1. 옵티마이저
2011.04.17 17:31
(1) 옵티마이저란?
옵티마이저(Optimizer)
- 사용자가 요청한 SQL 을 가장 효율적이고 빠르게 수행할 수 있는 최적(최저비용)의
처리경로를 선택해 주는 DBMS의 핵심엔진 - SQL(구조화된 질의언어)로 사용자가 원하는 결과집합을 정의하면
이를 얻는데 필요한 처리절차를 자동으로 생성
종류
- 규칙기반 옵티마이저(Rule-Based Optimizer, 이하 RBO)
- 비용기반 옵티마이저(Cost-Based Optimizer, 이하 CBO)
※ 오라클은 10g부터 RBO지원 중단, 타 DBMS는 초기부터 CBO 채택
(2) 규칙기반 옵티마이저
- RBO
- 휴리스틱(Heuristic) 옵티마이저
- 미리 정해놓은 우선순위에 따라 액세스 경로(Access Path)를 평가하고 실행계획을 선택
※ 액세스 경로별 우선순위
| 순위 | 액세스 경로 |
| 1 | Single Row by Rowid |
| 2 | Single Row by Cluster Join |
| 3 | Single Row by Hash Cluster Key with Unique or Primary Key |
| 4 | Single Row by Unique or Primary Key |
| 5 | Clustered Join |
| 6 | Hash Cluster Key |
| 7 | Indexed Cluster Key |
| 8 | Composite Index |
| 9 | Single-Column Indexes |
| 10 | Bounded Range Search on Indexed Columns |
| 11 | Unbounded Range Search on Indexed Columns |
| 12 | Sort Merge Join |
| 13 | MAX or MIN of Indexed Column |
| 14 | ORDER BY on Indexed Column |
| 15 | Full Table Scan |
- 장점
- OLTP 환경의 중소형 데이터 시스템에서는 어느정도 보편 타당성을 가짐
- 예측 가능하고 일관성 있는 실행 계획을 수립하여 원하는 처리경로로 유도하기가 쉬움
- ( CBO는 같은 SQL이라도 데이터 특성에 따라 실행계획이 바뀜)
- 단점
- 테이터 특성을 고려하지 않음
- 데이터량, 값의수(Number of Distinct Value),컬럼값 분포, 인덱스 높이, 클러스터링 팩터
- Full Table Scan과 순익을따지지 않고 무조건 Index를 신뢰
- "select /*+ rule */ * from emp order by empno" 의 경우
- emp테이블에 인덱스가 있을경우
인텍스를 이용해 sort order by 연산을 데체
- 부분처리가 불가능하면 Full Table scan후 정렬이 유리
(3) 비용기반 옵티마이저
- 비용
- 쿼리를 수행하는데 소요되는 일량 또는 시간을 뜻함
- 비용 평가
- I/O 요청횟수, CPU연산 비용까지 감안하여 상대적인 시간개념으로 환산
- 비용산정시 사용되는 오브젝트 통계항목
- 레코드 개수
- 블록개수
- 평균행 길이
- 컬럼 값의 수
- 컬럼값 분포
- 인덱스 높이
- 클러스터링 팩터 등
- 시스템 통계정도
- CPU속도
- 디스크 I/O 속도등
- 4절에 설명
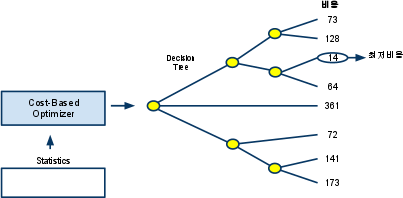
- 수행단계 요약
1. 쿼리 수행을 위해 후보군이 될만한 실행계획을 찾는다.
2. Data Dictionary에 미리 수집해 놓은 오브젝트 통계및 시스템 통계정보를 이용해 실행계획의 예상 비용을 산정한다.
3. 각 실행계획중 최저 비용을 갖는 하나를 선택한다.
