8. 고급 조인 테크닉-1
2011.04.05 14:00
(1) 누적 매출 구하기
SQL> select * from branchsalesmonth;
BRANCH MONTH SALES
---------- ---------- ----------
10 1 813
10 2 750
10 3 910
20 1 777
20 2 990
20 3 878
20 4 604
20 5 702
30 1 746
30 2 853
30 3 830
BRANCH MONTH SALES
---------- ---------- ----------
30 4 780
30 5 610
30 6 700
14 rows selected.
분석함수 사용
SQL> select branch, month, sales
, sum(sales) over (partition by branch order by month
--range between unbounded preceding and current row
) tot_sales
from branchsalesmonth; 2 3 4 5
BRANCH MONTH SALES TOT_SALES
---------- ---------- ---------- ----------
10 1 813 813
10 2 750 1563
10 3 910 2473
20 1 777 777
20 2 990 1767
20 3 878 2645
20 4 604 3249
20 5 702 3951
30 1 746 746
30 2 853 1599
30 3 830 2429
BRANCH MONTH SALES TOT_SALES
---------- ---------- ---------- ----------
30 4 780 3209
30 5 610 3819
30 6 700 4519
14 rows selected.
SQL>
부등호 조인 사용
SQL> select *
from branchsalesmonth t1, branchsalesmonth t2
where t2.branch = t1.branch
and t2.month <= t1.month
;
BRANCH MONTH SALES BRANCH MONTH SALES
---------- ---------- ---------- ---------- ---------- ----------
10 3 910 10 1 813
10 2 750 10 1 813
10 1 813 10 1 813
10 3 910 10 2 750
10 2 750 10 2 750
10 3 910 10 3 910
20 5 702 20 1 777
20 4 604 20 1 777
20 3 878 20 1 777
20 2 990 20 1 777
20 1 777 20 1 777
BRANCH MONTH SALES BRANCH MONTH SALES
---------- ---------- ---------- ---------- ---------- ----------
20 5 702 20 2 990
20 4 604 20 2 990
20 3 878 20 2 990
20 2 990 20 2 990
20 5 702 20 3 878
20 4 604 20 3 878
20 3 878 20 3 878
20 5 702 20 4 604
20 4 604 20 4 604
20 5 702 20 5 702
30 6 700 30 1 746
BRANCH MONTH SALES BRANCH MONTH SALES
---------- ---------- ---------- ---------- ---------- ----------
30 5 610 30 1 746
30 4 780 30 1 746
30 3 830 30 1 746
30 2 853 30 1 746
30 1 746 30 1 746
30 6 700 30 2 853
30 5 610 30 2 853
30 4 780 30 2 853
30 3 830 30 2 853
30 2 853 30 2 853
30 6 700 30 3 830
BRANCH MONTH SALES BRANCH MONTH SALES
---------- ---------- ---------- ---------- ---------- ----------
30 5 610 30 3 830
30 4 780 30 3 830
30 3 830 30 3 830
30 6 700 30 4 780
30 5 610 30 4 780
30 4 780 30 4 780
30 6 700 30 5 610
30 5 610 30 5 610
30 6 700 30 6 700
42 rows selected.
SQL> select t1.branch, t1.month, min(t1.sales) sales, sum(t2.sales) tot_sales
from branchsalesmonth t1, branchsalesmonth t2
where t2.branch = t1.branch
and t2.month <= t1.month
group by t1.branch, t1.month
order by t1.branch, t1.month;
BRANCH MONTH SALES TOT_SALES
---------- ---------- ---------- ----------
10 1 813 813
10 2 750 1563
10 3 910 2473
20 1 777 777
20 2 990 1767
20 3 878 2645
20 4 604 3249
20 5 702 3951
30 1 746 746
30 2 853 1599
30 3 830 2429
BRANCH MONTH SALES TOT_SALES
---------- ---------- ---------- ----------
30 4 780 3209
30 5 610 3819
30 6 700 4519
14 rows selected.
SQL>
(2) 선분 이력 끊기
선분이력 각 스타일 확인

※ 빨간 점선 원 겹치는 구간의 시작과 종료일
※ 파란 화살표 진행방향
스타일 | 특징 (4개의 시점비교) | 겹치는 구간의 시작및 종료일자 | ||
| 최소값 | 최대값 | 시작일자 | 종료일자 | |
| 스타일 (a) | 시작일자 1 | 종료일자 2 | 시작일자 2 | 종료일자 1 |
| 스타일 (b) | 시작일자 2 | 종료일자 1 | 시작일자 1 | 종료일자 2 |
| 스타일 (c) | 시작일자 1 | 종료일자 1 | 시작일자 2 | 종료일자 2 |
| 스타일 (d) | 시작일자 2 | 종료일자 2 | 시작일자 1 | 종료일자 1 |
자료 생성
SQL> create table month (yymm, datefrom, dateto)
as
select '2009/06', '2009/06/01', '2009/06/30' from dual union all
select '2009/07', '2009/07/01', '2009/07/31' from dual union all
select '2009/08', '2009/08/01', '2009/08/31' from dual union all
select '2009/09', '2009/09/01', '2009/09/30' from dual union all
select '2009/10', '2009/10/01', '2009/10/31' from dual;
Table created.
select to_char(mm,'yyyy/mm') yymm,to_char(mm,'yyyy/mm/dd') datefrom,to_char(last_day(mm),'yyyy/mm/dd') dateto
from(
select add_months(to_date('20090601','yyyymmdd'),level-1) mm from dual connect by level<=5
);
SQL> create table timeline(pno, datefrom, dateto, data)
as
select 'A', '2009/07/13', '2009/08/08', 'A1' from dual union all
select 'A', '2009/08/09', '2009/08/20', 'A2' from dual union all
select 'A', '2009/08/21', '2009/10/07', 'A3' from dual;
Table created.
