4.1. 인덱스의 선정 기준 (1/2) (4.1.1.~4.1.5.)
2010.11.13 07:10
4.1. 인덱스의 선정 기준
4.1.1. 테이블 형태별 적용기준
- 적은 데이터를 가진 소형 테이블
- 주로 참조되는(Referenced) 역할을 하는 중대형 테이블
- 업무의 구체적인 행위를 관리하는 중대형 테이블
- 저장용(Log) 대형 테이블
가) 적은 데이터를 가진 소형 테이블
- DB_FILE_MULTIBLOCK_READ_COUNT에 지정된 숫자 이하의 불록을 가진 테이블
- 인덱스 유무가 성능에 거의 미치지 않는다.
- 소형 테이블도 인덱스 구성이 바람직
- 소량 테이블이라도 기본키는 인덱스를 권고한다. ∵기본키는 조인의 실행계획이나 무결성에 영향을 미치므로
나) 주로 참조되는(Referenced) 역할을 하는 중대형 테이블
- 트랜잭션 데이터들의 행위의 주체나 목적이 되는 개체들로 구성된 테이블
- 데이터 모델링에서 주로 키 엔터키(Key Entity)로 구성된 테이블. 대표적인 예) 고객 테이블
- 좁은 범위의 스캔 또는 조인등에 의해 내측루프에서 기본키에 의해 연결되는 유형
다) 업무의 구체적인 행위를 관리하는 중대형 테이블
- 데이터가 지속적으로 증가하고 있기에 비트맵 인덱스 보다 B-Tree 인덱스가 주로 사용
- 테이블 구조에 따라 인덱스 전략에 영향을 받음
- 예) 매출정보 테이블
라) 저장용 대형 테이블
- 갱신이 거의 없어 여유공간(PCTFREE)을 전혀 부여하지 않을 수 있다.
- 파티션을 고려할 수 있다.
인덱스 전략 수립시 절차 중요
4.1.2. 분포도와 손익분기점
인덱스 생성 목적 : 전체 집합에서 특정부분만 선별적으로 액세스 하고자 하는 것.
손익분기점 : 인덱스 컬럼의 분포도가 10~15%를 넘지 않아야 인덱스로서의 가치가 있음.
# 최선의 방법
* 처리범위가 적은 것을 처리주관 조건으로 하는 것
* 처리범위가 적다는 것은 분포가 적다는 것을 의미
현실은
많은 액세스 형태 / 경우마다 인덱스 생성 불가
전략적인 구성이 필요
4.1.3. 인덱스 머지와 결합 인덱스 비교
인덱스 머지(Index Merge) : 여러 인덱스가 협력하여 같이 액세스를 주관
결합 인덱스(Concatenated Index) : 여러 개의 컬럼을 모아 하나의 인덱스로 생성시키는 것.
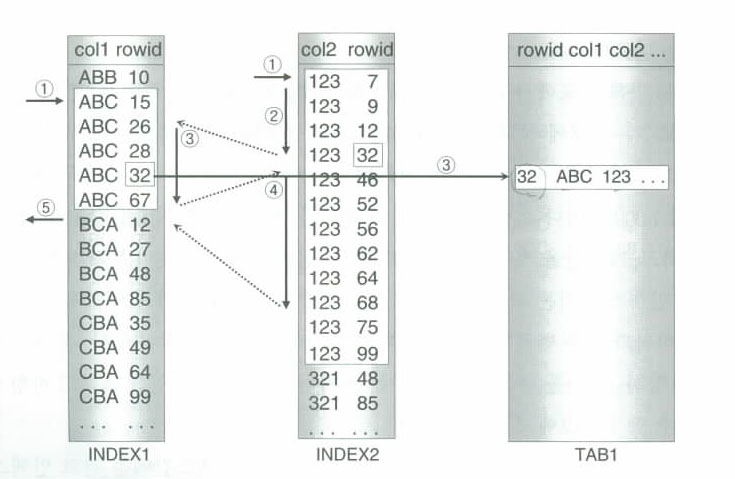
■ 인덱스 머지 SQL 예
SELECT *
FROM TAB1 INDEX1 : COL1
WHERE COL1 = 'ABC' AND COL2 = 123; INDEX2 : COL2
그림 1 - 4 - 1
■ 그림설명
① COL1 인덱스에서 'ABC'인 첫번째 로우와 COL2 인덱스에서 123인 첫번째 로우를 찾는다.