참고) 동적 샘플링
- 테이블과 인덱스에 대한 통계정보가 없거나 오래되어 신뢰할수 없을때 수행할수 있음
- optimizer_dynamic_sampling 파라미터로 동적 샘플링 레벨을 조정
- 9i 기본레벨 : 1
- 10g 통계정보 없는 테이블 발견시 무조건 통적 샘플링 수행
- 0 : 수행하지 않음
- 1 : 조건 만족시 수행
- 통계정보가 수집되지 않은 테이블이 적어도 하나 이상 있어야 하며
- 그 테이블이 다른 테이블과 조인되거나 서브쿼리 또는 Non-mergeable View에 포함되고
- 그 테이블에 인덱스가 하나도 없고
- 그 테이블에 할당된 블록수 가 32개(샘플링을 위한 표본 블록수의 기본값) 보다 많을때
- 레벨 10까지 있으며 레벨이 높을수록 적극적으로 샘플링을 하며 표본 블록개수가 증가
- 데이터 딕셔너리에 영구저장되지 않음
- 하드 파싱할때마다 Recurisive SQL이 추가로 수행되므로 성능이 떨어지게 됨
- SQL 트레이스에 Recurisive SQL을 발경가능
- SELECT */ OPT_DYN_SAMP */ … FROM …
- SQL 처리 절차 - CBO 기준
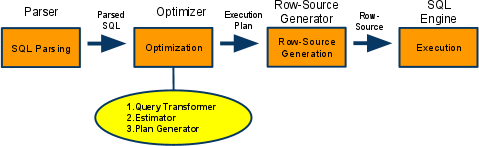
- SQL 파서, Row-Source Generator
- 1권에서 설명 (4장 2절 http://bysql.net/?document_srl=5541)
- Optimizer
- Query Transformer
- SQL을 최적화하기 쉬운 형태를 변환을 시도 (동일함이 보장될경우)
- Estimator
- 선택도(Selectivity), 카디널리티 (Cardinality), 비용(Cost) 계산
- 실행계획 전체에 대한 총 비용을 계산
- I/O, CPU, 메모리 사용량 예측( DB오브젝트 통계정보와 , 시스템 성능 통계정보를 이용)
- Plan Generator
- 쿼리 수행에 필요한 후보군이 될 만한 실행계획들을 생성
참고 - 스스로 학습하는 옵티마이저 (Self-Learning Optimizer)
- v$sql, v$sql_plan_statistics,v$sql_plan_statistics_all,v$sql_workarea 등에
sql별로 저장된 런타임 수행 통계등을보면서 수행계획을 보강- 9i, 10g에서 ‘스스로 학습하는 옵티마이저'를 선보이는 듯하였으며 11g부터 본격화 하는듯 싶음
- 11g - 적응적 커서 공유 (Adaptive Cursor Sharing) 기법
- 9i - 동적 실시간 최적화 (Dynamic Runtime Optimizqtions)개념등
(4) 옵티마이저 모드
5가지 값
- rule
- all_rows
- first_rows
- first_rows_n
- choose
시스템 레벨, 세션레벨, 쿼리 레벨에서 변경 가능
- 시스템 레벨변경 : alter system set optimizer_mode=all_rows;
- 세션 레벨 변경 : alter session set optimizer_mode=all_rows;
- 쿼리 레벨 변경 : select /*+ all_rows */ * from t where … ;
RULE
- RBO모드
ALL_ROWS
- 쿼리 최종 결과 집합을 끝까지 Fetch
- 시스템 리소스 (I/O, CPU,메모리등)를 가장 적게 사용하는 실행계획 선택
- ALL_ROWS모드로 작동
- DML 문장
- 옵티마이저 모드에 상관없이 작동
- SELECT 문장
- UNION,MINUS 같은 집합연산자나 FOR UPDATE절을 사용할때
- PL/SQL내의 SQL
- 힌트를 사용하거나 기본모드가 RULE인 경우를 제외하면 항상 작동
FIRST_ROWS
- 일부 로우만 Fetch 하다가 멈추어 가장 빠른 응답 속도를 낼수 있는 실행계획을 선택
- 비용과 규칙을 혼합한 형태
- 옵티마이저 내부에 정해진 규칙을 사용하여 작동
기초자료 생성
SQL> create table t_emp
2 as
3 select * from scott.emp, (select rownum no from dual connect by level<=1000 )
4 order by dbms_random.value;
Table created.
SQL> set linesize 120
SQL> alter table t_emp add constraint t_emp_pk primary key (empno,no);
Table altered.
