4. 테이블 Random 액세스 부하
2011.02.23 22:09
04. 테이블 Random 액세스 부하
(1) 인덱스 ROWID에 의한 테이블 액세스
쿼 리에서 참조되는 컬럼이 인덱스에 모두 포함되는 경우가 아니라면 인덱스 스캔 이후 '테이블 Random 액세스'가 일어난다. 실행계획에서는 ‘Table Access By index ROWID’ 부분을 말한다.
SELECT * FROM CR_BAD_TEST WHERE USER_SEQ = '10000'
-------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 159 | 4 (0) | 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| CR_BAD_TEST | 1 | 159 | 4 (0) | 00:00:01 |
|* 2 | INDEX RANGE SCAN | CR_BAD_USER_SEQ_IDX | 1 | | 3 (0) | 00:00:01 |
-------------------------------------------------------------------------------------------------------------
- 물리적 주소? 논리적 주소?
- rowid = 물리적 주소정보 = 오브젝트 번호 + 데이터파일 번호 + 블록 번호 + 로우 번호
- 보는 시각에 따라서 논리적 주소정보 라고도 표현.(직접적으로 인덱스에서 테이블 레코드로 연결되는 구조가 아니기 때문) - 메인 메모리 DB와의 비교
- 데이터를 모두 메모리에 로드해 놓고 메모리를 통해서만 I/O를 수행하는 DB
- 인스턴스를 기동하면 디스크에 저장된 데이터를 버퍼 캐시로 로딩하고 이어서 인덱스를 실시간으로 만든다. 즉, 인덱스는 메모리상의 주소정보 뜻하고 포인터(Pointer)를 담는다.
- 데이터 볼륨이 그리 크지 않으며, 기존 디스크 DB로는 도저히 만족할 수 없을 정도의 빠른 트랙잭션 요구 되는 업무에만 사용되는 제한적 활용 ( 예> 이동통신: 위치추적 등, - 인터넷 서비스 로그분석, - 제조 MES의 실시간 데이터, - 대용량 DW)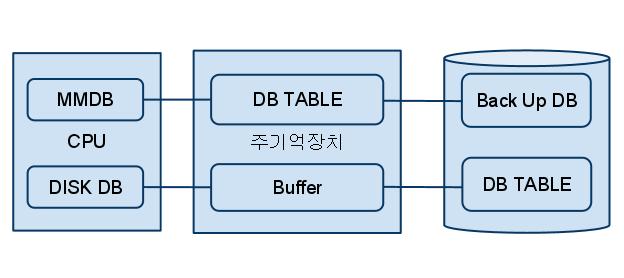
- rowid는 우편주소에 해당
- 오라클 : rowid는 우편주소, 예> Cilent <---> 미들웨어 <---> DB
- 메인 메모리 DB : 물리적인 연결되어있는 전화번호, 예> Cilent <---> DB - 인덱스 rowid에 의한 테이블 액세스 구조
- 포인터로 빠르게 액세스하는 버퍼 Pinning 기법을 사용하지만 반복적으로 읽힐 가능성이 큰 블록에 대해서만 일부 적용
- 테이블 레코드와 물리적으로 연결돼 있지 않기 때문에 인덱스를 통한 테이블 액세스는 고비용 구조
- 모든 데이터가 메모리에 캐싱돼 있더라도 테이블 레코드를 찾기 위해 매번 DBA를 해싱하고 래치 획득 과정을 반복해야 함
- 인덱스의 고비용 구조(래치 획득과 버퍼Lock에 의한 대기 이벤트)
1. 인덱스에서 하나의 rowid를 읽고 DBA를 해시 함수에 적용해 해시값 확인
2. 각 해시 체인은 래치에 의보호되므로 해시값이 해시 체인에 대한 래치(chash buffers chains 래치)를 얻으려고 시도(하나의 래치가 여러개 해시 체인을 동시에 관리한다.)
3.다른 프로세스가 래치를 잡고 있으면 래치가 풀렸는지 확인하는 작업을 일정횟수(기본2000번)만큼 반복
4.실패하면 CPU를 OS에 반환하고 대기상태. latch free 대기 이벤트 발생
5.정해진 시간동안 잠자다가 깨어나 다시 래치상태 확인하고 계속해서 래치가 풀리지 않으면 또 다시 대기 상태로 빠질 수 있다.