② ROWID를 비교하여 값이 적은쪽(왼쪽)의 값(15)을 기준으로 커질때까지 우측과 비교한다.
③ 우측의 32를 기준으로 비교값보다 커질때까지 좌측을 비교한다. 같으면 액세스 한다.
④ 67을 기준으로 67보다 큰 값이 나올때까지 스캔
⑤ 68을 기준으로 스캔하려 했더니 'ABC'가 아니므로 머지를 중단한다.
■ 종합
- 위 방법은 테이블 액세스를 일으키기 전에 인덱스간에 머지를 통해 처리범위를 최대한 줄여 액세스 한다.
- 인덱스 머지는 머지할 대상이 서로 비슷한 분포도를 가지고 있을 때 유리
- 옵티마이져는 차이가 많이 나는 인덱스간에는 인덱스 머지를 선택하지 않는다.
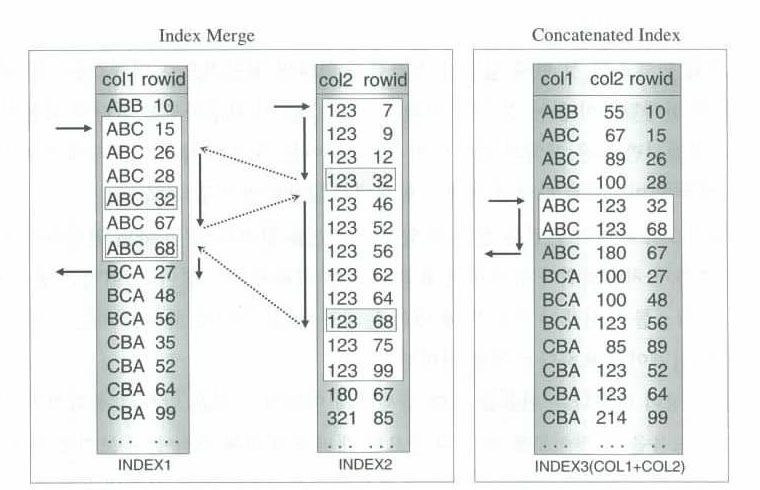
■ 인덱스 머지와 결합 인덱스 차이
그림 1 - 4 - 2
■ 비교 설명
● 인덱스 머지는
두 개의 인덱스를 같은 ROWID로 머지 => 머지를 수행한 양과 머지에 성공한 양에 차이 발생 => 불필요한 일을 함
● 결합 인덱스는
각 인덱스 컬럼 값들과 ROWID로 정렬을 한다. => 이미 머지된 결과에서 rowid를 액세스 한다. => 인덱스 머지보다 처리범위를 줄임
4.1.4. 결합 인덱스의 특징
-
결합 인덱스의 첫 번째 컬럼이 조건절에 없다면 인덱스는 사용되지 않는다.
