매주 각 스터디 팀원들이 담당 분량을 정리해서 올리고 토론식으로 진행합니다.
스터디 포스팅은 팀원들에의해 이루어지지만 스터디 참여는 사이트 회원 모두가 가능합니다.
진행기간: 2009.07 ~ 2009.10. 종료
1.1. 테이블과 인덱스의 분리형
2009.07.04 15:05
1.1. 테이블과 인덱스의 분리형
1.1.1. 분리형 테이블의 구조
-
테이블과 인덱스가 별도로 분리되어 있는 구조로 관계형 데이터베이스의 가장 일반적인 데이터 저장형식
분리형 테이블의 구조
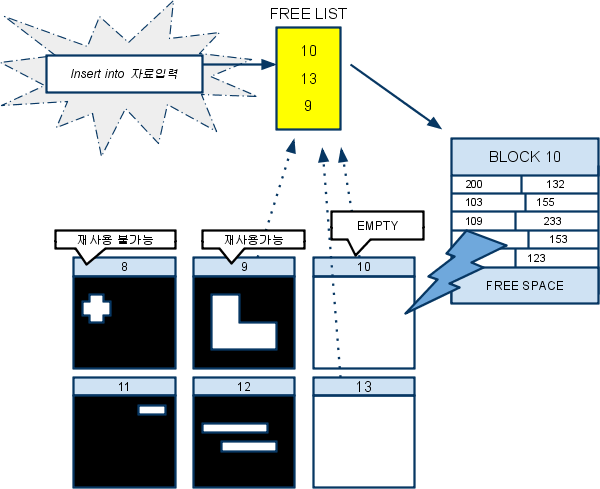
-
자료가 입력되면 DBMS는 FREE LIST에서 DB의 여러 블록중 저장가능한 블록을 확인후 저장
저장시 블록내 이어진 공간이 없다면 전체 블록의 로우 위치를 재배치(Condensing)후 저장(반드시 한조각이되어야함)
'FREE SPACE'는 이미 들어가 있는 로우들의 길이에 변화가 생겼을대 사용하는 여유 공간(UPDATE등) - pctfree로 지정
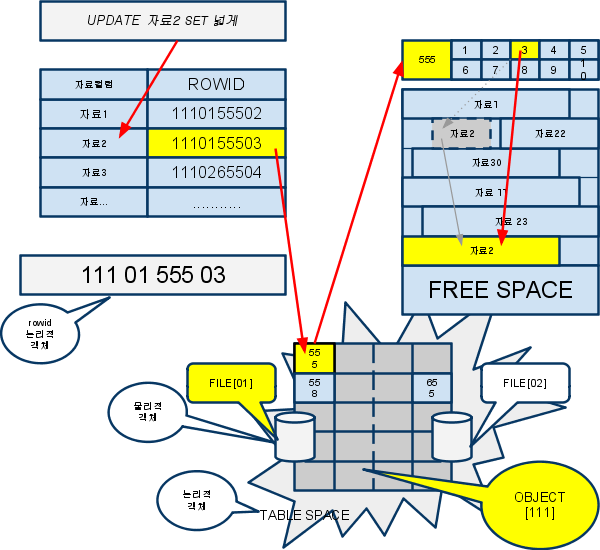
-
테이블스페이스(Tablespace)
데이터가 저장되는 논리적인 저장공간
물리적인 데이터 파일(Datafile)로 구성 -
세그먼트(Segment)
테이블스페이스를 용도별로 나눔(데이터 오브젝트(Object))
파티션(Partition)이 발생한 테이블이나 인덱스는 각각의 파티션이 단위오브젝트가 됨
파티션된 테이블의 각 파티션이 서로 다른 테이블스페이스에 존재하는 경우는 여러 테이블스페이스에 걸쳐 저장
개별 파티션이나 파티션되지 않는 테이블들은 반드시 하나의 테이블스페이스에 존재 -
ROWID
'오브젝트번호+데이터파일번호(테이블스페이스당 일련번호)+블록번호+슬롯번호'로 구성
인덱스에 존재( 테이블에 존재하지 않음)
* ROWID의 오브젝트 번호와 데이터파일 번호를 통해물리적인 저장위치를 찾아서 거기에 있는 블록번호를 찾아가면 슬롯
* 블록내에서 로우의 위치가 이동하더라고 rowid는 결코 변하는 않음(슬롯은 로우(자료)의 위치를 가지고있음)
로우가 한조각으로 저장될수있는 위치로 이동했을때 해당 슬롯에 있는 위치 값은 새로운 위치값으로 변경 -
Oracle Physical Rowid
000000 + FFF + BBBBBB + RRR
(Data obect(6) + Relative file(3) + Block(6) + Row(3)): 16자리 (저장시 10자리)
Data Object number: DATABASE SEGMENT 식별정보
Relative File number: Tablespace에 성대적 Datafile 번호