6. 래치 해제시 래치를 획득하고 원하던 해시체인으로 진입
7. 데이터 블록을 찾으면 래치 해제하, 앞서 해당 블록을 액세스한 프로세스가 있어 버퍼 Lock을 쥔 상태라면 또다시 대기(buffer busy wait 이벤트 발생)
8. 블록 읽기를 마치고 버퍼 Lock 을 해제해야 하므로 다시 해시 체인 래치를 얻으려고 시도. 또다시 경합 발생
- 해시체인을 스캔했는데 블록을 찾지 못했을 경우
1. 디스크로 부터 블록을 퍼 올리려면 우선 Free 버퍼를 할당 받아야 하므로 LRU 리스트 스캔. 이를 위해서는 cache buffers lru chain 래치를 얻어야 하는데 래치 경합이 심할때는 또다시 latch free 이벤트 발생
2. LRU 리스트를 정해진 임계치만큼 스캔했는데도 Free 상태의 버퍼를 찾지 못하면 DBWR에게 Derty 버퍼를 디스크에 기록해 Free 버퍼를 확보해 달라는 신호를 보낸다. 해당 작업이 끝날 때까지 잠시 대기 상태에 빠지는데 이때 나타나는 대기 이벤트가 free buffer waits 이다.
3. Free 버퍼를 할당 받은 후에는 I/O 서브시스템에 I/O 요청 다시 대기 상태. 이때 db file sequential read 대기 이벤트 발생
4. 마지막으로 읽은 블록을 LRU 리스트 상에서 위치를 옮겨야 하기 때문에 다시 chache buffers lru chain 래치를 얻어야 하는데 원할하지 못할시에 latch free 이벤트 발생
- 모든 데이터가 메모리에 캐싱돼 있더라도 테이블 레코드를 찾기 위해 매번 DBA(Data Block Address)를 해싱하고 래치 획득 과정을 반복해야 함
(2) 인덱스 클러스터링 팩터
- 군집성 계수(= 데이터가 모여있는 정도)
- 특정 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여있는 정도 - 클러스터링 팩터 조회
- 좋은 클러스터링 백터 : 인덱스 레코드 정렬 순서와 거기서 가르키는 테이블 레코드 정렬 순서가 100%일치하는 것임
.jpg)
- 나쁜 클러스터링 백터 : 인덱스 레코드 정렬 순화 테이블 레코드 정렬 순서가 전혀 일치 하지 않는 것임.jpg)
- clustering_factor 수치가 테이블 블록(table_blocks)에 가까울수록 데이터가 잘 정렬돼 있음을 의미하고 레코드 개수(num_rows)에 가까울수록 흩어져 있음을 의미한다.
1. Counter 변수 선언
2. 인덱스 리프 블록 처음부터 끝까지 스캔하면서 인덱스 rowid로부터 블록 번호 취득
3. 연재 리딩 인덱스 레코드의 블록 번호가 바로 직전에 읽은 레코드의 블록 번호와 다를때마다 counter 변수값을 1씩 증가
4. 스캔완료 후 최종 counter 변수값을 clustering_factor로서 인덱스 통계에 저장
- 인덱스를 이용한 테이블 액세스 비용 계산 공식
비용 = blevel + ? 인덱스 수직적 탐색 비용
(리프 블록 수 x 유효 인덱스 선택도) + ? 인덱스 수평적 탐색 비용
(클러스터링 팩터 x 유효 테이블 선택도) ? 테이블 Random 액세스 비용
blevel : 리프 블록에 도달하기 전 읽게 될 브랜치 블록 개수
유효 인덱스 선택도 : 전체 인덱스 레코드 중에서 조건절을 만족하는 레코드를 찾기 위해 스캔할 것으로 예상되는 비율(%)
유효 테이블 선택도 : 전체 레코드 중에서 인덱스 스캔을 완료하고서 최종적으로 테이블을 방문할 것으로 예상되는 비율(%) -
클러스터링 팩터와 물리적 I/O
- 인덱스 CF가 좋다 : 인덱스 정렬 순서와 테이블 정렬 순서가 서로 비슷하다
- 인덱스를 스캔하면서 읽은 테이블 블록들의 캐시 히트율이 높아지므로 물리적인 디스크 I/O 횟수가 감소 -
클러스터링 팩터와 논리적 I/O
- 인덱스를 경유해 테이블 전체 로우를 액세스할 때 읽을 것으로 예상되는 논리적인 블록 개수
- 물리적 I/O계산을 위해 논리적 I/O측정
1. 인덱스가 가리키는 데이터의 흩어짐 정도를 인덱스 비용 계산식에 표현하기 위해 CF고안
2. 논리적 I/O가 100% 물리적 I/O를 수반하기란 매우 비현실적, 데이터를 다시 읽을시 캐싱된 블록을 읽을 가능성이 훨씬 높기 때문이다.