- 두개이상의 달에 걸친 선분(tileline 의 a1 과 a3)을 매월말 기준으로 끊으려고할때
- 두 테이블을 조인하여 1차 가공하여 6개의 자료로 생성
SQL> select a.yymm, b.datefrom, b.dateto, b.pno, b.data
from month a, timeline b
where b.datefrom <= a.dateto
and b.dateto >= a.datefrom
order by a.yymm, b.datefrom ;
YYMM DATEFROM DATETO P DA
------- ---------- ---------- - --
2009/07 2009/07/13 2009/08/08 A A1
2009/08 2009/07/13 2009/08/08 A A1
2009/08 2009/08/09 2009/08/20 A A2
2009/08 2009/08/21 2009/10/07 A A3
2009/09 2009/08/21 2009/10/07 A A3
2009/10 2009/08/21 2009/10/07 A A3
6 rows selected.
- 선분(b)의 시작일자보다 큰 월도(a) 종료 일자와
- 선분(b)의 종료일자보다 작은 월도(a)의 시작일자
- 조건으로 조인
- a3을 기준으로 설명하면
a3의 종료일( 10/7일)보다 시작일자가 작은 월도는 6,7,8,9,10월 이며 그중에서
a3의 시작일( 8/21)일보다 종료일자가 큰 월도는 8,9,10월 이다
2. 정확한 시작일자와 종료일자 구분
- 이미 정리한 스타일표를 기준으로 4개의 날짜 (시작1,종료1,시작2,종료2) 를 사용하여 자료를 생성
SQL> select pno
, case when lst = datefrom1 and gst = dateto2 then datefrom2 -- 스타일 a
when lst = datefrom2 and gst = dateto1 then datefrom1 -- 스타일 b
when lst = datefrom1 and gst = dateto1 then datefrom2 -- 스타일 c
when lst = datefrom2 and gst = dateto2 then datefrom1 -- 스타일 d
end datefrom
, case when lst = datefrom1 and gst = dateto2 then dateto1 -- 스타일 a
when lst = datefrom2 and gst = dateto1 then dateto2 -- 스타일 b
when lst = datefrom1 and gst = dateto1 then dateto2 -- 스타일 c
when lst = datefrom2 and gst = dateto2 then dateto1 -- 스타일 d
end dateto
, data
from (
select b.pno, b.data, a.yymm
, a.datefrom datefrom1, b.datefrom datefrom2
, a.dateto dateto1, b.dateto dateto2
, least(a.datefrom, a.dateto, b.datefrom, b.dateto) lst
, greatest(a.datefrom, a.dateto, b.datefrom, b.dateto) gst
from month a, timeline b
where b.datefrom <= a.dateto
and b.dateto >= a.datefrom
) ;
P DATEFROM DATETO DA
- ---------- ---------- --
A 2009/07/13 2009/07/31 A1
A 2009/08/01 2009/08/08 A1
A 2009/08/09 2009/08/20 A2
A 2009/08/21 2009/08/31 A3
A 2009/09/01 2009/09/30 A3
A 2009/10/01 2009/10/07 A3
6 rows selected.
SQL>
개선
- 정밀 분석하면 겹치는 구간의 시작일자는 두 시작일자 중 큰 값을
취하면 되고
- 종료일자는 두 종료일자 중 작은 값을 취하면됨
SQL> select b.pno
, greatest(a.datefrom, b.datefrom) datefrom
, least(a.dateto,b.dateto) dateto
, b.data
from month a, timeline b
where b.datefrom <= a.dateto
and b.dateto >= a.datefrom;
P DATEFROM DATETO DA
- ---------- ---------- --
A 2009/07/13 2009/07/31 A1
A 2009/08/01 2009/08/08 A1
A 2009/08/09 2009/08/20 A2
A 2009/08/21 2009/08/31 A3
A 2009/09/01 2009/09/30 A3
A 2009/10/01 2009/10/07 A3
6 rows selected.
(3) 데이터 복제를 통한 소계 구하기
복제용 테이블을 미리 만들어 두고 활용하는 방법
SQL> create table copy_t ( no number, no2 varchar2(2) );
Table created.
SQL> SQL> insert into copy_t
select rownum,lpad(rownum,2,'0') from all_tables where rownum<=31; 2
31 rows created.
SQL> alter table copy_t add constraint copy_t_pk primary key (no);
Table altered.
