5. Fetch Call 최소화
2010.07.05 01:30
- 부분범위처리 원리
- OLTP 환경에서 부분범위 처리에 의한 성능 개선원리
- Array Size 조정에 의한 Fetch Call 감소 및 블록 I/O 감소 효과
- 프로그램 언어에서 Array 단위 Fetch 기능 활용
(1) 부분범위 처리 원리
SQL> insert into t
2 select *
3 from (
4 select rownum x, rownum y
5 from dual
6 connect by level <= 5000000
7 )
8 order by dbms_random.value
9 ;
5000000 rows created.
SQL> alter table t add
2 constraint t_pk primary key (x);
Table altered.
SQL> set arraysize 5
SQL> set timing on
SQL> select /*+ index(t t_pk) */ x, y
2 from t
3 where x > 0
4 and y <= 6 ;
X Y
---------- ----------
1 1
2 2
3 3
4 4
5 5...................... 장시간 경과
6 6
경과: 00:00:33.25 <-교제
실테스트: 1시간경과 결과출력되지 않음 ( P3 700, ORACLE XE) ㅡㅡ;
- x,y 두 컬럼의 값이 같고, x 만으로 인덱스가 생성
- arraysize (or fetch size) 를 5로 하였으므로
- 위결과값으로 나태낼수 있는 총수 6 개중 5개만 우선출력(첫번째 fetch) 후
- 나머지 값전체를 검색한후 나머지 6을 출력후 종료 (두번째 fetch)
- 부분범위처리
- 쿼리 결과집합을 전송할때 전체 데이터를 연속적으로 처리하지 않고 사용자의 Fetch Call에 따라 일정양씩 나누어서 전송하는 것
- 적정 운반단위 (arraysize)는 각 자료의 양과 필요양에 따라 적절하게 선택되어져야함
(2) OLTP 환경에서 부분범위 처리에 의한 성능개선 원리
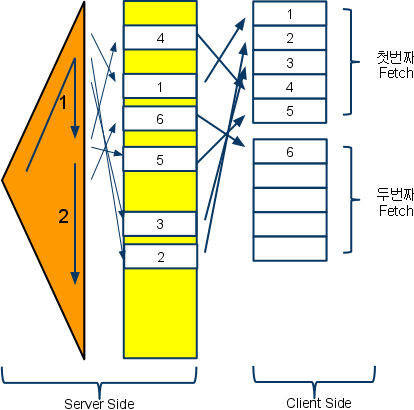
- x>0 and y<=6’ 조건으로 쿼리를 수행
- 첫번재 Fetch Call
- 인덱스를 통해 1부터 5까지를 전송받아 array 버퍼에 담아 전송하고 Clinet는 출력
- 두번째 Fetch Call
- 'x>0 and y<=6' 의 나머지 조건을 찾기 위해 (6 이마지막이라는 것을 오라클은 알수없음)
- 나머지 전체 레코드를 검색한후 전송.
- (이때 전체 Row가 많다면 결과적으로 1개의 Row때문에 전체 레코드를 검색한후 출력하게되는 문제가 발생)
- OLTP 성 업무에서 출력대상건이 많아 빨리 Array를 채우수 있다면 그만큼 성능이 빨라지게 할수있음
참고) One-Row Fetch
SQL*Plus를 사용하게 되면 Array size에 상관없이 첫번째 Row를 Fetch하는 과정이 추가됨
쿼리 툴마다 다른 방식으로 Fetch 하므로 이에 관해 확실히 확인할 필요가 있음
(3) ArraySize 조정에 의한 Fetch Call 감소 및 블록I/O 감소 효과
- 대량의 데이터를 처리할때 ArraySize를 크게 설정할수록
- Fetch Call 횟수가 줄어 네트워크 부하가 감소하고 쿼리 성능이 향상되고
- 서버프로세스가 읽을 블록 개수가 줄어들게된다.