-
컬럼 중 일부만 조건을 받거나 '='이 아닌 연산자가 많으면 처리범위 증가 => 효율이 크게 저하
즉, 어떤 컬럼들로 인덱스를 구성할지 고민, 어떤 순서로 할지, 치밀한 전략이 필요 -
다음
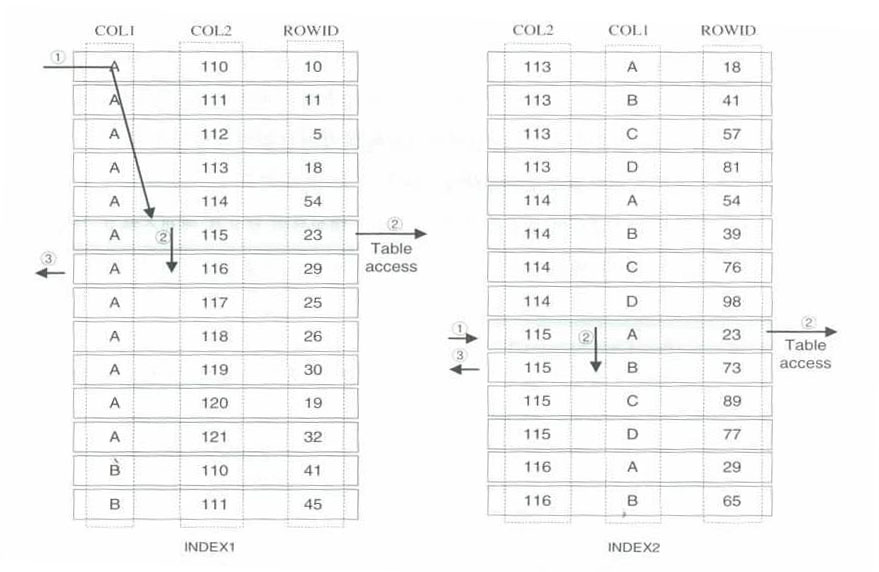
가) 분포도와 결합순서의 상관관계
많은 사람들은 분포도가 좋은 컬럼이 인덱스 컬럼의 순서 결정에 최우선이 된다라고 생각함. => 막연한 생각일 뿐이다
■
■ SQL 예)
SELECT *
FROM TAB1 INDEX1 : COL1 + COL2
WHERE COL1 = 'A' INDEX2 : COL2 + COL1
AND COL2 = 115;
< 분포도가 좋지 않은 컬럼이 선행 > < 분포도가 좋은 컬럼이 선행 >
그림 1-4-3
위 그림은 '분포도와 결합 순서'가 비교 연산자를 모두 '='로 사용했을 때 어떤 상관 관계를 가지고 있는 지를
알아보기 위한 그림이다.
결론) 분포도는 순서에 별다른 영향을 미치지 않는다
■ 좌측 그림 수행
분포도가 넓은 COL1이 앞에 위치하고, 분포도가 좁은 COL2가 뒤에 위치
① COL1 = 'A' 이고 COL2 = 115 인 첫번째 로우를 바로 찾는다.
② ROWID를 이용하여 테이블의 로우를 액세스한다.
③ 다음 로우를 차례로 스캔, 조건을 만족하면 로우 액세스, 그렇지 않으면 스캔 종료
■ 우측 그림 수행
분포도가 좁은 COL2가 앞에 위치하고, 분포도가 넓은 COL1이 뒤에 위치
① COL2 = 115 이고 COl1 = 'A'인 첫번째 로우를 바로 찾는다.
② ROWID를 이용하여 테이블의 로우를 액세스한다.
③ 다음 로우를 차례로 스캔, 조건을 비교, 조건을 만족하면 로우 액세스, 그렇지 않으면 스캔 종료
◆ 종합
컬럼에서 '='을 사용한 경우에는 분포도와 결합순서와의 상관관계는 없다.
분포도보다 더 중요한 요소는 '='의 사용여부 이다.