Bolck Number : Row 를 포함하는 Data Bolck 번호
Row number: Block 에서 row 의 Slot -
SQL Server 의 Rid
8바이트 = Page Address(4)+File ID(2) + slot number(2) -
응축(Condensing)작업
이동이 계속적으로 발생하면 결국에는 사용할 수 없는 수많은 작은 조각(Fragmentation)들이 발생
이어진 조각이 없어 저장이 불가능하게 될때 자동으로 블록의 로우들을 재구성작업
만약 여유공간(FREESPACE(PCTFREE값)) 이 너무 적게 지정되었다면 지나치게 빈번한 응축자업이 발생하여 부하의 원인이 될수있음
수정이 빈번하게 발생할 가능성이 높다면 다수 충분하게 여유공간(PCTFREE) 를 지정해주는 것이 유리 -
로우의 이주(Migration)
로우의 블록이동 발생시 기존 ROWID에 새로운 ROWID를 넣어 ROWID를 찾을수 있게함
인덱스의 ROWID를 변경시키지 않는 대신에 액세스를 할때 여러 블록을 읽어야 하는 오버헤드발생
이주현상은 로우나 테이블을 삭제하고 테이블을 재생성 해야만 치유( delete and insert )
체인(chain)
여러 블록에 걸쳐 데이타가 존재한다는 점에서 이주와 유사
어떤로우의 길이가 한블록의 크기를 넘을때 필요한 공간만큼 블록을 연결해서 저장하는것
일반적으로 블록 내에 존재하는 로우는 가변길이로 존재
1.1.2. 클러스터링 팩터(Clustering Factor)
클러스터링 팩터(Clustering Factor)
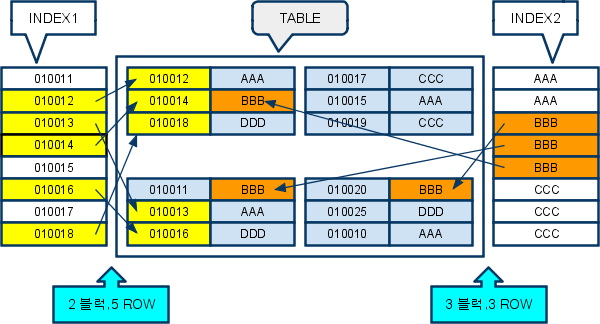
-
인덱스의 컬럼값으로 정렬되어 있는 인덱스 로우의 순서와 테이블에 저장되어있는 데이터 로우가 얼마나 비슷한 순서로 저장되어 있느냐에 대한 정도를 나타내는 것
INDEX1: 5ROW를 불러오는데 2블럭을 읽었음 - 클러스터링 팩터가 좋음
INDEX2: 3ROW를 불러오는데 3블럭을 읽었음 - INDEX1에 비해 클러스터링 팩터가 나쁨
분리형 테이블의 구조의 최대의 특징인 데이터의 값에 전혀 무관하게 '임의의 위치' 에 저장할 경우
데이터 작업을 할 경우 최소한 한개 이상의 블록은 엑세스 할수 밖에 없음 (로우를 액세스하지만 실제 DBMS는 블록을 액세스 후 로우를 찾음) -
인덱스는 인덱스 컬럼과 ROWID 로 정렬
ROWID로 정렬되었다는것은 물리적인 데이터파일의 블록으로 정렬되고, 거기에서 다시 슬롯번호로 정렬되었다는 것을 뜻
클러스터링 팩터가 좋은 인덱스로 액세스하면 많은 로우를 액세스 하더라도 보다 적은 블록을 액세스하게 되어 효율적임 -
클러스터링 팩터를 높이는 방법