ArraySize Fetch Count
(SQL *Net roundtrips)Block I/O 2 6107 6281 5 2644 2575 10 1223 1365 20 612 764 50 246 400 100 124 279 200 63 220 500 26 183 1000 14 171 2000 8 165 5000 4 161
- ArraySize 100부터 block i/o가 큰변화가 없으므로 100정도가 성능상 유리
- 10개의 행으로 구성된 3개의 블록이 있다고 한다면
- 총 30개의 레코드를 대상으로 쿼리가 수행되고 ArraySize가 3이라면
- 3개씩 10번의 Fetch가 일어나게 되고
- I/0는 각블록별로 3+3+3+1 / 2+3+3+2 / 1+3+3+3 의 형태로 레코드를 가져가므로
- 총 12번의 블록 i/o가 발생한다 .
- Arraysize가 10이라면 3번(10 + 10 + 10 ) 의 블록I/O 만 발생
(4) 프로그램 언어에서 Array 단위 Fetch 기능 활용
- PL/SQL 에서 커서를 열고 레코드를 Fetch
- 9i까지는 한번에 한로우만 처리
- 10g부터는 자동으로 100개씩 Array Fetch (단 Cursor FOR Loop일경우)
SQL> conn scott/tiger;
Connected.
SQL> create table big_table
2 as
3 select level object_name from dual
4 connect by level <2000;
Table created.# Implicit Cursor For Loop
SQL> declare
2 l_object_name big_table.object_name%type;
3 begin
4 for item in ( select object_name from big_table where rownum <= 1000 )
5 loop
6 l_object_name := item.object_name;
7 dbms_output.put_line(l_object_name);
8 end loop;
9 end;
10 /
PL/SQL procedure successfully completed.# Explicit Cursor For Loop
SQL> declare
2 l_object_name big_table.object_name%type;
3 cursor c is select object_name from big_table where rownum <= 1000;
4 begin
5 for item in c
6 loop
7 l_object_name := item.object_name;
8 dbms_output.put_line(l_object_name);
9 end loop;
10 end;
11 /PL/SQL procedure successfully completed.
**** 실행결과 tkprof 파일 (for1.prt )
declare
l_object_name big_table.object_name%type;
begin
for item in ( select object_name from big_table where rownum <= 1000 )
loop
l_object_name := item.object_name;
dbms_output.put_line(l_object_name);
end loop;
end;
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.18 0 0 0 0
Execute 1 0.01 0.06 0 0 0 1
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2 0.01 0.24 0 0 0 1
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 41
********************************************************************************
SELECT OBJECT_NAME
FROM
BIG_TABLE WHERE ROWNUM <= 1000
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.05 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 11 0.00 0.15 5 13 0 1000
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 13 0.00 0.21 5 13 0 1000
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 41 (recursive depth: 1)
Rows Row Source Operation
------- ---------------------------------------------------
1000 COUNT STOPKEY (cr=13 pr=5 pw=0 time=161155 us)
1000 TABLE ACCESS FULL BIG_TABLE (cr=13 pr=5 pw=0 time=156135 us)
********************************************************************************
declare
l_object_name big_table.object_name%type;
cursor c is select object_name from big_table where rownum <= 1000;
begin
for item in c
loop
l_object_name := item.object_name;
dbms_output.put_line(l_object_name);
end loop;
end;
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.05 0 0 0 0
Execute 1 0.00 0.00 0 0 0 1
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2 0.01 0.05 0 0 0 1
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 41
********************************************************************************
SELECT OBJECT_NAME
FROM
BIG_TABLE WHERE ROWNUM <= 1000
