3.1. SQL과 옵티마이져 (3/3) (3.1.3 ~ 3.1.5)
2010.10.07 18:21
3.1.3. 옵티마이져의 최적화 절차
- 옵티마이져의 궁극적 목표 : 사용자의 요구 결과를 가장 최소의 자원으로 처리 (수학적, 통계적, 논리적)
1. 데이터 사전 파싱 (일차적으로 잠정적 실행계획 생성)
2. 1번의 통계정보 기반으로 실행계획 비용 계산
- 데이터 분포도와 테이블의 저장 구조의 특성, 인덱스 구조, 파티션 형태, 비교 연산자 등 감안
- 계산 비용값 : 특정 실행 계획 수행 시 사용될 기대값에 대한 일종의 예상 계수 (절대값이 아님)
3. 가장 최소 비용의 실행계획 선택
※ 항상 최선의 결정이 아니므로, 상황에 따라 옵티마이져의 결정을 제어 & 힌트 사용 등으로 옵티마이져 선택 조정
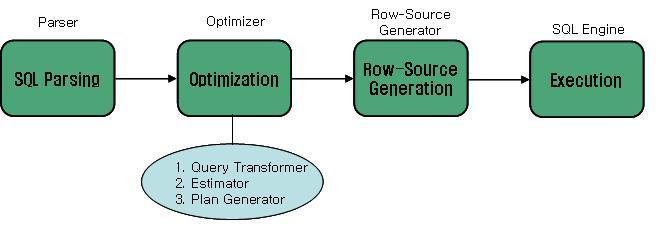
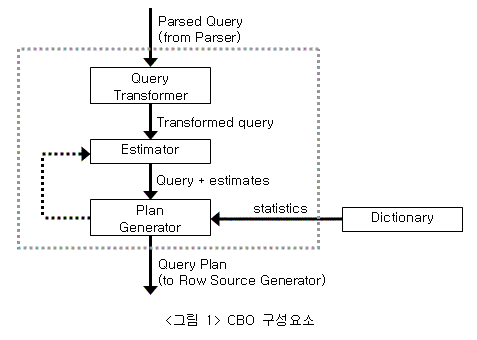
가) 질의 변환기 : 보다 양호한 실행계획을 얻을 수 있도록 적절한 형태로 SQL 모양 변환
- 뷰병합 : 뷰 정의 시에 지정한 쿼리(뷰쿼리)를 실제로 액세스를 수행하는 쿼리(액세스쿼리)에 병합해 넣는 방식
- 조건절 진입 : 뷰 병합을 할 수 없는 경우 뷰 쿼리 내부에 액세스 쿼리의 조건절을 진입시키는 방식
- 서브쿼리 비내포화 : 내포관계를 해제하는 방법 사용 or 조인형식으로 서브쿼리 변환
- 실체뷰의 쿼리 재생성 : 실체뷰는 뷰쿼리로 정의되지만 실제로 물리적 데이터 저장, 옵티마이져가 가장 최적의 물리적 집합을 처리하도록 쿼리 재생성
- OR 조건의 전개 : OR 조건연산자를 각각 여러 개의 단위 쿼리로 분기하고 UNION ALL로 연결하는 질의 변환 수행
- 사용자 정의 바인드 변수 엿보기 (Peeking) : 최초 수행될 때 적용 되었던 값을 이용해 실행계획 수립 후 공유
나) 비용 산정기
- 선택도 (Selectivity) : 처리할 대상 집합에서 해당 조건을 만족하는 로우가 차지하는 비율
- 대상집합 : 테이블 , 뷰, 중간집합
- 판정단위 : 개별 컬럼 X, 액세스 주관 조건 모임
- 옵티마이저가 통계정보 활용, 통계정보가 없을 시 고르게 분포햇다는 가정으로 계산
- 범위 : 0.0 ~ 1.0 (0% ~ 100%) ☞ 선택도가 낮을 수록 변별력 증가
※ 각 개별 선택도 이용으로 통계학적 연산하기 때문에 결합 선택도 산정으로 오차 발생
선택도는 '=' 기준의 계산처리로 범위 조건 처리 시 오차 ↑
- 카디널러티 (Cardinality) : 판정 대상이 가진 결과 건수 or 다음 단계 중간결과 건수
Cardinality = Selectivity * Num_Rows
※ 선택도(비율)만으로 판단하지 않은 이유 : 100만개의 1% 와 100개의 1% 절대량의 차이
∵ 대상 집합에 따라 차이 발생 (같은 집합 내 처리 시 문제가 되지 않음)
- 비용 (Cost) : 실행계획상 각 연산들이 수행 시 소용되는 시간 비용을 상대적으로 계산한 예측치
- 대상 : 스키마 객체에 대한 통계정보 & CPU & 메모리 상황 & 디스크 I/O 비용
※ 불완전 가정으로 한계 발생 (수많은 가정으로 다양한 계산식 적용을 옵티마이저가 하지만 항상 옳지 않음)
☞ 다양한 힌트, 다양한 초기화 파라메터
다) 실행계획 생성기 : 주어진 쿼리를 처리할 수 있는 적용 가능한 실행계획 선별 및 검토하여 가장 최소의 비용 선택
∵ 결과는 같으나 생핼계획에 따라 처리의 효율성 차이