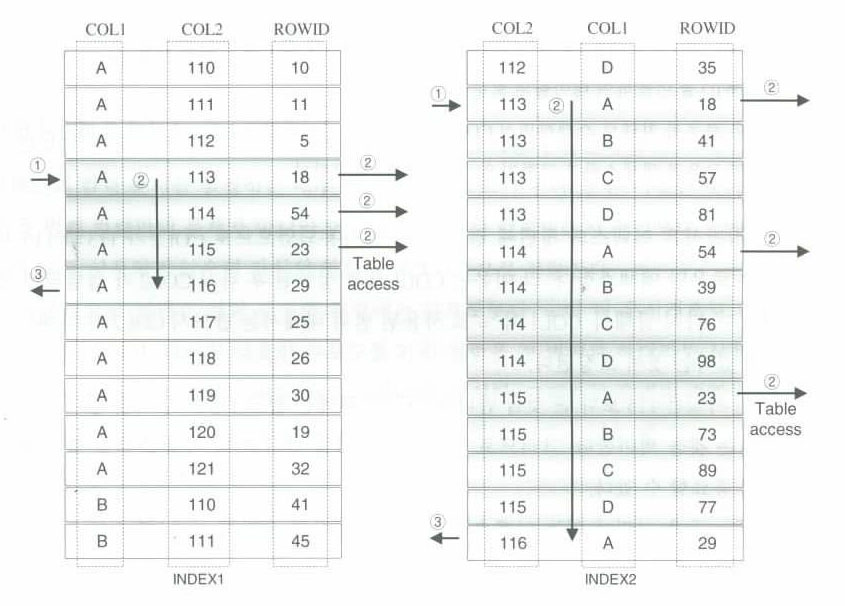
나) 이퀄(=)이 결합순서에 미치는 영향
■
■ SQL 예)
SELECT *
FROM TAB1 INDEX1 : COL1 + COL2
WHERE COL1 = 'A' INDEX2 : COL2 + COL1
AND COL2 BETWEEN 113 AND 115;
< 분포도 넓고, '=' 사용한 컬럼이 앞에 위치> < 분포도 좁고, '=' 사용한 컬럼이 뒤에 위치 >
< 분포도 좁고 'BETWEEN' 사용 컬럼이 뒤에 위치 > < 분포도 넓고 'BETWEEN' 사용 컬럼이 앞에 위치 >
그림 1-4-4
..
■ 좌측 그림 수행
분포도가 넓지만 '='로 사용된 COL1이 앞에 위치, 분포도는 좁으나 'BETWEEN'으로 사용된 COL2가 뒤에 위치
① COL1 = 'A' 이고 COL2 = 115 인 첫번째 로우를 바로 찾는다.
② ROWID를 이용하여 테이블의 로우를 액세스한다.
③ 다음 로우를 차례로 스캔 => COL1이 'A'가 아니거나 COL2가 115보다 클 때까지 액세스 => 그렇지 않으면 스캔 종료
위는 인덱스의 첫번째 컬럼이 '='이므로 COL2가 113과 115 사이에 있는 로우만 액세스
=> COL1 정렬 후 COL2 정렬
=> COL1이 '='로 상용된 범위 내에서는 반드시 COL2 정렬이 보장됨.
=> 115보다 큰 값을 만나면 결코 115보다 적은 값은 존재하지 않는다.
=> 스캔 종료
■ 우측 그림 수행
분포도가 좁지만 'BETWEEN'으로 사용된 COl2가 앞에 위치, 분포도는 넓지만 '='을 사용한 COL1이 뒤에 위치
① COL2 = 113 이고 COL1 = 'A' 인 첫번째 로우를 바로 찾는다.
② ROWID를 이용하여 테이블의 로우를 액세스한다.
③ COL2가 115보다 클때까지 스캔, 스캔한 로우는 COL1이 'A인지 체크, 맞으면 로우 액세스
④ COL2가 115보다 커지면 스캔 종료
위는 선행 컬럼인 COL2의 전체범위를 스캔. COL1은 처리 범위를 좁히지 못하고 체크 역할만 함
◆ 종합
인덱스 첫 번째 컬럼이 '='로 사용되지 않으면 뒤에 있는 컬럼이 '='을 사용하더라도 처리범위는 줄어들지 않는다.
=> 인덱스 컬럼 순서의 결정에는 분포도보다 '='이 더 우선적으로 감안되어야 한다.