SQL> begin
2 dbms_stats.gather_table_stats(
3 ownname=>user
4 ,tabname=>'t_emp'
5 ,method_opt =>'for columns sal');
6 end;
7 /
/*+ all_rows */
SQL> set autot on
SQL> select /*+ all_rows */ * from t_emp
where sal>=5000
order by empno, no;
1000 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1175086354
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 42000 | 27 (4)| 00:00:01 |
| 1 | SORT ORDER BY | | 1000 | 42000 | 27 (4)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| T_EMP | 1000 | 42000 | 26 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("SAL">=5000)
Statistics
----------------------------------------------------------
171 recursive calls
0 db block gets
119 consistent gets
0 physical reads
0 redo size
19248 bytes sent via SQL*Net to client
1145 bytes received via SQL*Net from client
68 SQL*Net roundtrips to/from client
6 sorts (memory)
0 sorts (disk)
1000 rows processed
SQL>
※ Table Full scan하고 나서 소트 연산수행
/ *+first_rows */
SQL> select / *+first_rows */ * from t_emp
2 where sal>=5000
3 order by empno,no;
…
Execution Plan
----------------------------------------------------------
Plan hash value: 1185322641
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 42000 | 13882 (1)| 00:02:47 |
|* 1 | TABLE ACCESS BY INDEX ROWID| T_EMP | 1000 | 42000 | 13882 (1)| 00:02:47 |
| 2 | INDEX FULL SCAN | T_EMP_PK | 14000 | | 36 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("SAL">=5000)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
13947 consistent gets
0 physical reads
0 redo size
19248 bytes sent via SQL*Net to client
1145 bytes received via SQL*Net from client
68 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1000 rows processed
SQL>
※ order by 컬럼 순으로 정렬된 PK인덱스를 사용
- 비용보다 규칙이 우선
- Table Full Scan : 27
- Index Full Scan : 13882
SQL> set autot off
SQL> select count(*) all_emp
2 ,count(case when sal>=5000 then 1 end) over_5000
3 ,round(count(case when sal>=5000 then 1 end) / count(*) * 100) ratio
4 from t_emp;
ALL_EMP OVER_5000 RATIO
---------- ---------- ----------
14000 1000 7
SQL>
- 최종 결과 집합에 해당하는 레코드 비율: 7%
- sal 조건을 만족하는 레코드가 압쪽에 몰려있거나 arraySize가 아주 작을대만 이점
CBO / RBO 동작 비교
SQL> set autotrace traceonly exp
SQL> select /*+ first_rows */ * from t_emp
2 where sal>=5001
3 order by empno,no;
Execution Plan
----------------------------------------------------------
Plan hash value: 1175086354
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 500 | 21000 | 27 (4)| 00:00:01 |
| 1 | SORT ORDER BY | | 500 | 21000 | 27 (4)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| T_EMP | 500 | 21000 | 26 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("SAL">=5001)
SQL>
- 컬럼 히스토그램 생성하였으므로 “ sal>=5001 “이 없다는 사실은 이미 알고 있음
SQL> select max(sal) from scott.emp;
MAX(SAL)
----------
5000
SQL>
RBO 모드로 실행
SQL> select /*+rule */ * from t_emp
2 where sal>=5001
3 order by empno, no;
Execution Plan
----------------------------------------------------------
Plan hash value: 1185322641
------------------------------------------------
| Id | Operation | Name |
------------------------------------------------
| 0 | SELECT STATEMENT | |
|* 1 | TABLE ACCESS BY INDEX ROWID| T_EMP |
| 2 | INDEX FULL SCAN | T_EMP_PK |
------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("SAL">=5001)
Note
-----
- rule based optimizer used (consider using cbo)
SQL>
- Index Full Scan을 선택
- 결론
- first_rows가 RBO보다 낫긴해도 완벽한 비용에 근거 하지 않기 때문에 불리한 결정을 할수도있음
FIRST_ROWS_N
- n개의 로우만 fetch하는것을 전제로 가장 빠른 응답 속도를 낼수 있는 실행계획을 선택
- n으로 지정할수 잇는 값은 1,10,100,1000등
- n개 로우 이상을 Fetch하면 오히려 더많은 리소스를 사용하여 더 느려질수 있음