- 조인 : 실행계획 복잡성↑, 중요성↑ ('제2부 2장 조인의 최적화 방안' 자세한 소개)
- 부속 서브쿼리 / 병합이 불가능한 뷰 : 실행계획 우선 생성 (∵ 제공 결과에 따라 메인 쿼리 영향)
- 처리단위(Query Block)는 하위 단위부터 최적화 ☞ 가장 깊숙한 부분부터 우선적 최적화 수행
- 최적화가 완료된 후 가장 바깥쪽에 위치한 처리 다뉘는 전체 처리를 수행한 결과
- 논리적 존재 모든 것에 대해 시도 X ☞ 시간 제한성 (쿼리에 따라 다름 ex. 1초 수행 쿼리 & 1시간 수행 쿼리)
- 지능적 기술
- 적응적 탐색 (Adaptive Search) : 쿼리 수행 예상 총 시간에 비해 최적화 소요 시간이 일정 비율이 넘지 않는 탐색 전략
- 경험적(Heuristic)기법에 의한 초기치 선택(Cutoff) : 탐색 도중에 최적이라 판단 시 멈추고 실행계획 선택
- 힌트 필요 (옵티마이저의 최적화 보다 향상된 실행 계획 설정)
3.1.4. 질의의 변환 (Query Transforming)
- 옵티마이져는 가능한 모든 수식의 값을 미리 구함 (1 → 2)
- 비교연산자의 추가적 연산은 연산자를 좌우로 이동시켜 단순화 하지 않음 (3)
- sales_qty > 1200 / 12
- sales_qty > 100
- sales_qty * 12 > 1200
- LIKE 절에 '%' 나 '_' 사용하지 않을 시 '=' 연산으로 조건절 단순화 (단, 고정길이 데이터형에서는 사용 X)
- job LIKE 'SALESMAN'
- job = 'SALESMAN'
- IN 비교 연산자 : OR 논리 연산자 이용으로 여러 개의 '='로 된 같은 기능 조건절로 확장
- job IN ('CLERK', 'MANAGER')
- job = 'CLERK' OR job = 'MANAGER'
- ANY / SOME 연산자 일반적 조건식 : '=' 비교연산자와 OR 논리 연산자를 이용해 같은 기능 조건절로 확장
- sales_qty > ANY (:in_qty1, : in_qty_2)
- sales_qty > : in_qty1 OR sales_qty > : in_qty2
- ANY / SOME 연산자 서브쿼리 조건식 : EXISTS 연산자를 이용한 서브쿼리로 변환
- WHERE 100000 > ANY (SELECT sal FROM emp WHERE job = 'CLERK')
- WHERE EXISTS (SELECT sal FROM emp WHERE job = 'CLERK' AND 100000 > sal)
- ALL 연산자 일반적 조건식 : '=' 비교연산자와 AND 논리 연산자를 이용해 같은 기능 조건절로 확장
- sales_qty > ALL (:in_qty1, : in_qty_2)
- sales_qty > : in_qty1 AND sales_qty > : in_qty2
- ALL 연산자 서브쿼리 조건식 : NOT ANY로 변환 후 다시 EXISTS 연산자를 이용한 서브쿼리로 변환 (1 → 2 → 3)
- WHERE 100000 > ALL (SELECT sal FROM emp WHERE job = 'CLERK')
- WHERE NOT (100000 <= ANY (SELECT sal FROM emp WHERE job = 'CLERK'))
- WHERE NOT EXISTS (SELECT sal FROM emp WHERE job = 'CLERK' AND 100000 <= sal)
- BETWEEN 비교 연산자 조건식 : '>=' 와 '<=' 비교 연산자를 이용한 조건절로 변환