원하는 형태로 저장(저장 시 과도한 비용을 발생할수 있음)
주기적 테이블을 재생성
저장할 컬럼 순서를 전략차원에서 판단하여 결정
1.1.3. 분리형 테이블의 액세스 영향 요소
가) 넓은 범위의 액세스 처리에 대한 대처방안
-
먼저 가장 중요한 액세스 형태를 선정
컬럼이 가진 처리범위에 대한 문제를 해결할 수있는 방법을 찾아야 함 -
특정한 모양으로 저장
특정 액세스 형태에서만 효율을 얻을수 있을뿐
데이터 등록시의 부하 부담을 무시할수없다면 특정 위치에 저장을 하는 것은 다시 한번 검토 -
지속적으로 증가하는 데이터
관리적인 측면의 부담이 크다면 파티션을 적용
인덱스를 전략적으로 구성하고 SQL의 실행계획을 최적화
나) 클러스터링 팩터 향상전략
-
분리형 구조는 아무렇게나 저장해도 괞찮다는 의미이지만 반대로 의도적으로 우리에게 유리한 형태로 저장하는 것도 가능하다는 뜻
-
테이블을 재생성
주기적으로 재생성하여 이미 저장되어있는 데이터의 응집도를 높여 주는것
체인을 감소시키고 블록 내 데이터의 저장율을 높여 불필요한 I/O를 줄이기 위해 사용
가지 깊이(BRANCH DEPTH)가 정리되는 효과 -
테이블에 데이터를 저장할 때 관련된 인덱스를 모두 제거하거나 비활성
-
인덱스를 생성한 채로 대량의 데이터를 저장하면 테이블의 저장 속도가 크게 저하될 뿐만 아니라 인덱스에 많은 분할이 발생하여 인덱스 저장 밀도가 매우 나빠짐
-
테이블을 생성하는 구문에 기본키 제약조건을 지정해 두었다면 테이블을 생성하면서 기본키가 같이 생성되어 버려 비효율(인덱스 저장밀도가 나빠짐)
기타
각 DBMS별, 버젼별 옵션등 다양 - 9I이후 ASSM 도입 (PCTUSED,FREELIST를 명시적으로 지정하지 않고 자동관리 )
DBMS별 테이블 생성시 옵션들이 다양하며 그 옵션은 테이블의 용도(업무형태)에 따라 다양하게 구성될수 있다.
댓글 3
-
wikanet
2009.07.07 12:18
-
goldlight111
2009.07.09 23:09
1. 데이터를 검색할때, 즉 row를 찾을때,
사용자 - 세그먼트 - tablespace - block -slot 형태로 찾는다고 학습했습니다.
예를 들어,
첫번째, 원하는 3개의 row를 검색할때, 2개의 블록으로 검색했습니다.
두번째, 원하는 3개의 row를 검색할때, 3개의 블록으로 검색했습니다.
어차피 첫번째, 두번째는 똑같습니다. 찾는 형식은요.
3번 다가야된다는 것이지요.
겉으로 봐선. 마치 3개의 블록이라는 이유만으로 느리다곤 하는데,
길은 같다고 보이는거죠.. 3번다 찾으러 가야되는거. 그런데 왜 2번이 더 좋을까?
제가 알기론 sga 공유메모리 영역에 해당 블록이 올라온다고 들었습니다.