SQL> create unique index copy_t_no2_idx on copy_t(no2);
Index created.emp 테일블을 3개로 복사
select * from emp a,copy_t b
where b.no <=3;
dual 을 사용 (9i부터)
SQL> select rownum no from dual connect by level <=2;
NO
----------
1
2
emp 테이블을 3개로 복사
SQL> select * from emp a, (select rownum no from dual connect by level<=2) b;
데이터 복제 방법으로 부서별 소계 구하기
SQL> select deptno
, decode(no, 1, to_char(empno), 2, 'DeptSum') empno
, sum(sal) salsum, round(avg(sal)) salavg
from emp a, (select rownum no from dual connect by level <= 2)
group by deptno, no, decode(no, 1, to_char(empno), 2, 'DeptSum')
order by 1, 2;
DEPTNO EMPNO SALSUM SALAVG
---------- ---------------------------------------- ---------- ----------
10 7782 2450 2450
10 7839 5000 5000
10 7934 1300 1300
10 DeptSum 8750 2917
20 7369 800 800
20 7566 2975 2975
20 7788 3000 3000
20 7876 1100 1100
20 7902 3000 3000
20 DeptSum 10875 2175
30 7499 1600 1600
DEPTNO EMPNO SALSUM SALAVG
---------- ---------------------------------------- ---------- ----------
30 7521 1250 1250
30 7654 1250 1250
30 7698 2850 2850
30 7844 1500 1500
30 7900 950 950
30 DeptSum 9400 1567
17 rows selected.
SQL>
3개로 복제하여 총계까지 구하기
SQL> select decode(no, 3, null, to_char(deptno)) deptno
, decode(no, 1, to_char(empno), 2, 'DeptSum', 3, 'TotSum') empno
, sum(sal) salSum, round(avg(sal)) salAvg
from emp a, (select rownum no from dual connect by level <= 3)
group by decode(no, 3, null, to_char(deptno))
, no, decode(no, 1, to_char(empno), 2, 'DeptSum', 3, 'TotSum')
order by 1, 2;
DEPTNO EMPNO SALSUM SALAVG
---------------------------------------- ---------------------------------------- ---------- ----------
10 7782 2450 2450
10 7839 5000 5000
10 7934 1300 1300
10 DeptSum 8750 2917
20 7369 800 800
20 7566 2975 2975
20 7788 3000 3000
20 7876 1100 1100
20 7902 3000 3000
20 DeptSum 10875 2175
30 7499 1600 1600
DEPTNO EMPNO SALSUM SALAVG
---------------------------------------- ---------------------------------------- ---------- ----------
30 7521 1250 1250
30 7654 1250 1250
30 7698 2850 2850
30 7844 1500 1500
30 7900 950 950
30 DeptSum 9400 1567
TotSum 29025 2073
18 rows selected.
SQL>
rollup 사용
SQL> select deptno
, case when grouping(empno)=1 and grouping(deptno)=1 then 'TotSum'
when grouping(empno)=1 then 'DeptSum'
else to_char(empno) end empno,
sum(sal) salsum,round(avg(sal)) salavg
from emp
group by rollup(deptno,empno);
DEPTNO EMPNO SALSUM SALAVG
------ ---------- ---------- ----------
10 7782 2450 2450
10 7839 5000 5000
10 7934 1300 1300
10 DeptSum 8750 2917
20 7369 800 800
20 7566 2975 2975
20 7788 3000 3000
20 7876 1100 1100
20 7902 3000 3000
20 DeptSum 10875 2175
30 7900 950 950
DEPTNO EMPNO SALSUM SALAVG
------ ---------- ---------- ----------
30 7499 1600 1600
30 7521 1250 1250
30 7654 1250 1250
30 7698 2850 2850
30 7844 1500 1500
30 DeptSum 9400 1567
TotSum 29025 2073
18 rows selected.
SQL>
(4) 상호 배타적 관계의 조인
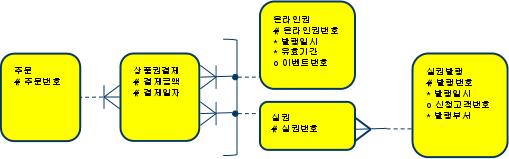
- 상품권결제 테이블의 구현방법
- 온라인권번호, 실권 번호 컬럼을 따로두고
레코드 별로 둘중 하나의 컬럼에만 값을 입력 - 상품권 구분과 상품권 번호 컬럼을 두고
번호컬럼에 구분1일경우 ‘온라인’, 2 일경우 ‘실권’번호입력
- 1번처럼 설계할 경우
Outer 조인으로 사용가능
select /*+ ordered use_nl(b) use_nl(c) use_nl(d) */
a.주문번호, a.결제일자, a.결제금액
,nvl(b.온라인권번호, c.실권번호) 상품권번호
,nvl(b.발행일시, d.발행일시) 발행일시
from 상품권결제 a,온라인권 b, 실권 c, 실권발행 d
where a. 결제일자 between :dt1 and :dt2
and b.온라인권번호(+)=a.온라인권번호
and c.실권번호(+)=a.실권번호
and d.발행번호(d)=c.발행번호;
- 2번처럼 설계했을 경우
union all이용
select x.주문번호, x.결제일자, x.결제금액, y.온라인권번호 상품권번호, y.발행일시, ….
from 상품권결제 x, 온라인권 y
where x.상품권구분=’1’
and x.결제일자 between :dt1 and :dt2
and y.온라인권번호=x.상품권번호
union all
select x.주문번호,x.결제일자,x.결제금액,y.실권번호 상품권번호,z.발행일시,....
from 상품권결제 x,실권 y, 실권발행 z
where x.상품권구분=’2’
and x.결제일자 between :dt1 and :dt2
and y.실권번호 = x.상품권번호
and z.발행번호 =y.발행번호
인덱스
[상품권구분+결제일자] : 범위 중복 없음
[결제일자+상품권구분] : 인덱스 스캔범위에 중복이 발생
[결제일자] : 상품권 구분을 필터링하기 위한 테이블 random 액세스 까지 중복 발생
튜닝
select /*+ ordred use_nl(b) use_nl(c) use_nl(d) */
a.주문번호, a.결제일자, a.결제금액
,nvl(b.온라인권번호, c.실권번호) 상품권번호
,nvl(b.발행일시,d.발행일시) 발행일시, ….