alter session set optimizer_mode=first_rows_100;
select /*+ first_rows(100) */ * from t where …;
- first_rows와 달리 first_rows_n은 완전한 CBO모드로 작동
SQL> select count(*) all_emp
, count(case when sal>=2000 then 1 end) over_200
, round(count(case when sal>=2000 then 1 end) / count(*) * 100) ratio
from t_emp; 2 3 4
ALL_EMP OVER_200 RATIO
---------- ---------- ----------
14000 6000 43
SQL>
- sal>=2000 인 사원은 6,000명중 43% 차지
- 일정량 이상을 Fetch하는 순간 오히려 Table Full scan보다 비용이 커짐
/*+ first_rows(10) */
SQL> set autot traceonly exp;
SQL> select /*+ first_rows(10) */ * from t_emp
where sal>=2000
order by empno,no; 2 3
Execution Plan
----------------------------------------------------------
Plan hash value: 1185322641
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 11 | 462 | 28 (0)| 00:00:01 |
|* 1 | TABLE ACCESS BY INDEX ROWID| T_EMP | 5999 | 246K| 28 (0)| 00:00:01 |
| 2 | INDEX FULL SCAN | T_EMP_PK | 26 | | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("SAL">=2000)
/*+first_rows(100) */
SQL> select /*+first_rows(100) */ * from t_emp
where sal>=2000
order by empno,no;
2 3
Execution Plan
----------------------------------------------------------
Plan hash value: 1175086354
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 5999 | 246K| | 93 (2)| 00:00:02 |
| 1 | SORT ORDER BY | | 5999 | 246K| 392K| 93 (2)| 00:00:02 |
|* 2 | TABLE ACCESS FULL| T_EMP | 5999 | 246K| | 26 (0)| 00:00:01 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("SAL">=2000)
SQL>
- first_rows(10)
- Index Full Scan
- first_rows(100)
- Table Full Scan
- 비용을 고려해 실행계획을 선택
CHOOSE
- 액세스 되는 테이블 중 적어도 하나에 통계정보가 있다면 CBO (all_rows) 모드 선택
- 통계정보가 업으면 RBO 선택
- 9i 까지는 CHOOSE가 기존설정
- 10g 부터 all_rows가 기본모드
- 10g부터 rbo를 공식지원하지 않고 동적 샘플링 기본레벨이 2로적용
- 옵티마이저 모드 선택
- first_rows
- 일반적인 OLTP 환경에 적합
- SQL 결과 집합중 일부만 Fetch하고 멈추는 것을 전제로 가장 효율적인 실행계획을 요구
- 2-Tier 환경의 클라이언트/서버 구조에 적합
- 전체 결과 집합이 아무리 많아도 사용자가 스크롤을 통해 일부만 Fetch하다가 멈출수 있음
- 전체 Fetch하거나 다른 쿼리를 수행하기 전까지 SQL커서는 오픈된 상태를 유치
- all_rows
- DW나 배치 프로그램
- sql 결과 집합을 모두 Fetch하기에 가장 효율적인 실행계획을 옵티마이저에게 요구
- OLTP중 웹 애플리케이션 등
- 3-Tier구조는 클라이언트와 서버 간 연결을 지속하지 않는 환경이며 오픈 커서를 계속 유지 할수 없음
- rownum으로 결과집합을 10건 내지 20건으로 제한, 집합자체를 소량으로 정의
- 애플리케이션 특성상 first_rows가 적합하다는 판단이 서지 않으면 all_rows를 기본모드로 선택
- 필요시 쿼리또는 세션레벨에서 first_rows모드로 전환할것을 권고
- 오라클 고도화 원리와 해법 2 (bysql.net 2011년 1차 스터디)
- 작성자: 남송휘 (tofriend)
- 최초작성일: 2011년 4월 17일
- 본문서는 bysql.net 스터디 결과입니다 .본 문서를 인용하실때는 출처를 밝혀주세요. http://www.bysql.net
- 문서의 잘못된 점이나 질문사항은 본문서에 댓글로 남겨주세요. ^^
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| » |
1. 옵티마이저
| 휘휘 | 2011.04.17 | 6761 |
| 34 | 3. 옵티마이저의 한계 - P | 휘휘 | 2011.04.17 | 4439 |
| 33 | 2. 옵티마이저 행동에 영향을 미치는 요소 | balto | 2011.04.17 | 6991 |
| 32 | 3. 옵티마이저의 한계 | 휘휘 | 2011.04.19 | 7204 |
| 31 |
4. 통계정보 Ⅰ
| 토시리 | 2011.04.24 | 16880 |
| 30 | 6. 히스토그램 | 오예스 | 2011.04.25 | 18566 |
| 29 | 5. 카디널리티 | 오라클잭 | 2011.04.26 | 13753 |
| 28 |
7. 비용
| balto | 2011.05.01 | 5839 |
| 27 | 8. 통계정보 Ⅱ | AskZZang | 2011.05.04 | 6496 |
| 26 | 1. 쿼리 변환이란? | 운영자 | 2011.05.16 | 6762 |
| 25 | 3. 뷰 Merging | 오라클잭 | 2011.05.17 | 6577 |
| 24 | 2. 서브쿼리 Unnesting | 토시리 | 2011.05.17 | 2798 |
| 23 |
5. 조건절 이행
| balto | 2011.05.29 | 6114 |
| 22 | 4. 조건절 Pushing | 오예스 | 2011.05.31 | 24756 |
| 21 | 6. 조인 제거 | AskZZang | 2011.06.01 | 6109 |
| 20 | 7. OR-Expansion | AskZZang | 2011.06.01 | 9109 |
| 19 | 12. 기타 쿼리 변환 | 휘휘 | 2011.06.05 | 3923 |
| 18 | 10. 실체화 뷰 쿼리로 재작성 | 오라클잭 | 2011.06.07 | 10674 |
| 17 | 11. 집합 연산을 조인으로 변환 | 오라클잭 | 2011.06.07 | 5695 |
| 16 |
2. 소트를 발생시키는 오퍼레이션
| balto | 2011.06.11 | 5635 |