다) IN 연산자를 이용한 징검다리 효과
■ 두개의 컬럼을 함께 사용하는 액세스 형태 조사해 보면
-
COL2는 '=' 사용, COL1은 '=' 사용하지 않음 => COL2+COL1 결합인덱스 생성
-
COL2는 LIKE 나 BETWEEN 사용, COL1은 ' =' 사용 => COL1+COL2 결합인덱스 생성
최소의 인덱스로 최대의 액세스 형태를 만족하는 결합인덱스 생성이 목적
■ 비효율적인 인덱스를 사용하면서도 비효율이 없도록 하는 방법
범위 연산을 IN 연산으로 변형
..
..
그림 1-4-5
■ 좌측 그림 설명
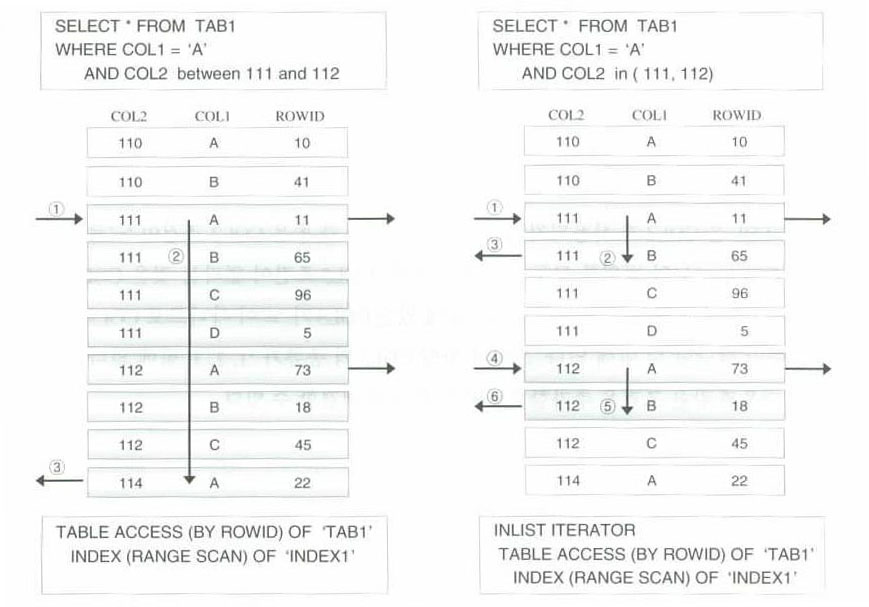
COL2가 'BETWEEN'으로 사용되어 COL1이 '='을 사용 했더라도 COL2의 범위를 모두 스캔
■ 우측 그림 설명 ( 'BETWEEN' 을 'IN' 으로 변경)
'INLIST ITERATOR' 수행 확인(IN절의 리스트 값만 인덱스를 탐침)
COL2와 COL1이 모두 '='을 가지게 된다.
라) 처리범위에 직접적인 영향을 주지 못하는 컬럼의 추가 기준
4.1.5. 결합 인덱스의 컬럼순서 결정 기준
-
결합 인덱스의 컬럼 순서를 결정하는 우선순위
-
1단계 : 항상 사용하는가?
-
2단계 : 항상 '='로 사용하는가?
-
3단계 : 어느 것이 더 좋은 분포도를 가지는가?
-
4단계 : 자주 정렬되는 순서는 무엇인가?
-
5단계 : 부가적으로 추가시킬 컬럼은 어떤 것으로 할 것인가?
댓글 2
-
노랑배
2010.11.24 07:56
-
실천하자
2010.11.24 18:58
분포도와 인덱스 관련 자료 링크입니다.
참조하시면 도움이 될것 같습니다. ^^
[링크] 결합 컬럼 인덱스와 단일 컬럼 인덱스
"값의 분포도가 좋다" 와
"분포도가 좋은 컬럼" 의 구분이 아직도 명확하진 않은듯..ㅠㅋ
분포도가 넓고 좁고의 의미 파악하기