from 상품권결제 a,온라인권 b,실권 c,실권발행 d
where a.결제일자 between :dt1 and :dt2
and b.온라인권번호(+)=decode(a.상품권구분,’1’,a.상품권번호)
and c.실권번호(+)=decode(a.상품권구분,’2’,a.상품권번호)
and d.발행번호(+)=c.발행번호
(5) 최종 출력 건에 대해서만 조인하기
select *
from (
select rownum no, 등록일자, 번호, 제목
,회원명, 게시판유형명, 질문유형명, count(*) over () cnt
from (
select a.등록일자,a.번호,a.제목,b.회원명,c.게시판유형명,d.질문유형명
from 게시판 a,회원 b, 게시판유형 c, 질문유형 d
where a.게시판유형=:type
and b.회원번호=a.작성자번호
and c.게시판유형=a.게시판유형
and d.질문유형=a.질문유형
order by a.등록일자 desc, a.질문유형, a.번호
)
where rownum <=31
)
where no between 21 and 30
기본 정보
게시판 데이터: 수백만건
특정게시판유형 (:TYPE) 에 속하는 데이터 : 평균 10만건
인덱스구성
>> 게시판_X01 : 게시판유형+등록일자 DESC + 번호
Execution Plan
-----------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 VIEW
2 1 WINDOW (BUFFFER)
3 2 COUNT (STOPKEY)
4 3 VIEW
5 4 SORT (ORDER BY STOPKEY)
6 5 NESTED LOOPS
7 6 NESTED LOOPS
8 7 NESTED LOOPS
9 8 TABLE ACCES (BY LOCAL INDEX ROWID) OF '게시판' (TABLE)
10 9 INDEX (RANGE SCAN) OF '게시판_X01' (INDEX (UNIQUE))
11 10 TABLE ACCESS (BY INDEX ROWID) OF '회원' (TABLE)
12 11 INDEX (UNIQUE SCAN) OF '회원_PK' (INDEX (UNIQUE))
13 7 TABLE ACCESS (BY INDEX ROWID) OF '게시판유형' (TABLE)
14 13 INDEX (UNIQUE SCAN) OF '게시판유형_PK' (INDEX (UNIQUE))
15 6 TABLE ACCESS (BY INDEX ROWID) OF '질문유형' (TABLE)
16 15 INDEX (UNIQUE SCAN) OF '질문유형_PK' (INDEX (UNIQUE))
- 10만건을 읽어 나머지 세테이블과의 조인을 완료후
소트단게에서 STOPKEY 가 작동
인덱스 구성에 따라 소트 오프레이션이 불가피
튜닝
게시판_X01 인덱스에 질문유형 컬럼추가
>> 게시판_X01: 게시판유형+등록일자 DESC+번호+질문유형
- '게시판=:TYPE' 조건에 해당하는 레코드를 찾는 작업은 인덱스 내에서 해결 가능하므로
- 아래와 같은 인덱스만 읽는 쿼리가 작성가능
SELECT ROWID RID
FROM 게시판
WHERE 게시판유형 =:TYPE
ORDER BY 등록일자 DESC,질문유형,번호
SELECT /*+ ORDERED USE_NL(A) USE_NL(B) USE_NL(C) USE_NL(D) ROWID(A) */
A.등록일자,B.번호,A.제목,B.회원명,C.게시판유형명,D.질문유형명,X.CNT
FROM (
SELECT RID,ROWNUM NO,COUNT(*) OVER(CNT)
FROM (
SELECT ROWID RID
FROM 게시판
WHERE 게시판유형=:TYPE
ORDER BY 등록일자 DESC,질문유형, 번호
)
WHERE ROWNUM<=31
) X,게시판 A,회원B,게시판유형 C,질문유형 D
WHERE X.NO BETWEEN 21 AND 30
AND A.ROWID=X.RID
AND B.회원번호=A.작성자번호
AND C.게시판유형=A.게시판유형
AND D.질문유형=A.질문유형
Execution Plan
--------------------------------------------------------------------------------
0 SELECT STATEMENT Optimizer=ALL_ROWS
1 0 NESTED LOOPS
2 1 NESTED LOOPS
3 2 NESTED LOOPS
4 3 NESTED LOOPS
5 4 VIEW
6 5 COUNT (STOPKEY)
7 6 VIEW
8 7 SORT(ORDER BY STOPKEY)
9 8 INDEX (RANGE SCAN) OF '게시판_X01' (INDEX (UNIQUE))
10 4 TABLE ACCESS (BY USER ROWID) OF '게시판' (TABLE)
11 3 TABLE ACCESS (BY INDEX ROWID) OF '회원' (TABLE)
12 11 INDEX (UNIQUE SCAN) OF '회원_PK' (INDEX (UNIQUE))
13 2 TABLE ACCESS (BY INDEX ROWID) OF '게시판유형' (TABLE)
14 13 INDEX (UNIQUE SCAN) OF '게시판유형_PK' (INDEX (UNIQUE))
15 1 TABLE ACCESS (BY INDEX ROWID) OF '질문유형' (TABLE)
16 15 INDEX (UNIQUE SCAN) OF '질문유형_PK' (INDEX (UNIQUE))
- 인라인 뷰내에서는 인덱스만 읽고
- 두번째 게시판테이블(A)을 액세스할때는 인라인뷰의 ROWID값으로 직업 엑세스
'TABLE ACCESS BY USER ROWID' 로 표시
- 질문)
- 조인컬럼인 작성자 번호, 게시판유형, 질문유형이 NULL 인경우?