- sales_qty BETWEEN 100 AND 200
- sales_qty >= 100 AND sales_qty <= 200
- NOT 논리 연산자 일반적 조건식 : NOT을 제거할 수 있는 반대 비교 연산을 찾아 대체 (1 → 2 → 3)
- NOT (sal <30000 OR comm IS NULL)
- NOT sal <30000 AND comm IS NOT NULL
- sal >= 30000 AND comm IS NOT NULL
- NOT 논리 연산자 서브쿼리 조건식 : NOT을 제거할 수 있는 반대 비교 연산을 찾아 대체
- NOT deptno = (SELECT deptno FROM emp WHERE empno = 7689)
- deptno <> (SELECT deptno FROM emp WHERE empno = 7689)
- 3단 논법 원칙을 적용 하는 이행
WHERE col1 비교연산자 상수
AND col1 = col2
▷
WHERE col1 비교연산자 상수
AND col2 비교연산자 상수
→ 3단 논법 원칙을 적용 하는 이행은 비용기준 옵티마이져를 사용할 때만 적용
→ 조인 시 어떤 쪽이 보다 많은 처리범위를 먼저 줄여서 처리양을 결정하는 중요 요소
→ Nested Loops 조인시 선행처리 부분에 조건을 최대한 부여하여 처리량 ↓
- Sort Merge 조인이나 해쉬 조인 시 각각 집합을 최대한 줄이도록 조건 부여 (옵티마이져가 논리적으로 추론)
- 옵티마이져는 이행성 규칙에 의한 변환을 보다 효율적이라 판단될 때만 수행
3.1.4.2. 뷰병합 (View Merging)
- 뷰쿼리
- 뷰 생성 시 사용된 SELECT 문
- 액세스쿼리
- 뷰를 수행하는 SQL (인라인뷰 외곽의 SELECT)
- 병합방법
- 뷰병합(View Merging) : 뷰쿼리를 액세스쿼리에 병합해 넣는 방식
- 조건절 진입(Predicate pushing) : 뷰병합을 할 수 없을 시 뷰쿼리 내부에 액세스 쿼리의 조건절 진입
- 병합 (액세스쿼리 기준)
- 액세스 쿼리를 기준으로 뷰쿼리에 있는 대응인자들을 병합
- 병합 (뷰쿼리 기준)
- 액세스쿼리에 있는 조건들을 뷰쿼리에 진입
(교재 p.169 ~ 참조)
3.1.4.3. 사용자 정의 바인드 변수의 엿보기 (Peeking)
- 바인드 변수를 사용한 쿼리는 먼저 파싱과 최적화가 이루어진 후에 바인드 변수에 바인딩이 이루어짐
☞ 최적화를 하는 시점에 변수로 제공되는 컬럼에 바인딩값에 대한 통계정보 사용 X (일반적으로 균일한 분포로 가정 처리)
☞ PEEKING (최초 파싱이 일어 날 시 한번만 적용)
- 바인드 변수를 사용한 쿼리가 처음 실행될 때 옵티마이져는 사용자가 지정한 바인드 변수 값을 살짝 커닝함으로써 선택도 확인
- 장단점 발생 ☞ 파라메터 사용 (_OPTIM_PEEK_USER_BINDS), 기본값 : TRUE
※ 참고 ☞ http://bysql.net/?document_srl=5560
3.1.5. 개발자의 역할
- SQL 활용을 잘해라!
- SQL의 수행 형식 및 수행 결과를 어느정도 파악(수행 시 심각성 고려)해라!
- 옵티마이져에 대한 정확히 이해 필요!
뷰병합 참고하세요.
http://www.gurubee.net/pages/viewpage.action?pageId=6259610
출처 : 오라클 클럽
내용 (주)비투엔컬설팅 '오라클 성능 고도화 원리와 해법II'
?ㅎㅎ 오라클클럽 트위터를 통해서 자료를 봤는데
예전 스터디원이었던 이창헌씨가 작성한 자료더군요~^^