짧은 지식으로는 해당 블록이 올라오면 먼저 datafile보단 해당 공유메모리에서 먼저 검색하기때문에 당연히 3개 블록을 메모리에 upload 하는 행위보다는,
2개의 블록을 메모리에 상주시키게 하는것이 더 효율적이라는 것이라 알고있습니다.
머리속에 흐릿하게 생각나는 것인데 설명 부탁드려요 자세하게 설명 부탁드려요!!
2. 클러스터링 팩터가 나빠졌어요!! 이부분을 좋게 하는 행위가 빈번하게 table을 재성성 하는것이 좋다고 학습했습니다.
table 재성시 rowid와 rowid와 관련있는 table의 row 순서가 비슷하게 들어가기 때문이라고 생각되는데요.
테이블을 만들고 insert 할때, 자주 조검 검색되는 컬럼을 기준으로 소트하여 모두 insert 하는게 유리하다고 생각되는데..
이게 맞는건지...
제 생각은 인서트후 테이블을 검색할때, 어차피 조건따라 검색되니,
그 조건과 관련된 기준으로 다 배치하면 우르르 한곳에 몰리게 되므로 검색할때 더 효율적이지 않냐 생각하에 말씀드립니다. 위에 자료에서도 느껴지긴 하는데 자신있게 아 이거구나 하고 필이 안와서..
확실한 답변 부탁드립니다.
물론, 제 생각으로는 위처럼 한기준으로 팩터가 좋아졌을시.. 다양한 경로검색을 통했을때는 비효율적이라고 생각합니다.
운영상 상황에 맞춰서 해야될거라고도 생각합니다.
3. 인덱스 저장시, 인덱스 생성한채로 대량데이터 저장시 저장속도가 크게 저하된다고 말했습니다. 저도 그렇게 생각합니다.
데이터 블록에 저장하면서 당연히 인덱스 컬럼에 rowid가 들어가기 때문에 이중고를 겪을수 밖에 없구나 하고 생각했기 때문입니다.
그런데, 인덱스의 분할, 저장밀도와 관련해서 말씀하셨는데,, 이부분이 확실히 이해가 안되고 약간 저에게 추상적으로 다가와서요..
이부분 설명 부탁드립니다.
4. 테이블 생성시, 제약조건을 걸어둔 상태에서 대용량 데이터를 인서트하면 비효율적이라고 하였습니다.
인덱스 저장밀도가 나빠진다고 하였는데, 저장밀도 나빠진다는게 무엇인지 답변 부탁드립니다.
예를들어 부탁드려요이해가 잘 안가서..
5. 위에서 " " 블록의 글에서 - 팩터가 나쁘면 테이블을 재성성 하라는 말이 있습니다. 위의 질문중에도 있지요..조건위주로 sort하는게 좋을까요? -
tofriend
2009.07.10 12:06
사용자 - 세그먼트 - tablespace - block -slot 형태로 찾는다고 학습했습니다.
예를 들어,
첫번째, 원하는 3개의 row를 검색할때, 2개의 블록으로 검색했습니다.
두번째, 원하는 3개의 row를 검색할때, 3개의 블록으로 검색했습니다.
어차피 첫번째, 두번째는 똑같습니다. 찾는 형식은요.
3번 다가야된다는 것이지요.
겉으로 봐선. 마치 3개의 블록이라는 이유만으로 느리다곤 하는데,
길은 같다고 보이는거죠.. 3번다 찾으러 가야되는거. 그런데 왜 2번이 더 좋을까?
제가 알기론 sga 공유메모리 영역에 해당 블록이 올라온다고 들었습니다.
짧은 지식으로는 해당 블록이 올라오면 먼저 datafile보단 해당 공유메모리에서 먼저 검색하기때문에 당연히 3개 블록을 메모리에 upload 하는 행위보다는,
2개의 블록을 메모리에 상주시키게 하는것이 더 효율적이라는 것이라 알고있습니다.
머리속에 흐릿하게 생각나는 것인데 설명 부탁드려요 자세하게 설명 부탁드려요!!