NULL이 제외되지 않아야 하는 경우
- OUTER 조인사용
WHERE X.NO BETWEEN 21 AND 30
AND A.ROWID=X.RID
AND B.회원번호(+)=A.작성자번호
AND C.게시판유형(+)=A.게시판유형
AND D.질문유형(+)=A.질문유형
NULL 제외해야 하는 경우
- 인라인 뷰안에 IS NOT NULL조건 추가
WHERE 게시판유형=:TYPE
AND 작성자번호 IS NOT NULL
AND 게시판유형 IS NOT NULL
AND 질문유형 IS NOT NULL
※ 단 이들 컬럼도 인덱스 구성에 추가하여야함
- 인덱스 조정이 여의치 않으면
SELECT /*+ ORDERED USE_NL(A) USE_NL(B) USE_NL(C) USE_NL(D) */
A.등록일자, B.번호, A.제목, B.회원명, C.게시판유형명, D.질문유형명, A.CNT
FROM (
SELECT A.*, ROWNUM NO,COUNT(*) OVER() CNT
FROM (
SELECT 등록일자,번호,제목,작성자번호,게시판유형,질문유형
FROM 게시판
WHERE 게시판유형=:TYPE
AND 작성자번호 IS NOT NULL
AND 게시판유형 IS NOT NULL
AND 질문유형 IS NOT NULL
ORDER BY 등록일자 DESC, 질문유형, 번호
) A
) WHERE ROWNUM <=31
) A, 회원 B,게시판유형 C,질문유형 D
WHERE A.NO BETWEEN 21 AND 30
AND B.회원번호=A.작성자번호
AND C.게시판유형=A.게시판유형
AND D.질문유형=A.질문유형
※ 전체를 읽어 정렬하는 부하가 있지만 불필요한 조인횟수를 줄이는 효과를 볼수 있음
반정규화는 성능을 위한 최후의 수단
- 정규화된 모델로는 제대로 성능을 내기 어려울 때만 반정규화를 단행
업무 연락 메시지 게시판 구현한다면
기능중 발송메시지 건수, 수신인건수 채크등이 필요
select ….
from
select ….
from (
select a. 발신인ID, a.발송일시, a.제목,b.사용자이름 as 보낸이
, (select count(수신일시) from 메시지수신인 …) 수신확인자수
, (select count(*) from 메시지수신인 …) 수신대상자수
,(case when exists (select ‘x’ from 메시지수신인
where 발신자ID=a.발신자ID
and 발송일시=a.발송일시
and 수신자ID=:로그인사용자ID
and 수신일시 is null) then ‘Y’ end) 새글여부
from 메시지 a,사용자 b
order by a.발솔일시 desc
) a
where rownum <=10
)
where no between 1 and 10
- 수신확인자수와 수신대상자수를 세고 새글여부를 확인하는
스칼라 서브쿼리 때문에 성능문제가 발생 - 이경우 아래의 붉은 점선 안쪽과 같은 추출(derived) 속성을 설계에 사용
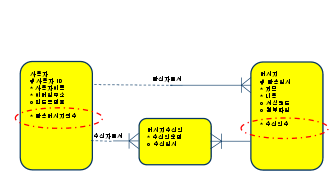
추출속성사용시
- 수신때마다 수신인수 갱신 DML추가 작성
- 정합성에 주의하여야함
- 사용자 탈퇴시 수신인수 일괄갱신 필요
반정규화를 실시했을경우
- 업무 규칙 누락 확인이 필요하며
- 반정규화 없이 성능 이슈를 해결하는것이 가장 좋음
- 반정규화없이 쿼리 예
select a.발송일시, a.제목, b.사용자이름 as 보낸이
,(select count(수신일시) || ‘/’ || count(*) from 메시지수신인 …) 수신확인
,(case when exists (...) then ‘Y’ end) 새글여부
from (
select rownum no, …
from (select 발신인ID, 발송일시, 제목 from 메시지 order by 발송일시 desc)
where rownum <= 30
) a, 사용자 b
where no between 21 and 30
and …
(6) 징금 다리 테이블 조인을 이용한 튜닝
from 절에서 조인되는 테이블 개수를 늘려 성능을 향상 시키는 사례

고객할인혜택 조회 쿼리
SELECT /*+ ordred use_nl(s r) */ c.고객번호, s.서비스번호, s.서비스구분코드
, s. 서비스상태코드, s.서비스상태변경코드, r.할인시작일자, r.할인종료일자
from 고객 c, 서비스 s, 서비스요금할인 r
