1. 인덱스 구조
2011.02.16 13:19
1. 인덱스 구조
- 인덱스
- 정의 : 대용량 테이블에서 필요한 데이터만 빠르고 효울적 엑세스 목적의 오브젝트
- 특징 : 키 컬럼 순으로 정렬
- 범위 스캔(Range Scan)
- 정의 : 특정 위치에서 스캔을 시작하여 검색조건에 일치하지 않는 값을 만나는 순간 멈춤 (인덱스 특징 이용)
※ 참고
- 테이블 범위 스캔이 가능한 경우 : IOT(Index-Organized Table) - 특정 컬럼 순으로 정렬 상태를 유지하며 값 입력
- 일반적 힙 구조 테이블(Heap-Organized Table)은 불가능
- B*tree 인덱스 구조
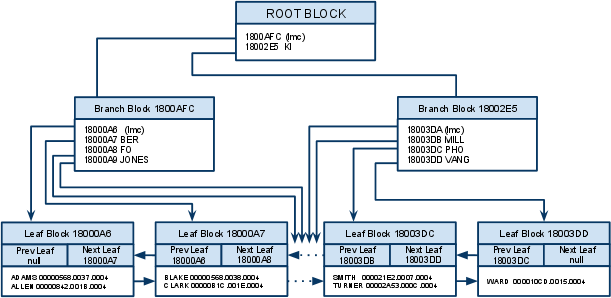
- 브랜치(Branch) 블록(Root 포함) 저장 엔트리
- 키 값, 하위 노드 블록을 찾아가기 위한 DBA(Data Block Address)정보 (단, lmc에는 키 값이 없음)
※ 참고 lmc (LeftMostChild) : 키 값을 가진 첫번째 엔트리보다 작은 값, 다른 엔트리와 별도 장소 저장
- 리프(Leaf) 블록
- 인덱스 키 컬럼, 주소정보(Rowid) (정렬 우선 순위 : 1. 인덱스 키 컬럼, 2. Rowid)
- 인덱스 특징
- 리프 노드상의 인덱스 레코드와 테이블 레코드는 1:1 관계
- 리프 노드상의 키 값과 테이블 레코드 키 값 서로 일치
- 브랜치 노드상의 레코드 개수는 하위 레벨 블록 개수와 일치
- 브랜치 노드상의 키 값은 하위 노드가 갖는 값의 범위 의미
※ 참고 테이블 레코드에서 값 갱신 시,
- 리프 노드 인덱스 키 값도 같이 갱신 (delete & insert)- 브랜치 노드 값이 바뀌지는 않음 (∵ 자신의 키 값과 하위 노드 블록 포인팅 정보로 값의 범위 스캔 시 활용)
- 브랜치 노드는 인덱스 분할(Split)에 의해 새로운 블록이 추가, 삭제(다른 브랜치의 자식 노드 이동)시 갱신
- 수평적 탐색 (= 범위 스캔)
- 리프 블록을 인덱스 레코드 간 논리적 순서에 따라 좌 → 우 or 우 → 좌 스캔
- 수직적 탐색
- 수평적 탐색을 위한 시작 지점을 찾는 과정 Root → Leaf 블록 (위에서 아래쪽으로 진행)
- "CLARK"을 찾는 과정 (위의 그림 참조)
1. 루트 블록 스캔
2. 왼쪽 브랜치 or 오른쪽 브랜치 방향 결정
☞ "CLARK" 은 "KI" 보다 작기 때문에 왼쪽 브랜치블록으로 이동
3. 브랜치 블록 스캔 (다음 인덱스 블록 탐색)
☞ "CLARK" 은 "BER" 보다 크고 "FO" 보다 작으므로 두 번째 레코드 블록 주소(18000A7)로 이동
4. 리프 블록까지 이동 ( 더이상 수직적 탐색 불가능 - 탐색 결과 有 / 無 )
☞ "CLARK" 을 찾아 수평적 탐색 (= 범위 스캔) 진행
5. 인덱스 리프 블록 스캔하면서 "CLARK" 일치 확인
6. 값이 "CLARK" 인 엔트리에서 ROWID (00000B1C.001E.0004)로 해당 테이블 레코드 이동 후 필요한 다른 컬럼의 값을 읽음
※ 쿼리에서 인덱스 컬럼만 필요 시 생략
7. 5,6번 과정 반복하다 검색조건에서 벗어나는 레코드를 만나는 순간 멈춤
ⅰ. 브랜치 블록 스캔
- 브랜치 블록 스캔 시 뒤에서부터 스캔하는 방식이 유리
- 오라클이 실제로 뒤쪽부터 스캔하는지는 모름
- 교재에서 인덱스 스캔과정 설명 시 뒤쪽부터 스캔으로 가정
- 수직적 탐색 진행 시, 찾고자 하는 값보다 키 값이 작은 엔트리를 따라 내려감
※ 참고 : 뒤에서부터 스캔하는 방식이 유리한 이유
ⅱ. 결합 인덱스 구조와 탐색
- 2개 이상의 컬럼이 결합 된 인덱스
- 결합 된 컬럼 작성 순으로 스캔
