매주 각 스터디 팀원들이 담당 분량을 정리해서 올리고 토론식으로 진행합니다.
스터디 포스팅은 팀원들에의해 이루어지지만 스터디 참여는 사이트 회원 모두가 가능합니다.
진행기간: 2009.07 ~ 2009.10. 종료
제2부 2장 조인의 최적화 방안
2009.09.06 14:26
495~513 페이지 까지의 내용입니다. ^^
제2부 2장 조인의 최적화 방안
관계형 DB는 집합의 개념의로 자료를 처리하여 그 형태 및 연산자의 활용에의해 다양하게 사용되어질수 있으며
각 테이블간의 물리직 연결과는 산관없이도 조인에 의해 자료의 연결이 쉽게 이루어질수있다
하지만 조인의 무분별한 사용은 수행속도의 문제를 가져올수 있으므로 조인의 구체적인 처리 절차와 핵세스 효율등을 알아야한다.
2.1. 조인과 반복 연결(LOOP QURY) 비교
join은 다양한 처리방법을 가지고 있고 그 처리방법에 따라 수행시간의 차이가 많이 나타날수 있다.
loop의경우 비교형식으로 처리되기 때문에 예상과 비슷한 시간을 확보할수 있다. 하지만
정확한 join의 처리방법을 활용하여 처리하면 loop와는 비교할수 없는 속도 향상을 가져올수 있다.
그러므로 데이터 처리의 대부분을 조인을 통해 declare에서 처리하고, 아주 특수한 경우의 처리만 loop에서 처리하도록 하는것이
최선의 방법중 하나라 할수 있다.
2.1.1. 전체 범위 처리 방식에서의 비교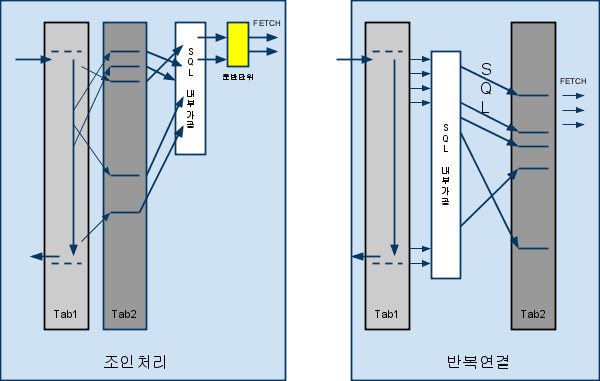
예1)
[조인처리]
SELECT A.FLD1, ... ,B.COL1,...
FROM TAB2 B, TAB1 A
WHERE A.KEY1=B.KEY2
AND A.FLD1='10'
ORDER BY A.FLD2;
TAB1의 FLD1='10' 인것만 전체 스캔후 TAB2를 모두 연결한후
FLD2로 ORDER BY 한후 운반단위 만큼 추출
(FLD1='10' 이 1000건이면 이면 1000회의 연결이 일어난후 정렬)
[반복연결]
(1)
SELECT FLD1, .. ,FLDn
FROM TAB1
WHERE FLD='10'
ORDER BY FLD2;
(2)
SELECT COL1, ...,COLn
FROM TAB2
WHERE KEY2 = :a.KEY1;
TAB1을 1000건 읽어온후 ORDER BY 한후
TAB2의 필요한 운반단위만큼만 수행
[인라인뷰처리]
SELECT x.FLD1, ...., x.FLDn, y.COL1,....,y.COLn
FROM (SELECT FLD1, ...., FLDn
FROM TAB1
WHERE FLD ='10'
ORDER BY FLD2) x, TAB2 y
WHERE y.KEY2=x.KEY1;
인라인뷰로 FLD='10'인것을 FLD2로 모두 정렬후 조인수행
예2)
[조인연결]
SELECT b.부서명, sum(a.매출액)
FROM TAB1 a, TAB2 b
WHERE a.부서코드 = b.부서코드
AND a.매출일 like '200503%'
GROUP BY B.부서명;
두테이블을 전체범위로 조인한후 GROUP BY를 하여 운반단위 만큼 추출
[반복연결]
(1) SELECT 부서코드, SUM(매출액)
FROM TAB1
WHERE 매출일 LIKE '200504'
GROUP BY 부서코드;
(2) SELECT 부서명
FROM TAB2
WHERE 부서코드 = :a.부서코드;
tab1으로 group by한 결과를 tabw의 필요한 부분만 가져와서 처리
tab2의 액세스 양이 줄어듬
[인라인뷰처리]
SELECT x.부서크도, y.부서명, 매출액
FROM (SELECT 부서코드 , SUM(매출액) 매출액
FROM TAB1
WHERE 매출일 LIKE '200503%'
GROUP BY 부서코드 ) x, TAB2 y
WHERE y.부서코드 = x.부서코드;
두 테이블(집합)의 관계가 1:M 일때
조인처리는 두테이블의 조인후 M집합으로 만든후 처리하며
반복연결은 M집합처리후 필요한 자료만 액세스하여 처리하여 조인이 비효율적일수있어나
인라인뷰등의 대체수단을 활용한다면 같은 형태의 액세스로 만들어 처리할수 있다.
하지만 관계형 DBMS의 집합개념은 경우에 따라 반복연결이 더 효율적일수있으므로
각 집합간의 관계를 잘 파악후 사용하여야 한다.
2.1.2. 부분범위 처리방식에서의 비교
부분처리로 처리하는경우 운반단위가 채워질 때까지만 연결작업이 일어나며
반복연결 역시 필요한 자료의 양만큼 수행하고 멈출수 있으므로 형태면에서 큰차이가 없을수 있다.
하지만 조인의 경우 한번의 SQL 처리가 수행되어지는 반면
반복연결은 연결시 마다 SQL이 수행된다.
이는 조인이 SQL 내에서 연결한 테이블의 컬럼을 마듬대로 가공하여 사용하는데 반해
반복연결은 별도의 언어를 통해 추가적인 가공을 해야하므로 사용면이나
속도면에서 조인이 유리 할수 있다.
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 5 | 4.1.6. 인덱스 선정 절차 | 휘휘 | 2009.08.23 | 103315 |
| 4 |
4.2. 클러스터링 형태의 결정 기준
| balto | 2009.08.26 | 100475 |
| 3 | 스터디 참고자료 ~! [3] | tofriend | 2009.06.30 | 116889 |
| 2 | 제2부 1.4.7. 저장형 함수를 이용한 부분 범위 처리 | 휘휘 | 2009.09.06 | 82048 |
| » |
제2부 2장 조인의 최적화 방안
| 휘휘 | 2009.09.06 | 99303 |