where c.주민법인등록번호 = :ctz_biz_num
and s.명의고개번호 = c.고객번호
and r.서비스번호 = s.서비스번호
and r.서비스상품그룹 = ‘3001’
and r.할인기간코드 = ‘15’
order by r.할인종료일자 desc , s.서비스번호
인덱스
고객_N1: 주민법인등록번호
서비스_N2 : 명의고객번호 + 서비스 번호
서비스요금할인_PK : 서비스번호 + 서비스상품그룹
서비스요금할인_N1 : 서비스상품그룹 + 할인기간코드
수행결과
- 서버구간에서 28초 / 블록 i/o 226,672번
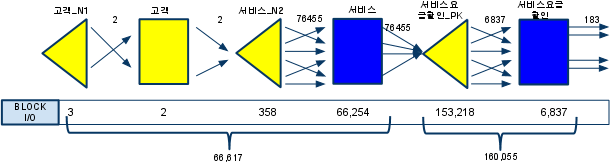
- 최종건수: 183건
- 고객테이블을 먼저 드라이빙해서 서비스 테이블과 nl조인 과정 블록I/O발생 : 66,617개
- 서비스요금할인 테이블과 NL 조인 과정 추가 블록 I/O : 160,055개
- 총 블록I/O : 226,672
- 조인순서변경하더라도 조인 액스스량을 줄이기는 어려움
- 해시조인으로유도
- 91,443 (66,617+24,826) 개의 블록 I/O 발생
- I/O가 절반이상 줄어듬
- 그리 빠른 속도는 아님
- 분석 결과
- 최종결과 건수가 얼마 되지 않음
- 필터 조건만으로 각 부분을 따로 읽으면 결과 건수가 많음
- NL 조인 과정에서 Random I/O 부하가 심하게 발생하기때문에 어느쪽이 드라이빙되어도 결과는 마찬가지
튜닝
- 인텍스 추가
- 서비스요금할인_N1 : 서비스상품그룹 + 할인기간코드 + 서비스번호
- 쿼리변경
SELECT /*+ ordred use_hash (r_brdg) rowid(s) rowid(r) */
c.고객번호, s.서비스번호, s.서비스구분코드, s.서비스상태코드
,s.서비스상태변경코드, r.할인시작일자, r.할인종료일자
from 고객 c
, 서비스 s_brdg, 서비스요금할인 r_brdg
, 서비스 s, 서비스요금할인 r
where c.주민법인등록번호 = :ctz_biz_num
and s_brdg.명의고객번호 =c.고객번호
and r_brdg.서비스번호 = s_brdg.서비스번호
and r_brdg.서비스상품그룹 = ‘3001’
and r_brdg.할인기간코드 =’15’
and s.rowid =s_brdh.rowid
and r.rowid =r_brdg.rowid
order by r.할인종료일자 desc, s.서비스 번호
- 수행결과
- 리딩: 857개 블록
- 시간: 0.12초
- 양쪽 테이블에서 인덱스만 읽은 결과끼리 먼저 조인하고
- 최종 결과집합 183건에 대해서먼 테이블 액세스
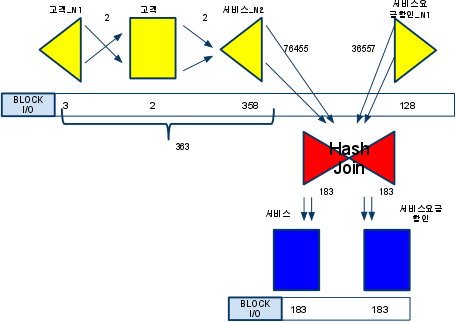
- 고객테이블과 서비스_N2인덱스를 조인할때 블록 I/O : 총 363번 발생
- 서비스요금할인_N1 인덱스 읽을때 블록 I/O : 128개 (94->128은 서비스번호 컬럼추가)
- 인덱스에서 얻어진 집합끼리 해시 조인방식으로 조인
- 인덱스에서 없는 컬럼 값을 읽으려고 인덱스에서 읽은 ROWID로 직접 테이블엑세스
'Table Acces By User ROWID'
인조 식별자 사용에 의한 조인 성능이슈
- 액세스 경로(Acces Path)에 대한 고려 없이
- 인조식별자 (Artificial Identifier) 를 설계하면 조인성능이슈가 발생할수 있음
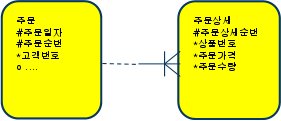
- 기본정보
- 주문 테이블에 주문일자별로 평균 100,000건
- 주문상세 테이블에 주문일자별로 600,000건 (= 1,000 * 600 )
- 상품번호는 1,000가지
- 주문상세는 상품번호별로 평균 600건
- 주문 하나당 하루 평균 6건의 주문상세
select sum(주문상세.가격*주문상세.주문수량) 주문금액
from 주문,주문상세
where 주문, 주문일자 = 주문상세.주문일자
and 주문.주문순번 = 주문상세.주문순번
and 주문.주문일자 = ‘20090315’
and 주문상세.상품번호 = ‘AC001’
- 인덱스
- 주문상세
- [상품번호+주문일자] 또는 [주문일자+상품번호]
- 특정 주문일자에 발생한 특정 상품주문 집계시 효과적으로 사용가능
주문번호 라는 인조 식별자 컬럼을 둘경우
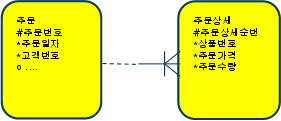