2. 클러스터링 팩터가 나빠졌어요!! 이부분을 좋게 하는 행위가 빈번하게 table을 재성성 하는것이 좋다고 학습했습니다.
table 재성시 rowid와 rowid와 관련있는 table의 row 순서가 비슷하게 들어가기 때문이라고 생각되는데요.
테이블을 만들고 insert 할때, 자주 조검 검색되는 컬럼을 기준으로 소트하여 모두 insert 하는게 유리하다고 생각되는데..
이게 맞는건지...
제 생각은 인서트후 테이블을 검색할때, 어차피 조건따라 검색되니,
그 조건과 관련된 기준으로 다 배치하면 우르르 한곳에 몰리게 되므로 검색할때 더 효율적이지 않냐 생각하에 말씀드립니다. 위에 자료에서도 느껴지긴 하는데 자신있게 아 이거구나 하고 필이 안와서..
확실한 답변 부탁드립니다.
물론, 제 생각으로는 위처럼 한기준으로 팩터가 좋아졌을시.. 다양한 경로검색을 통했을때는 비효율적이라고 생각합니다.
운영상 상황에 맞춰서 해야될거라고도 생각합니다.
3. 인덱스 저장시, 인덱스 생성한채로 대량데이터 저장시 저장속도가 크게 저하된다고 말했습니다. 저도 그렇게 생각합니다.
데이터 블록에 저장하면서 당연히 인덱스 컬럼에 rowid가 들어가기 때문에 이중고를 겪을수 밖에 없구나 하고 생각했기 때문입니다.
그런데, 인덱스의 분할, 저장밀도와 관련해서 말씀하셨는데,, 이부분이 확실히 이해가 안되고 약간 저에게 추상적으로 다가와서요..
이부분 설명 부탁드립니다.
4. 테이블 생성시, 제약조건을 걸어둔 상태에서 대용량 데이터를 인서트하면 비효율적이라고 하였습니다.
인덱스 저장밀도가 나빠진다고 하였는데, 저장밀도 나빠진다는게 무엇인지 답변 부탁드립니다.
예를들어 부탁드려요이해가 잘 안가서..
5. 위에서 " " 블록의 글에서 - 팩터가 나쁘면 테이블을 재성성 하라는 말이 있습니다. 위의 질문중에도 있지요..조건위주로 sort하는게 좋을까요?
1.
우선 그부분은 저도 머리속에 허리멍텅하게 생각하고있는데 덕분에 한번 찾아보았습니다. ^^
오라클의 SGA 메모리는 버퍼 캐쉬,공유풀, 라지 풀, 리두 로그 버퍼로 구성되어있구요
그정 버퍼 캐쉬에 데이터파일에서 읽혀진 블록이 저장됩니다.
공유풀에서는 기존사용자들의 sql 구분,pl/sql 코드,제어구조등 다른 세션에서 활용가능한 자료를 보관하구요
리두로그 버프는 db의 변화에 관련된 정보를 가지고 있는 버퍼구요
라지풀은 4k이상의 덩어리를 보관하기위한 db운영자가 설정하는 선택적 메모리영역입니다.
우선 말씀하신데로 3개의 row를 검색할때 2개의 블록,이나 3개의 블록이나 access의 기준으로 보면
3번 접근해야하는데(사실 접근이 3번이라도 물리적으로보면 디스크드라이브의 access arm이 기존 엑세스한
블록 위치에 있기때문 2개의 블록접근이 빠를껍니다. ^^ 1->2->3의 순서가 뒤죽박죽이거나
OS랑 동일한 물리적 하드에 구성된 DB라면 디스크로 스왑쓴다고 arm이 왔다갔다하면 별상관없을꺼지만..)
dbms가 한번읽은 우선 버퍼캐쉬에 올리고 우선 버퍼영역의 블록을 검사 한후에 가져오니까
속도의 향상을 볼수 있습니다.
2.
