Random 액세스 부하
| 휘휘 | 2011.02.26 | 7862 |
| 51 | 5. 테이블 Random 액세스 최소화 튜닝 | 휘휘 | 2011.02.26 | 10406 |
| 50 | 6. IOT, 클러스터 테이블 활용 | 오예스 | 2011.02.26 | 16716 |
| 49 |
7. 인덱스 스캔 효율
| 휘휘 | 2011.03.06 | 9438 |
| 48 | 9. 비트맵 인덱스 | 휘휘 | 2011.03.06 | 5899 |
| 47 | 8. 인덱스 설계 | AskZZang | 2011.03.09 | 6587 |
| 46 | 2. 소트 머지 조인 | 오예스 | 2011.03.20 | 8772 |
| 45 | 3. 해시 조인 | 휘휘 | 2011.03.20 | 7502 |
| 44 | 2장. 조인 원리와 활용 | 운영자 | 2011.03.22 | 4090 |
| » |
1. Nested Loops 조인
| 오라클잭 | 2011.03.22 | 23840 |
| 42 |
6. 스칼라 서브쿼리를 이용한 조인
| balto | 2011.03.26 | 19740 |
| 41 |
5. Outer 조인
| 휘휘 | 2011.03.28 | 18455 |
| 40 |
1. 인덱스 구조
| 운영자 | 2011.03.29 | 17007 |
| 39 | 4. 조인 순서의 중요성 | AskZZang | 2011.03.29 | 6145 |
| 38 | 7. 조인을 내포한 DML 튜닝 | 오예스 | 2011.04.03 | 10788 |
| 37 | 8. 고급 조인 테크닉-2 | 오라클잭 | 2011.04.04 | 13468 |
| 36 |
8. 고급 조인 테크닉-1
| 휘휘 | 2011.04.05 | 7269 |