select sum(주문상세.가격 * 주문상세.주문수량) 주문금액
from 주문,주문상세
where 주문.주문번호=주문상세.주문번호
and 주문.주문일자 = ‘20090315’
and 주문상세.상품번호 = ‘AC001’
- 인덱스
- 주문_PK
- 주문번호
- 주문_X01
- 주문일자
- 주문상세_PK
- 주문번호 + 주문상세순번
- 주문상세_X01
- 상품번호
- 수행과정
- 주문테이블에서 읽은 100,000건에 대해
- 주문상세 쪽으로 100,000번의 조인 액세스
- 주문상세_PK 엔덱스를 거쳐 주문상세 테이블을 100,000번 액세스
- 상품번호='AC001'조건 필터링
- 최종적으로 600건 정도만 남기고 모두 버럼
- 주문상세 테이블을 먼저읽을경우
- 가정: 두테이블의 상품주기 1년
- 상품번호당 평균 카디널리티 219,000건 (=100,000 * 6/1000*365)
- 주문 테이블쪽을 조인액세스 발생시 PK인덱스를 거쳐 주문테이블을 219,000번 액세스
- 주문일자=’20090315’ 조건을 필터링
- 600건 정도만 남기고 모두 버림
- 더비효율적
- 해시 조인으로 유도
- 인덱스를 거쳐 각각 100,000건과 219,000건의 데이터를 읽음
- 상당량의 테이블 Random 액세스가 발생
인조 식별자를 둘때 주의 사항
- 장점
- PK,FK가 단일 컬럼으로 구성되어 테이블 간 연결 구조가 단순
- 제약조건을 위해 사용되는 인덱스 저장공간의 최소화
- 다중 컬럼으로 조인할때보다 조인연산을 위한 CPU사용량이 줄어듬
- 단점
- 조인 연산 횟수와 블록 I/O가 증가로 더많은 시스템 리소스를 낭비
- 액세스 범위를 줄이지 못하므로 조인을위해 사용되는 PK인덱스가 많이 생성됨
- 데이터 모델이 이해하기 어려워짐 (가독성이 떨어짐)
- 결론
- 업무적으로 이미 통용되는 식별자
- 유연성/확장성을 고려해 설계해야함
(7) 점이력 조회
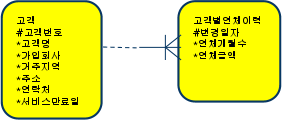
- 점이력
- 데이터 변경이 발생할때 마다 변경일자와 함께 새로운 이력 레코드를 쌓는 방식
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and b.변경일자 = (select /*+ no_unnest */ max(변경일자)
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일);
※ 찾고자 하는 시점(서비스만료일) 보다 앞선 변경일자 중 가장 마지막 레코드
Rows Row Source Operation
-----------
10 TABLE ACCESS BY INDEX ROWID 고객별연체이력 (CR=59 PR=0 PW=0 TIME=177 us)
21 NESTED LOOPS (CR=49 PR=0 PW=0 TIME=2162 us)
10 TABLE ACCES BY INDEX ROWID 고객 (cr=4 pr=0 pw=0 time=142 us)
10 INDEX RANGE SCAN 고객_IDX01 (cr2 pr=0 pw=0 time=53 us)
10 INDEX RANGE SCAN 고객별연체이력_IDX01 (cr=45 pr=0 pw=0 time=681 us)
10 SORT AGGREGATE (cr=22 pr=0 pw=0 time=464 us)
10 FIRST ROW (cr=22 pr=0 pw=0 time=283 us)
10 INDEX RANGE SCAN (MIN/MAX) 고객별연체이력_IDX01 (cr=22 pr=0 pw=0 ..)
- 서브쿼리 내에서 서비스 만료일 보다 작은 레코드를 모두 스캔하지 않고
- 인덱스를 거꾸로 스캔하면서 가장 큰 값 하나만을 찾는 방식 사용
- line 7: first row
- line 8: min/max
참고
index_desc 힌트와 rownum<=1 조건 사용시, 주의사항
- 인덱스 구성이 변경되면 쿼리 결과가 틀리게 될수있음
- first row(min/max)알고리즘이 작동할때는 min/max함수를 사용해야함
- 사용해야만한다면 프로그램목록을 별도로 관리 (변경시마다 확인하는 프로세스 필요)
- min max 함수내에서 컬럼을 가공하면 first row알고리즘 동작하지 않음
- select substr(max(변경일자||순번),9) from 이력 where...