3. 물리적으로 읽어야할 전체 테이블 블록 개수는 고정되어 있음에도 캐싱효과를 예측하기 어렵기 때문에 CF를 통해 계산된 논리적 I/O횟수를 그대로 물리적 I/O에 인덱스비용반영
4. clustering_factor는 인덱스를 통해 테이블을 액세스할 때 예상되는 논리적 I/O 개수를 더 정확히 표현하고 있다. - 버퍼 Pinning에 의한 논리적 I/O 감소 원리
- 인덱스의 CF에 따라 논리적인 블록 I/O가 심하게 차이나는 이유는 인덱스를 통해 액세스 되는 하나의 테이블 블록을 Pinning 하기 때문이다. - 손익분기점을 극복하기 위한 기능들
- IOT : 테이블을 인덱스 구조로 생성하는것
- 클러스터 테이블 : 키값이 같은 레코드는 같은 블록에 모여 있도록 저장하는것
- 파티셔닝 : 대량 범위 조건으로 자주 사용되는 컬럼 기준으로 테이블을 파티셔닝 하는것
-- 1. CR_BAD_TEST 테이블을 하나 만든다.CREATE TABLE CR_BAD_TEST (USER_SEQ NUMBER, USER_ID VARCHAR2(20), USER_NM VARCHAR2(20), EMAIL VARCHAR2(100), GENDER CHAR(1), NOTE VARCHAR2(500));
-- 2. CR_BAD_TEST 테이블에 데이타를 넣을때 몇개의 컬럼은 오라클 난수함수를 사용해 데이타를 넣는다.
(오라클 난수함수를 사용한 이유는 난수DATA가 인덱스에 미치는 영향을 보고자함,)
-- 3. 책에서 OBJECT_ID 순으로 데이타를 넣은것을 저는 순차적으로 USER_SEQ 에 들어가게 했다. 그리고 다른컬럼 USER_ID 에는 데이타를 오라클 난수함수로 마구잡이로 넣었다.
INSERT INTO CR_BAD_TEST
SELECT ROWNUM AS USER_SEQ, DBMS_RANDOM.STRING('X', 20) AS USER_ID,
DBMS_RANDOM.STRING('U',20) AS USER_NM,
TO_CHAR(ROWNUM) AS USER_EMAIL, DECODE(MOD(ROWNUM, 2), 1, 'M', 'W') AS GENDER,
DBMS_RANDOM.STRING('A',100) AS NOTE
FROM EMP E1, EMP E2, EMP E3, EMP E4, EMP E5, DEPT E6;
-- 4. USER_SEQ 와 USER_ID 각각의 컬럼에 INDEX를 생성한다.
CREATE INDEX CR_BAD_USER_SEQ_IDX ON CR_BAD_TEST(USER_SEQ);
CREATE INDEX CR_BAD_USER_ID_IDX ON CR_BAD_TEST(USER_ID);
-- 5. CR_BAD_TEST 테이블의 통계정보를 수집한다.
EXEC DBMS_STATS.GATHER_TABLE_STATS(USER, 'CR_BAD_TEST');
-- 6. 클러스터링 팩터 조회를 한다.
SELECT I.INDEX_NAME, T.BLOCKS TABLE_BLOCKS, I.NUM_ROWS, I.CLUSTERING_FACTOR
FROM USER_TABLES T, USER_INDEXES I
WHERE T.TABLE_NAME = 'CR_BAD_TEST'
AND I.TABLE_NAME = T.TABLE_NAME;------------------------------------------------------------------------------------------------------------
INDEX_NAME TABLE_BLOCKS NUM_ROWS CLUSTERING_FACTOR
CR_BAD_USER_SEQ_IDX 48981 2234655 54667
CR_BAD_USER_ID_IDX 48981 2162639 2162571
------------------------------------------------------------------------------------------------------------
실직적으로 순차적으로 들어간 컬럼 USER_SEQ 에 대한 INDEX 는 TABLE_BLOCKS 의 갯수와 CLUSTERING_FACTOR 의 갯수가 비슷하다는 것을 알 수 있다.
하지만 난수DATA가 들어간 USER_ID 에 대한 INDEX 는 TABLE_BLOCKS 의 갯수보다 오히려 NUN_ROWS 의 갯수와 비슷하다는것울 볼 수 있다.
-- 7. 각각에 인덱스에 대한 실행계획을 확인한다.