※ 예시 : EMP 테이블의 결합 인덱스
- 상황 1 : ( deptno + sal ) 컬럼 순으로 생성한 결합 인덱스
- 상황 2 : deptno = 20 and sal >= 2000 조건의 쿼리
☞ 먼저 deptno 조건 체크 후 sal 의 조건 체크 (∴ 결합 인덱스에서 컬럼의 순서 중요)
(4) ROWID 포맷
- 제한 ROWID 포맷
- 대상
- 오라클 7 버전까지의 ROWID
- 파티션되지 않은 일반 테이블에 생성한 인덱스 (오라클 8i 이후)
- 파티션된 테이블에 생성한 로컬 파티션 인덱스 (오라클 8i 이후)
- 구성 ( " . " 을 포함한 18자리 문자열 )
〔 블록 번호(8) 〕.〔 로우 번호(4) 〕.〔 데이터파일 번호(4) 〕
- 확장 ROWID 포맷
- 대상
- 파티션 테이블에 생성한 글로벌 파티션 인덱스 (오라클 8i 이후)
- 파티션 테이블에 생성한 비파티션 인덱스 (오라클 8i 이후)
- 구성 (18자리 문자열)
〔 데이터 오브젝트(6) 〕〔 데이터파일 번호(3) 〕〔 블록 번호(6) 〕〔 로우 번호(3) 〕
- 오라클 고도화 원리와 해법 2 (bysql.net 2011년 1차 스터디)
- 작성자: 위충환 (실천하자)
- 최초작성일: 2011년 02월 20 일
- 본문서는 bysql.net 스터디 결과입니다 .본 문서를 인용하실때는 출처를 밝혀주세요. http://www.bysql.net
- 문서의 잘못된 점이나 질문사항은 본 문서에 댓글로 남겨주세요. ^^
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 60 | 진행기록 | 운영자 | 2011.08.22 | 4471 |
| 59 | 1. 기본 개념 | 멋진넘 | 2011.06.28 | 14782 |
| 58 | 1. 테이블 파티셔닝 | suspace | 2011.06.21 | 8145 |
| 57 | 7장. 병렬 처리 | 운영자 | 2011.06.14 | 5770 |
| 56 | 6장. 파티셔닝 | 운영자 | 2011.06.14 | 4366 |
| 55 | 5장. 소트 튜닝 | 운영자 | 2011.06.14 | 4443 |
| 54 | 4장. 쿼리 변환 | 운영자 | 2011.06.14 | 4290 |
| 53 | 3장. 옵티마이저 원리 | 운영자 | 2011.06.14 | 4305 |
| 52 |
1. 소트 수행 원리
| 휘휘 | 2011.06.12 | 7070 |
| 51 | 1. 쿼리 변환이란? | 실천하자 | 2011.05.01 | 6284 |
| 50 |
1. 옵티마이저
| 실천하자 | 2011.04.17 | 12594 |
| 49 |
1. Nested Loops 조인
| suspace | 2011.03.22 | 11711 |
| 48 | 2장. 조인 원리와 활용 | 운영자 | 2011.03.22 | 4491 |
| » |
1. 인덱스 구조
[1] | 실천하자 | 2011.02.16 | 15372 |
| 46 | 1장. 인덱스 원리와 활용 | 운영자 | 2011.06.14 | 6768 |
| 45 |
온라인 OT 및 스터디 툴 사용 방법
| 휘휘 | 2011.02.16 | 4534 |
| 44 |
Front Page
| 운영자 | 2011.02.15 | 150593 |
| 43 | 2. 인덱스 기본 원리 | 실천하자 | 2011.02.20 | 4608 |
| 42 |
2. 소트 머지 조인
| 실천하자 | 2011.03.22 | 7210 |
| 41 | 2. 옵티마이저 행동에 영향을 미치는 요소 | 휘휘 | 2011.04.17 | 6466 |
새로쓴 대용량 DB 1권 중 인덱스 정보 ☞ http://bysql.net/?document_srl=6676