스칼라 서브쿼리로 변환
- 인덱스를 두번 액세스하지 않기 때문에 I/O를 줄일수 있음
- 인덱스 루트 블록에 대한 버퍼 Pinning 효과가 사라짐
- 10번액세스하면서 30번 블록I/O발생,height=3
select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */ 연체금액
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and b.변경일자 <= a.서비스만료일
and rownum <= 1) 연체금액
from 고객 a
where 가입회사 = 'C70';
※ 고객별 연체이력 테이블로부터 연체금액 하나만 읽기 때문에 변경이 수월
- 두개이상 컬럼을 읽을경우
select 고객명, 거주지역, 주소, 연락처
, to_number(substr(연체, 3)) 연체금액
, to_number(substr(연체, 1, 2)) 연체개월수
from (select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */
lpad(연체개월수, 2) || 연체금액
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일
and rownum <= 1) 연체
from 고객 a
where 가입회사 = 'C70'
);
※ 메인쿼리에서 substr함수로 잘라 사용
- 일일이 substr로 자르는 것이 힘들경우
select /*+ ordered use_nl(b) rowid(b) */ a.*, b.연체금액, b.연체개월수
from (select a.고객명, a.거주지역, a.주소, a.연락처
,(select /*+ index_desc(b 고객별연체이력_idx01) */ rowid rid
from 고객별연체이력 b
where b.고객번호 = a.고객번호
and b.변경일자 <= a.서비스만료일
and rownum <= 1) rid
from 고객 a
where 가입회사 = 'C70') a, 고객별연체이력 b
where b.rowid = a.rid;
- 서브쿼리에서 rowid 값만 취하고 실테이블을 한번더 조인하면 가능
- 고객별 연체이력을 두번사용했지만 실행계획상 NL과 같은 프로세스로 동작
- outer 인덱스 -> outer 테이블 -> inner 인덱스 -> inner 테이블
SQL로 바로 구현
select /*+ ordered use_nl(b) rowid(b) */
a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.rowid = (select /*+ index(c 고객별연체이력_idx01) */ rowid
from 고객별연체이력 c
where c.고객번호 = a.고객번호
and c.변경일자 <= a.서비스만료일
and rownum <= 1);
- 고객(a)에서 읽은 고객번호로
- 서브쿼리쪽 고객별 연체이력(c)과 조인
- 결과로얻은 rowid값으로
- 고객별 연체이력(b)을 곧바로 액세스
- 고객별 연체이력을 두번사용했지만 실행계획상 NL과 같은 프로세스로 동작
- outer 인덱스 -> outer 테이블 -> inner 인덱스 -> inner 테이블
정해진 시점 기준으로 조회
select /*+ full(a) full(b) full(c) use_hash(a b c) no_merge(b) */
a.고객명, a.거주지역, a.주소, a.연락처, c.연체금액, c.연체개월수
from 고객 a
,(select 고객번호, max(변경일자) 변경일자
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')
group by 고객번호) b, 고객별연체이력 c
where b.고객번호 = a.고객번호
and c.고객번호 = b.고객번호
and c.변경일자 = b.변경일자;
- 고객별 연체 이력 테이블을 두번 full scan하는 비효율이 있음
select a.고객명, a.거주지역, a.주소, a.연락처
, to_number(substr(연체, 11)) 연체금액
, to_number(substr(연체, 9, 2)) 연체개월수
from 고객 a
,(select 고객번호, max(변경일자 || lpad(연체개월수, 2) || 연체금액 ) 연체
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')
group by 고객번호) b
where b.고객번호 = a.고객번호;
- 읽어야할 자료가 많을경우 번거러울수 있음
분석함수 사용
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a
,(select 고객번호, 연체금액, 연체개월수, 변경일자
, row_number() over (partition by 고객번호 order by 변경일자 desc) no
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')) b
where b.고객번호 = a.고객번호
and b.no = 1;
- max 함수 사용
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a
,(select 고객번호, 연체금액, 연체개월수, 변경일자
, max(변경일자) over (partition by 고객번호) max_dt
from 고객별연체이력
where 변경일자 <= to_char(sysdate, 'yyyymmdd')) b
where b.고객번호 = a.고객번호
and b.변경일자 = b.max_dt;
- 오라클 고도화 원리와 해법 2 (bysql.net 2011년 1차 스터디)
- 작성자: 테스트 (아이디)
- 최초작성일: 2011년 2월 19일
- 본문서는 bysql.net 스터디 결과입니다 .본 문서를 인용하실때는 출처를 밝혀주세요. http://www.bysql.net
- 문서의 잘못된 점이나 질문사항은 본문서에 댓글로 남겨주세요. ^^
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 55 |
Front Page
| 운영자 | 2011.02.16 | 115476 |
| 54 | 2. 인덱스 기본 원리 | balto | 2011.02.17 | 19704 |
| 53 | 1장. 인덱스 원리와 활용 | 휘휘 | 2011.02.20 | 7693 |
| 52 |
4. 테이블 Random 액세스 부하
| 휘휘 | 2011.02.26 | 7850 |
| 51 | 5. 테이블 Random 액세스 최소화 튜닝 | 휘휘 | 2011.02.26 | 10420 |
| 50 | 6. IOT, 클러스터 테이블 활용 | 오예스 | 2011.02.26 | 16715 |
| 49 |
7. 인덱스 스캔 효율
| 휘휘 | 2011.03.06 | 9439 |
| 48 | 9. 비트맵 인덱스 | 휘휘 | 2011.03.06 | 5892 |
| 47 | 8. 인덱스 설계 | AskZZang | 2011.03.09 | 6580 |
| 46 | 2. 소트 머지 조인 | 오예스 | 2011.03.20 | 8763 |
| 45 | 3. 해시 조인 | 휘휘 | 2011.03.20 | 7515 |
| 44 | 2장. 조인 원리와 활용 | 운영자 | 2011.03.22 | 4075 |
| 43 |
1. Nested Loops 조인
| 오라클잭 | 2011.03.22 | 23835 |
| 42 |
6. 스칼라 서브쿼리를 이용한 조인
| balto | 2011.03.26 | 19761 |
| 41 |
5. Outer 조인
| 휘휘 | 2011.03.28 | 18447 |
| 40 |
1. 인덱스 구조
| 운영자 | 2011.03.29 | 16989 |
| 39 | 4. 조인 순서의 중요성 | AskZZang | 2011.03.29 | 6138 |
| 38 | 7. 조인을 내포한 DML 튜닝 | 오예스 | 2011.04.03 | 10780 |
| 37 | 8. 고급 조인 테크닉-2 | 오라클잭 | 2011.04.04 | 13452 |
| » |
8. 고급 조인 테크닉-1
| 휘휘 | 2011.04.05 | 7253 |