SELECT /*+ INDEX(T CR_BAD_USER_SEQ_IDX) */ COUNT(*) FROM CR_BAD_TEST T
WHERE USER_ID >= ' '
AND USER_SEQ >= 0;
----------------------------------------------------------------------------------------------------
| ID | OPERATION | NAME | ROWS | BYTES | COST (%CPU)| TIME |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 27 | 60056 (1)| 00:12:01 |
| 1 | SORT AGGREGATE | | 1 | 27 | | |
|* 2 | TABLE ACCESS BY INDEX ROWID| CR_BAD_TEST | 2141K| 55M| 60056 (1)| 00:12:01 |
|* 3 | INDEX RANGE SCAN | CR_BAD_USER_SEQ_IDX | 2234K| | 5238 (2)| 00:01:03 |
----------------------------------------------------------------------------------------------------SELECT /*+ INDEX(T T_OBJECT_NAME_IDX ) */ COUNT(*) FROM T
WHERE USER_ID >= ' '
AND USER_SEQ >= 0;---------------------------------------------------------------------------------------------------
| ID | OPERATION | NAME | ROWS | BYTES | COST (%CPU)| TIME |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 27 | 2175K (1)| 07:15:01 |
| 1 | SORT AGGREGATE | | 1 | 27 | | |
|* 2 | TABLE ACCESS BY INDEX ROWID| CR_BAD_TEST | 2141K| 55M| 2175K (1)| 07:15:01 |
|* 3 | INDEX RANGE SCAN | CR_BAD_USER_ID_IDX | 2162K| | 9743 (1)| 00:01:57 |
---------------------------------------------------------------------------------------------------(3) 인덱스 손익분기점
- 손익 분기점 : Index Rang Scan에 의한 테이블 액세스가 Table Full Scan 보다 느려지는 지점을 말한다.
핵심 요인
1. 인덱스 rowid에 의한 테이블 액세스는 Random 액세스인 반면 Full Table Scan은 Sequential 액세스
2. 디스크 I/O시, 인덱스 rowid에 의한 테이블 액세스는 Single Block Read 방식을 사용하는 반면, Full Table Scan은 Multiblock Read 방식을 사용
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 40 | 2. 서브쿼리 Unnesting | darkbeom | 2011.05.15 | 21673 |
| 39 | 2. 소트를 발생시키는 오퍼레이션 | 휘휘 | 2011.06.12 | 4794 |
| 38 | 2. 파티션 Pruning | 실천하자 | 2011.06.21 | 27697 |
| 37 |
3. 병렬 조인
| 실천하자 | 2011.06.28 | 8472 |
| 36 |
3. 다양한 인덱스 스캔 방식
| 멋진넘 | 2011.02.18 | 35304 |
| 35 |
3. 해시 조인
| darkbeom | 2011.03.20 | 22937 |
| 34 | 3. 옵티마이저의 한계 | 멋진넘 | 2011.04.19 | 8746 |
| 33 | 3. 뷰 Merging | 실천하자 | 2011.05.15 | 24872 |
| 32 |
3. 데이터 모델 측면에서의 검토
| 멋진넘 | 2011.06.13 | 7186 |
| 31 | 3. 인덱스 파티셔닝 | darkbeom | 2011.06.19 | 55742 |
| » |
4. 테이블 Random 액세스 부하
[1] | darkbeom | 2011.02.23 | 16046 |
| 29 | 4. 조인 순서의 중요성 | 운영자 | 2011.03.27 | 15799 |
| 28 | 4. 통계정보 Ⅰ | darkbeom | 2011.04.25 | 19526 |
| 27 | 4. 조건절 Pushing | 실천하자 | 2011.05.31 | 8194 |
| 26 |
4. 소트가 발생하지 않도록 SQL 작성
| 멋진넘 | 2011.06.12 | 9198 |
| 25 | 5. 테이블 Random 액세스 최소화 튜닝 | suspace | 2011.02.24 | 8290 |
| 24 | 6. 스칼라 서브쿼리를 이용한 조인 [1] | 휘휘 | 2011.03.28 | 8020 |
| 23 | 5. Outer 조인 | 실천하자 | 2011.03.29 | 6390 |
| 22 | 5. 카디널리티 | suspace | 2011.04.26 | 6809 |
| 21 | 5. 조건절 이행 | 휘휘 | 2011.05.29 | 6780 |
스터디 때 의견 나왔던 버퍼 LOCK 과 래치 부분 자료 링크 올립니다. ^^
☞ "고도화 원리와 해법 1권" 의 버퍼 LOCK 자료 바로가기