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.01 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 11 0.00 0.00 0 13 0 1000
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 13 0.00 0.01 0 13 0 1000
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 41 (recursive depth: 1)
Rows Row Source Operation
------- ---------------------------------------------------
1000 COUNT STOPKEY (cr=13 pr=0 pw=0 time=7145 us)
1000 TABLE ACCESS FULL BIG_TABLE (cr=13 pr=0 pw=0 time=3128 us)
일반 커서 사용
SQL> declare
2 cursor c is
3 select object_name
4 from big_table where rownum <= 1000;
5 l_object_name big_table.object_name%type;6 begin
7 open c;
8 loop
9 fetch c into l_object_name;
10 exit when c%notfound;
11 dbms_output.put_line(l_object_name);
12 end loop;
13 close c;
14 end;
15 /
PL/SQL procedure successfully completed.**** 실행결과 tkprof 파일 (for2.prt )
declare
cursor c is
select object_name
from big_table where rownum <= 1000;
l_object_name big_table.object_name%type;
begin
open c;
loop
fetch c into l_object_name;
exit when c%notfound;
dbms_output.put_line(l_object_name);
end loop;
close c;
end;
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.17 0 0 0 0
Execute 1 0.10 0.19 0 0 0 1
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2 0.11 0.37 0 0 0 1
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 41
********************************************************************************
SELECT OBJECT_NAME
FROM
BIG_TABLE WHERE ROWNUM <= 1000
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1001 0.02 0.02 0 1002 0 1000
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 1003 0.02 0.02 0 1002 0 1000
Misses in library cache during parse: 0
Optimizer mode: ALL_ROWS
Parsing user id: 41 (recursive depth: 1)
Rows Row Source Operation
------- ---------------------------------------------------
1000 COUNT STOPKEY (cr=1002 pr=0 pw=0 time=18310 us)
1000 TABLE ACCESS FULL BIG_TABLE (cr=1002 pr=0 pw=0 time=13257 us)
- Cursor FOR Loop 가 아닌 커서를 이용할경우 Array 단위 Fetch가 일어나지 않음
- JAVA에서는 setFetchSize를 사용하여 조정가능
* 본문서의 테스트환경
Oracle Xe, Ubuntu ,P3 700
댓글 0
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 27 | 8. 애플리케이션 커서 캐싱 | 토시리 | 2010.06.29 | 18880 |
| 26 | 9. Static vs. Dynamic SQL [1] | balto | 2010.07.03 | 29568 |
| 25 | 10. Dynamic SQL 사용 기준 | balto | 2010.07.03 | 19898 |
| 24 |
11. Static SQL 구현을 위한 기법들
| 실천하자 | 2010.07.04 | 20944 |
| 23 |
4. Array Processing 활용
| 휘휘 | 2010.07.04 | 36504 |
| 22 | 1. Call 통계 | 실천하자 | 2010.07.04 | 20014 |
| » |
5. Fetch Call 최소화
| 휘휘 | 2010.07.05 | 28528 |
| 20 | 5장. 데이터베이스 Call 최소화 원리 | 휘휘 | 2010.07.05 | 17727 |
| 19 |
2. User Call vs. Recursive Call
| 토시리 | 2010.07.07 | 20557 |
| 18 |
3. 데이터베이스 Call이 성능에 미치는 영향
| 토시리 | 2010.07.07 | 22974 |
| 17 | 6장. I/O 효율화 원리 | 휘휘 | 2010.07.07 | 18092 |
| 16 |
4. Prefetch
| balto | 2010.07.10 | 40387 |
| 15 |
5. Direct Path I/O
| balto | 2010.07.10 | 23595 |
| 14 | 8. PL/SQL 함수 호출 부하 해소 방안 | 토시리 | 2010.07.11 | 25660 |
| 13 | 6. 페이지 처리의 중요성 | 실천하자 | 2010.07.11 | 18463 |
| 12 | 2. Memory vs. Disk I/O | 휘휘 | 2010.07.11 | 18843 |
| 11 | 3. Single Block vs. Multiblock I/O | 휘휘 | 2010.07.11 | 18846 |
| 10 | 7. PL/SQL 함수의 특징과 성능 부하 | 실천하자 | 2010.07.12 | 24012 |
| 9 |
1. 블록 단위 I/O
| 토시리 | 2010.07.12 | 20732 |
| 8 |
1. Library Cache Lock
| balto | 2010.07.17 | 24274 |