재성성를 빈번하게 해야한다는건 아마 무리가 있는거 같구요.^^(저도 몇번안해봤습니다.ㅎ)
DB라는게 운영을 하다보면 자료가 쌓이게 되고 쌓인 자료는 삭제/입력/수정이 일어나게 될겁니다.
그과정에서 다른블록으로 넘어서 저장하다가 다시 로우가 삭제되고 수정되고 하면서 pctused가 설정한 값에
다다르게 되면 다시 재사용되어지는 테이블도 있을거고 하다보면 클러스터링 팩터라는게
말씀하신데로 입력할때 소트해서 집어넣었다고 해도 향후 똑같은 문제가 반복해서 발생하게 될거라고 생각됩니다.
(위 질문의 테이블을 만들고 insert할때라는게 재생성이 아니고 초기생성 얘기하신거 맞으시죠?)
아마 그런식으로 넣을수 있는 자료는 수정/삭제가 그의 없는 '집계' 테이블 정도가 가능할꺼같습니다.
코드성 테이블도 수정/삭제는 드물지만 코드라는게 추가가 발생할수가 있습니다.
그때마다 소팅하는건... ^^;;;
그런 문제때문에 자료의 형태에따라 테이블의 구조를 잘 선택해야만 할꺼같네요.
비슷한 형태로 저장시키리면 단일테이블을 클러스터링 테이블로 생성하는것도 방법일꺼같습니다.
3.
인덱스의 분할, 저장밀도는 이번주 분량인 인덱스부분에 나올텐데요. 인덱스라는 b tree알고리즘을 기본으로 합니다.
b tree라는게 자료의 앞뒤 주소를 가지면서 linked list를 만들어내면서
사실상의 정렬 상태를 같은 깊이의 피라미드 형태로 만들어 내거던요.
새로운자료가 들어올때 그렇게 피라미드가 유지되려면 아무레도 앞뒤 자료 값구분하고 새로운 가지를 만들어야하다보니
분할이 당영하게 일어나게 됩니다. 또 밀도는 오라클인덱스의 경우 정렬값중 하나가 삭제되면 그 삭제부분을 지우고
그 블록을 다시 쓰는게 아니라 그냥 비워 두다가 그 위치에 위치할 새로운값이 들어오면 집어넣습니다.
그렇게 삭제가 많아지다 보면 아무래도 밀도가 왔다갔다 할꺼라고 생각되네요.
공부하다보니까 index rebuild 이슈까지 영향을 끼치긴 하던데.. 때되면 다시 입력하니까 그다지 주기적인 rebuild는
필요없을듯 보이기도 합니다.
자세한 내용은 이번주 분량에 설명이 되리라 보아집니다~~^^ ㅎ
4.
테이블 재생성이라는게 테이블 자료가 여기 저기 블록에 흩어져 있는걸 쭉 비슷한 위치로 만들어주는 효과가있는데요
제약조건등을 걸어두는 경우는 dbms가 자료 한줄 들어오고 채크하고 한줄 들어채크하고 저장하고
하다보니까 tree 자체를 계속 갱신에 갱신에 해나갈수 밖에 없고 입력형태에 따라 tree의 루트가 계속 바뀌어나가는
과정에서 제약조건없이 생성했다가 그냥 index를 만들어 주는게 시간및 효율에더 더 유리할꺼같습니다.
5.
테이블 형태에따라서 다르지 않을까 싶습니다.매출테이블같은경운 일자별로 운영되어가니까
당연히 일자별소팅으로 insert하는게 좋을테고 코드 테이블은 각 코드 별로 하는게 좋을테고 ..
이렇게 하는게 좋다. 라는건 힘들꺼같습니다. 각 테이블이나 디비의 모델링및 용도에 따라
결정해야 하지 않을까요?
우선 제가 아는 범위에서 적긴했는데 그다지 만족스러운 답은...^^;;
혹시 더 정확하게 하시는분은 답변 부탁드리겠습니다. ㅎ
수고많으셨습니다..^^